Подавляющая часть нейронных сетей. Нейронные сети: какие бывают и как их используют бренды. Входные сигналы нейронных сетей
НЕЙРО́ННЫЕ СЕ́ТИ искусственные, многослойные высокопараллельные (т. е. с большим числом независимо параллельно работающих элементов) логические структуры, составленные из формальных нейронов. Начало теории нейронных сетей и нейрокомпьютеров положила работа американских нейрофизиологов У. Мак-Каллока и У. Питтса «Логическое исчисление идей, относящихся к нервной деятельности» (1943), в которой они предложили математическую модель биологического нейрона. Среди основополагающих работ следует выделить модель Д. Хэбба, который в 1949 г. предложил закон обучения, явившийся стартовой точкой для алгоритмов обучения искусственных нейронных сетей. На дальнейшее развитие теории нейронной сети существенное влияние оказала монография американского нейрофизиолога Ф. Розенблатта «Принципы нейродинамики», в которой он подробно описал схему перцептрона (устройства, моделирующего процесс восприятия информации человеческим мозгом). Его идеи получили развитие в научных работах многих авторов. В 1985–86 гг. теория нейронных сетей получила «технологический импульс», вызванный возможностью моделирования нейронных сетей на появившихся в то время доступных и высокопроизводительных персональных компьютерах . Теория нейронной сети продолжает достаточно активно развиваться в начале 21 века. По оценкам специалистов, в ближайшее время ожидается значительный технологический рост в области проектирования нейронных сетей и нейрокомпьютеров. За последние годы уже открыто немало новых возможностей нейронных сетей, а работы в данной области вносят существенный вклад в промышленность, науку и технологии, имеют большое экономическое значение.
Основные направления применения нейронных сетей
Потенциальными областями применения искусственных нейронных сетей являются те, где человеческий интеллект малоэффективен, а традиционные вычисления трудоёмки или физически неадекватны (т. е. не отражают или плохо отражают реальные физические процессы и объекты). Актуальность применения нейронных сетей (т. е. нейрокомпьютеров) многократно возрастает, когда появляется необходимость решения плохо формализованных зада ч. Основные области применения нейронных сетей: автоматизация процесса классификации, автоматизация прогнозирования, автоматизация процесса распознавания, автоматизация процесса принятия решений; управление, кодирование и декодирование информации; аппроксимация зависимостей и др.
С помощью нейронных сетей успешно решается важная задача в области телекоммуникаций – проектирование и оптимизация сетей связи (нахождение оптимального пути трафика между узлами). Кроме управления маршрутизацией потоков, нейронные сети используются для получения эффективных решений в области проектирования новых телекоммуникационных сетей.
Распознавание речи – одна из наиболее популярных областей применения нейронных сетей.
Ещё одна область – управление ценами и производством (потери от неоптимального планирования производства часто недооцениваются). Поскольку спрос и условия реализации продукции зависят от времени, сезона, курсов валют и многих других факторов, то и объём производства должен гибко варьироваться с целью оптимального использования ресурсов (нейросетевая система обнаруживает сложные зависимости между затратами на рекламу, объёмами продаж, ценой, ценами конкурентов, днём недели, сезоном и т. д.). В результате использования системы осуществляется выбор оптимальной стратегии производства с точки зрения максимизации объёма продаж или прибыли.
При анализе потребительского рынка (маркетинг), когда обычные (классические) методы прогнозирования отклика потребителей могут быть недостаточно точны, используется прогнозирующая нейросетевая система с адаптивной архитектурой нейросимулятора.
Исследование спроса позволяет сохранить бизнес компании в условиях конкуренции, т. е. поддерживать постоянный контакт с потребителями через «обратную связь». Крупные компании проводят опросы потребителей, позволяющие выяснить, какие факторы являются для них решающими при покупке данного товара или услуги, почему в некоторых случаях предпочтение отдаётся конкурентам и какие товары потребитель хотел бы увидеть в будущем. Анализ результатов такого опроса – достаточно сложная задача, так как существует большое число коррелированных параметров. Нейросетевая система позволяет выявлять сложные зависимости между факторами спроса, прогнозировать поведение потребителей при изменении маркетинговой политики, находить наиболее значимые факторы и оптимальные стратегии рекламы, а также очерчивать сегмент потребителей, наиболее перспективный для данного товара.
В медицинской диагностике нейронные сети применяются, например, для диагностики слуха у грудных детей. Система объективной диагностики обрабатывает зарегистрированные «вызванные потенциалы» (отклики мозга), проявляющиеся в виде всплесков на электроэнцефалограмме, в ответ на звуковой раздражитель, синтезируемый в процессе обследования. Обычно для уверенной диагностики слуха ребёнка опытному эксперту-аудиологу необходимо провести до 2000 тестов, что занимает около часа. Система на основе нейронной сети способна с той же достоверностью определить уровень слуха уже по 200 наблюдениям в течение всего нескольких минут, причём без участия квалифицированного персонала.
Нейронные сети применяются также для прогнозирования краткосрочных и долгосрочных тенденций в различных областях (финансовой, экономической, банковской и др.).
Структура нейронных сетей
Нервная система и мозг человека состоят из нейронов, соединённых между собой нервными волокнами. Нервные волокна способны передавать электрические импульсы между нейронами. Все процессы передачи раздражений от нашей кожи, ушей и глаз к мозгу, процессы мышления и управления действиями – всё это реализовано в живом организме как передача электрических импульсов между нейронами.
Биологический нейрон (Cell) имеет ядро (Nucleus), а также отростки нервных волокон двух типов (рис. 1) – дендриты (Dendrites), по которым принимаются импульсы (Carries signals in), и единственный аксон (Axon), по которому нейрон может передавать импульс (Carries signals away). Аксон контактирует с дендритами других нейронов через специальные образования – синапсы (Synapses), которые влияют на силу передаваемого импульса. Структура, состоящая из совокупности большого количества таких нейронов, получила название биологической (или естественной) нейронной сети.
Появление формального нейрона во многом обусловлено изучением биологических нейронов. Формальный нейрон (далее – нейрон) является основой любой искусственной нейронной сети. Нейроны представляют собой относительно простые, однотипные элементы, имитирующие работу нейронов мозга. Каждый нейрон характеризуется своим текущим состоянием по аналогии с нервными клетками головного мозга, которые могут быть возбуждены и заторможены. Искусственный нейрон, так же как и его естественный прототип, имеет группу синапсов (входов ), которые соединены с выходами других нейронов, а также аксон – выходную связь данного нейрона, откуда сигнал возбуждения или торможения поступает на синапсы других нейронов.
Формальный нейрон представляет собой логический элемент с $N$ входами, ($N+1$ ) весовыми коэффициентами, сумматором и нелинейным преобразователем. Простейший формальный нейрон, осуществляющий логическое преобразование $y = \text{sign}\sum_{i=0}^{N}a_ix_i$ входных сигналов (которыми, напр., являются выходные сигналы др. формальных нейронов Н. с.) в выходной сигнал, представлен на рис. 1.
Здесь $y$ – значение выхода формального нейрона; $a_i$ – весовые коэффициенты; $x_i$ – входные значения формального нейрона ($x_i∈\left \{0,1\right \},\; x_0=1$ ). Процесс вычисления выходного значения формального нейрона представляет собой движение потока данных и их преобразование. Сначала данные поступают на блок входа формального нейрона, где происходит умножение исходных данных на соответствующие весовые коэффициенты, т. н. синоптические веса (в соответствии с синапсами биологических нейронов). Весовой коэффициент является мерой, которая определяет, насколько соответствующее входное значение влияет на состояние формального нейрона. Весовые коэффициенты могут изменяться в соответствии с обучающими примерами, архитектурой Н. с., правилами обучения и др. Полученные (при умножении) значения преобразуются в сумматоре в одно числовое значение $g$ (посредством суммирования). Затем для определения выхода формального нейрона в блоке нелинейного преобразования (реализующего передаточную функцию) $g$ сравнивается с некоторым числом (порогом). Если сумма больше значения порога, формальный нейрон генерирует сигнал, в противном случае сигнал будет нулевым или тормозящим. В данном формальном нейроне применяется нелинейное преобразование$$\text{sign}(g)= \begin{cases} 0,\; g < 0 \\ 1,\; g ⩾ 0 \end{cases},\quad \text{где}\,\,g = \sum_{i=0}^N a_i x_i.$$
Выбор структуры нейронной сети осуществляется в соответствии с особенностями и сложностью задачи. Теоретически число слоёв и число нейронов в каждом слое нейронной сети может быть произвольным, однако фактически оно ограничено ресурсами компьютера или специализированной микросхемы, на которых обычно реализуется нейронная сеть. При этом если в качестве активационной функции для всех нейронов сети используется функция единичного скачка, нейронная сеть называется многослойным персептроно м.
На рис. 3 показана общая схема многослойной нейронной сети с последовательными связями. Высокий параллелизм обработки достигается путём объединения большого числа формальных нейронов в слои и соединения определённым образом различных нейронов между собой.
В общем случае в эту структуру могут быть введены перекрёстные и обратные связи с настраиваемыми весовыми коэффициентами (рис. 4).
Нейронные сети являются сложными нелинейными системами с огромным числом степеней свободы. Принцип, по которому они обрабатывают информацию, отличается от принципа, используемого в компьютерах на основе процессоров с фон-неймановской архитектурой – с логическим базисом И, ИЛИ, НЕ (см. Дж. фон Нейман , Вычислительная машина ). Вместо классического программирования (как в традиционных вычислительных системах) применяется обучение нейронной сети, которое сводится, как правило, к настройке весовых коэффициентов с целью оптимизации заданного критерия качества функционирования нейронной сети.
Нейросетевые алгоритмы
Нейросетевым алгоритмом решения задач называется вычислительная процедура, полностью или по большей части реализованная в виде нейронной сети той или иной структуры (например, многослойная нейронная сеть с последовательными или перекрёстными связями между слоями формальных нейронов) с соответствующим алгоритмом настройки весовых коэффициентов. Основой разработки нейросетевого алгоритма является системный подход, при котором процесс решения задачи представляется как функционирование во времени некоторой динамической системы. Для её построения необходимо определить: объект, выступающий в роли входного сигнала нейронной сети; объект, выступающий в роли выходного сигнала нейронной сети (например, непосредственно решение или некоторая его характеристика); желаемый (требуемый) выходной сигнал нейронной сети; структуру нейронной сети (число слоёв, связи между слоями, объекты, служащие весовыми коэффициентами); функцию ошибки системы (характеризующую отклонение желаемого выходного сигнала нейронной сети от реального выходного сигнала); критерий качества системы и функционал её оптимизации, зависящий от ошибки; значение весовых коэффициентов (например, определяемых аналитически непосредственно из постановки задачи, с помощью некоторых численных методов или процедуры настройки весовых коэффициентов нейронной сети).
Количество и тип формальных нейронов в слоях, а также число слоёв нейронов выбираются исходя из специфики решаемых задач и требуемого качества решения. Нейронная сеть в процессе настройки на решение конкретной задачи рассматривается как многомерная нелинейная система, которая в итерационном режиме целенаправленно ищет оптимум некоторого функционала, количественно определяющего качество решения поставленной задачи. Для нейронных сетей, как многомерных нелинейных объектов управления, формируются алгоритмы настройки множества весовых коэффициентов. Основные этапы исследования нейронной сети и построения алгоритмов настройки (адаптации) их весовых коэффициентов включают: исследование характеристик входного сигнала для различных режимов работы нейронной сети (входным сигналом нейронной сети является, как правило, входная обрабатываемая информация и указание так называемого «учител я» нейронной сети); выбор критериев оптимизации (при вероятностной модели внешнего мира такими критериями могут быть минимум средней функции риска, максимум апостериорной вероятности, в частности при наличии ограничений на отдельные составляющие средней функции риска); разработку алгоритма поиска экстремумов функционалов оптимизации (например, для реализации алгоритмов поиска локальных и глобального экстремумов); построение алгоритмов адаптации коэффициентов нейронной сети; анализ надёжности и методов диагностики нейронной сети и др.
Необходимо отметить, что введение обратных связей и, как следствие, разработка алгоритмов настройки их коэффициентов в 1960–80 годы имели чисто теоретический смысл, т. к. не было практических задач, адекватных таким структурам. Лишь в конце 1980-х – начале 1990-х годов стали появляться такие задачи и простейшие структуры с настраиваемыми обратными связями для их решения (так называемые рекуррентные нейронные сети). Разработчики в области нейросетевых технологий занимались не только созданием алгоритмов настройки многослойных нейронных сетей и нейросетевыми алгоритмами решения различных задач, но и наиболее эффективными (на текущий момент развития технологии электроники) аппаратными эмуляторами (особые программы, которые предназначены для запуска одной системы в оболочке другой) нейросетевых алгоритмов. В 1960-е годы, до появления микропроцессора, наиболее эффективными эмуляторами нейронных сетей были аналоговые реализации разомкнутых нейронных сетей с разработанными алгоритмами настройки на универсальных ЭВМ (иногда системы на адаптивных элементах с аналоговой памятью). Такой уровень развития электроники делал актуальным введение перекрёстных связей в структуры нейронных сетей. Это приводило к значительному уменьшению числа нейронов в нейронной сети при сохранении качества решения задачи (например, дискриминантной способности при решении задач распознавания образов). Исследования 1960–70-х годов в области оптимизации структур нейронных сетей с перекрёстными связями наверняка найдут развитие при реализации мемристорных нейронных систем [мемристор (memristor, от memory – память, и resistor – электрическое сопротивление), пассивный элемент в микроэлектронике, способный изменять своё сопротивление в зависимости от протекавшего через него заряда], с учётом их специфики в части аналого-цифровой обработки информации и весьма значительного количества настраиваемых коэффициентов. Специфические требования прикладных задач определяли некоторые особенности структур нейронных сетей с помощью алгоритмов настройки: континуум (от лат. continuum – непрерывное, сплошное) числа классов, когда указание «учителя» системы формируется в виде непрерывного значения функции в некотором диапазоне изменения; континуум решений многослойной нейронной сети, формируемый выбором континуальной функции активации нейрона последнего слоя; континуум числа признаков, формируемый переходом в пространстве признаков от представления выходного сигнала в виде $N$ -мерного вектора вещественных чисел к вещественной функции в некотором диапазоне изменения аргумента; континуум числа признаков, как следствие, требует специфической программной и аппаратной реализации нейронной сети; вариант континуума признаков входного пространства был реализован в задаче распознавания периодических сигналов без преобразования их с помощью аналого-цифрового преобразователя (АЦП) на входе системы, и реализацией аналого-цифровой многослойной нейронной сети; континуум числа нейронов в слое; реализация многослойных нейронных сетей с континуумом классов и решений проводится выбором соответствующих видов функций активации нейронов последнего слоя.
В таблице показан систематизированный набор вариантов алгоритмов настройки многослойных нейронных сетей в пространстве «Входной сигнал – пространство решений». Представлено множество вариантов характеристик входных и выходных сигналов нейронных сетей, для которых справедливы алгоритмы настройки коэффициентов, разработанных российской научной школой в 1960–70 годах. Сигнал на вход нейронной сети описывается количеством классов (градаций) образов, представляющих указания «учителя». Выходной сигнал нейронной сети представляет собой количественное описание пространства решений. В таблице дана классификация вариантов функционирования нейронных сетей для различных видов входного сигнала (2 класса, $K$ классов, континуум классов) и различных вариантов количественного описания пространства решений (2 решения, $K_p$ решений, континуум решений). Цифрами 1, 7, 8 представлены конкретные варианты функционирования нейронных сетей.
Таблица. Набор вариантов алгоритмов настройки
| Пространство(число) решений | Входной сигнал |
||||
| 2 класса | $K$ классов | Континуум классов | |||
| 2 | 1 | 7 | 8 | ||
| $K_p$ | $K_p=3$ | 3а | $K\lt K_p$ | 9 | 10 |
| $K = K_p$ | 2 | ||||
| $K_p =\text{const}$ | 3б | $K\gt K_p$ | 4 | ||
| Континуум | 5 | 6 | 11 | ||
Основными преимуществами нейронных сетей как логического базиса алгоритмов решения сложных задач являются: инвариантность (неизменность, независимость) методов синтеза нейронных сетей от размерности пространства признаков; возможность выбора структуры нейронных сетей в значительном диапазоне параметров в зависимости от сложности и специфики решаемой задачи с целью достижения требуемого качества решения; адекватность текущим и перспективным технологиям микроэлектроники; отказоустойчивость в смысле его небольшого, а не катастрофического изменения качества решения задачи в зависимости от числа вышедших из строя элементов.
Нейронные сети – частный вид объекта управления в адаптивной системе
Нейронные сети явились в теории управления одним из первых примеров перехода от управления простейшими линейными стационарными системами к управлению сложными нелинейными, нестационарными, многомерными, многосвязными системами. Во второй половине 1960-х годов родилась методика синтеза нейронных сетей, которая развивалась и успешно применялась в течение последующих почти пятидесяти лет. Общая структура этой методики представлена на рис. 5.
Входные сигналы нейронных сетей
Вероятностная модель окружающего мира является основой нейросетевых технологий. Подобная модель – основа математической статистики. Нейронные сети возникли как раз в то время, когда экспериментаторы, использующие методы математической статистики, задали себе вопрос: «А почему мы обязаны описывать функции распределения входных случайных сигналов в виде конкретных аналитических выражений (нормальное распределение, распределение Пуассона и т. д.)? Если это правильно и на это есть какая-то физическая причина, то задача обработки случайных сигналов становится достаточно простой».
Специалисты по нейросетевым технологиям сказали: «Мы ничего не знаем о функции распределения входных сигналов, мы отказываемся от необходимости формального описания функции распределения входных сигналов, даже если сузим класс решаемых задач. Мы считаем функции распределения входных сигналов сложными, неизвестными и будем решать частные конкретные задачи в условиях подобной априорной неопределённости (т. е. неполноты описания; нет информации и о возможных результатах)». Именно поэтому нейронные сети в начале 1960-х годов эффективно применялись при решении задач распознавания образов. Причём задача распознавания образов трактовалась как задача аппроксимации многомерной случайной функции, принимающей $K$ значений, где $K$ – число классов образов.
Ниже отмечены некоторые режимы работы многослойных нейронных сетей, определяемые характеристиками случайных входных сигналов, для которых ещё в конце 1960-х годов были разработаны алгоритмы настройки коэффициентов.
Обучение нейронных сетей
Очевидно, что функционирование нейронной сети, т. е. действия, которые она способна выполнять, зависит от величин синоптических связей. Поэтому, задавшись структурой нейронной сети, отвечающей определённой задаче, разработчик должен найти оптимальные значения для всех весовых коэффициентов $w$ . Этот этап называется обучением нейронной сети, и от того, насколько качественно он будет выполнен, зависит способность сети решать во время эксплуатации поставленные перед ней проблемы. Важнейшими параметрами обучения являются: качество подбора весовых коэффициентов и время, которое необходимо затратить на обучение. Как правило, два этих параметра связаны между собой обратной зависимостью и их приходится выбирать на основе компромисса. В настоящее время все алгоритмы обучения нейронных сетей можно разделить на два больших класса: «с учителем» и «без учителя».
Априорные вероятности появления классов
При всей недостаточности априорной информации о функциях распределения входных сигналов игнорирование некоторой полезной информации может привести к потере качества решения задачи. Это в первую очередь касается априорных вероятностей появления классов. Были разработаны алгоритмы настройки многослойных нейронных сетей с учётом имеющейся информации об априорных вероятностях появления классов. Это имеет место в таких задачах, как распознавание букв в тексте, когда для данного языка вероятность появления каждой буквы известна и эту информацию необходимо использовать при построении алгоритма настройки коэффициентов многослойной нейронной сети.
Квалификация «учителя»
Нейронной сети предъявляются значения как входных, так и выходных параметров, и она по некоторому внутреннему алгоритму подстраивает веса своих синаптических связей. Обучение «с учителем» предполагает, что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход. В общем случае квалификация «учителя» может быть различной для различных классов образов. Вместе они называются представительской или обучающей выборко й. Обычно нейронная сеть обучается на некотором числе таких выборок. Предъявляется выходной вектор, вычисляется выход нейронной сети и сравнивается с соответствующим целевым вектором, разность (ошибка) с помощью обратной связи подаётся в нейронную сеть, и веса изменяются в соответствии с алгоритмом, стремящимся минимизировать ошибку. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
В задачах распознавания образов, как правило, по умолчанию квалификация «учителя» является полной, т.е. вероятность правильного отнесения «учителем» образов к тому или иному классу равна единице. На практике при наличии косвенных измерений это зачастую не соответствует действительности, например в задачах медицинской диагностики, когда при верификации (проверке) архива медицинских данных, предназначенных для обучения, вероятность отнесения этих данных к тому или иному заболеванию не равна единице. Введение понятия квалификации «учителя» позволило разработать единые алгоритмы настройки коэффициентов многослойных нейронных сетей для режимов обучения, обучения «с учителем», обладающим конечной квалификацией, и самообучения (кластеризации), когда при наличии $K$ или двух классов образов квалификация «учителя» (вероятность отнесения образов к тому или иному классу) равна $\frac {1} {K}$ или 1 / 2 . Введение понятия квалификации «учителя» в системах распознавания образов позволило чисто теоретически рассмотреть режимы «вредительства» системе, когда ей сообщается заведомо ложное (с различной степенью ложности) отнесение образов к тому или иному классу. Данный режим настройки коэффициентов многослойной нейронной сети пока не нашёл практического применения.
Кластеризация
Кластеризация (самообучение, обучение «без учителя») – это частный режим работы многослойных нейронных сетей, когда системе не сообщается информация о принадлежности образцов к тому или иному классу. Нейронной сети предъявляются только входные сигналы, а выходы сети формируются самостоятельно с учётом только входных и производных от них сигналов. Несмотря на многочисленные прикладные достижения, обучение «с учителем» критиковалось за биологическую неправдоподобность. Трудно вообразить обучающий механизм в естественном человеческом интеллекте, который сравнивал бы желаемые и действительные значения выходов, выполняя коррекцию с помощью обратной связи. Если допустить подобный механизм в человеческом мозге, то откуда тогда возникают желаемые выходы? Обучение «без учителя» является более правдоподобной моделью обучения в биологической системе. Она не нуждается в целевом векторе для выходов и, следовательно, не требует сравнения с предопределёнными идеальными ответами. Обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса нейронной сети так, чтобы получались согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определённый выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьёзной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью.
Кластеризации посвящено множество научных работ. Основная задача кластеризации заключается в обработке множества векторов в многомерном пространстве признаков с выделением компактных подмножеств (подмножеств, близко расположенных друг к другу), их количества и свойств. Наиболее распространённым методом кластеризации является метод «$K$ -means», практически не связанный с методами обратного распространения и не обобщаемый на архитектуры типа многослойных нейронных сетей.
Введение понятия квалификации «учителя» и единого подхода к обучению и самообучению в 1960-е годы позволило фактически создать основу для реализации режима кластеризации в многослойных нейронных сетях широкого класса структур.
Нестационарные образы
Существующие разработки в области систем распознавания образов на базе многослойных нейронных сетей в основном относятся к стационарным образам, т.е. к случайным входным сигналам, имеющим сложные неизвестные, но стационарные во времени функции распределения. В некоторых работах была сделана попытка распространить предлагаемую методику настройки многослойных нейронных сетей на нестационарные образы, когда предполагаемая неизвестная функции распределения входного сигнала зависит от времени или входной случайный сигнал является суперпозицией регулярной составляющей и случайной составляющей с неизвестной сложной функцией распределения, не зависящей от времени.
О критериях первичной оптимизации в многослойных нейронных сетях
Вероятностная модель мира, взятая за основу при построении алгоритмов адаптации в многослойных нейронных сетях, позволила формировать критерий первичной оптимизации в рассматриваемых системах в виде требований минимума средней функции риска и его модификаций: максимум апостериорной вероятности (условная вероятность случайного события при условии того, что известны апостериорные, т. е. основанные на опыте, данные); минимум средней функции риска; минимум средней функции риска при условии равенства условных функций риска для различных классов; минимум средней функции риска при условии заданного значения условной функции риска для одного из классов; другие критерии первичной оптимизации, вытекающие из требований конкретной практической задачи. В работах российских учёных были представлены модификации алгоритмов настройки многослойных нейронных сетей для указанных выше критериев первичной оптимизации. Отметим, что в подавляющем большинстве работ в области теории нейронных сетей и в алгоритмах обратного распространения рассматривается простейший критерий – минимум среднеквадратической ошибки, без каких бы то ни было ограничений на условные функции риска.
В режиме самообучения (кластеризации) предпосылкой формирования критерия и функционала первичной оптимизации нейронных сетей служит представление функции распределения входного сигнала в виде многомодальной функции в многомерном пространстве признаков, где каждой моде с некоторой вероятностью соответствует класс. В качестве критериев первичной оптимизации в режиме самообучения использовались модификации средней функции риска.
Представленные модификации критериев первичной оптимизации были обобщены на случаи континуума классов и решений; континуума признаков входного пространства; континуума числа нейронов в слое; при произвольной квалификации учителя. Важным разделом формирования критерия и функционала первичной оптимизации в многослойных нейронных сетях при вероятностной модели мира является выбор матрицы потерь, которая в теории статистических решений определяет коэффициент потерь $L_{12}$ при ошибочном отнесении образов 1-го класса ко 2-му и коэффициент потерь $L_{21}$ при отнесении образов 2-го класса к 1-му. Как правило, по умолчанию матрица $L$ этих коэффициентов при синтезе алгоритмов настройки многослойных нейронных сетей, в том числе и при применении метода обратного распространения, принимается симметричной. На практике это не соответствует действительности. Характерным примером является система обнаружения мин с применением геолокатора. В этом случае потери при ошибочном отнесении камня к мине равнозначны некоторой небольшой потере времени пользователем геолокатора. Потери, связанные с ошибочным отнесением мины к классу камней, связаны с жизнью или значительной потерей здоровья пользователями геолокатора.
Анализ разомкнутых нейронных сетей
Данный этап синтеза ставит своей целью определение в общем виде статистических характеристик выходных и промежуточных сигналов нейронных сетей как многомерных, нелинейных объектов управления с целью дальнейшего формирования критерия и функционала вторичной оптимизации, т. е. функционала, реально оптимизируемого алгоритмом адаптации в конкретной нейронной сети. В подавляющем большинстве работ в качестве такого функционала принимается среднеквадратическая ошибка, что ухудшает качество решения или вообще не соответствует задаче оптимизации, поставленной критерием первичной оптимизации.
Разработаны методика и алгоритмы формирования функционала вторичной оптимизации, соответствующего заданному функционалу первичной оптимизации.
Алгоритмы поиска экстремума функционалов вторичной оптимизации
Алгоритм поиска экстремума применительно к конкретному функционалу вторичной оптимизации определяет алгоритм настройки коэффициентов многослойной нейронной сети. В начале 21 века наибольший практический интерес представляют подобные алгоритмы, реализованные в системе MatLab (сокращение от англ. «Matrix Laboratory» – пакет прикладных программ для решения задач технических вычислений и одноимённый язык программирования). Однако необходимо отметить частность алгоритмов адаптации в многослойных нейронных сетях, используемых в системах MatLab (Neural Network Toolbox – предоставляет функции и приложения для моделирования сложных нелинейных систем, которые описываются уравнениями; поддерживает обучение «с учителем» и «без учителя», прямым распространением, с радиальными базисными функциями и др.), и ориентацию этих алгоритмов не на специфику решаемых задач, а на воображаемую «геометрию» функционалов вторичной оптимизации. Эти алгоритмы не учитывают многих деталей специфики применения многослойных нейронных сетей при решении конкретных задач и, естественно, требуют коренной, если не принципиальной, переработки при переходе к мемристорным нейронным системам. Был проведён детальный сравнительный анализ метода обратного распространения и российских методов 1960–70-х годов. Основная особенность данных алгоритмов заключается в необходимости поиска локальных и глобального экстремумов многоэкстремального функционала в многомерном пространстве настраиваемых коэффициентов нейронной сети. Рост размеров нейронной сети ведёт к значительному росту числа настраиваемых коэффициентов, т. е. к росту размерности пространства поиска. Ещё в 1960-х годах в работах предлагались поисковые и аналитические процедуры расчёта градиента функционала вторичной оптимизации, а в классе аналитических процедур предлагалось и исследовалось применение для организации поиска не только первой, но и второй производной функционала вторичной оптимизации. Специфика многоэкстремальности функционала вторичной оптимизации привела в течение последующих десятилетий к появлению различных модификаций методов поиска (генетические алгоритмы и т. п.). Созданы алгоритмы поиска экстремумов функционалов вторичной оптимизации с ограничениями на величину, скорость и другие параметры весовых коэффициентов нейронных сетей. Именно эти методы должны быть основой работ по методам настройки нейронных сетей с применением мемристоров (весовых коэффициентов) с учётом таких специфических характеристик, как передаточные функции.
Начальные условия при настройке коэффициентов
Выбор начальных условий итерационной процедуры поиска экстремумов функционалов вторичной оптимизации является важным этапом синтеза алгоритмов настройки многослойных нейронных сетей. Задача выбора начальных условий должна решаться специфически для каждой задачи, решаемой нейронной сетью, и быть неотъемлемой составляющей общей процедуры синтеза алгоритмов настройки многослойных нейронных сетей. Качественное решение этой задачи в значительной степени может сократить время настройки. Априорная сложность функционала вторичной оптимизации сделала необходимой введение процедуры выбора начальных условий в виде случайных значений коэффициентов с повторением этой процедуры и процедуры настройки коэффициентов. Эта процедура ещё в 1960-е годы казалась чрезвычайно избыточной с точки зрения времени, затрачиваемого на настройку коэффициентов. Однако, несмотря на это, она достаточно широко применяется и в настоящее время. Для отдельных задач тогда же была принята идея выбора начальных условий, специфических для данной решаемой задачи. Такая процедура была отработана для трёх задач: распознавание образов; кластеризация; нейроидентификация нелинейных динамических объектов.
Память в контуре настройки коэффициентов
Системный подход к построению алгоритмов поиска экстремума функционала вторичной оптимизации предполагает в качестве одного из режимов настройки перенастройку коэффициентов в каждом такте поступления образов на входе по текущему значению градиента функционала вторичной оптимизации. Разработаны алгоритмы настройки многослойных нейронных сетей с фильтрацией последовательности значений градиентов функционала вторичной оптимизации: фильтром нулевого порядка с памятью $m_n$ (для стационарных образов); фильтром $1, …, k$ -го порядка с памятью $m_n$ (для нестационарных образов) с различной гипотезой изменения во времени функций распределения для образов различных классов.
Исследование алгоритмов адаптации в нейронных сетях
Главный вопрос – как выбрать структуру многослойной нейронной сети для решения выбранной конкретной задачи – до сих пор в значительной степени не решён. Можно предложить лишь разумный направленный перебор вариантов структур с оценкой их эффективности в процессе решения задачи. Однако оценка качества работы алгоритма настройки на конкретной выбранной структуре, конкретной задаче может быть недостаточно корректной. Так, для оценки качества работы линейных динамических систем управления применяются типовые входные сигналы (ступенчатый, квадратичный и т. д.), по реакции на которые оцениваются установившаяся ошибка (астатизм системы) и ошибки в переходных процессах.
Подобно этому, для многослойных нейронных сетей были разработаны типовые входные сигналы для проверки и сравнения работоспособности различных алгоритмов настройки. Естественно, что типовые входные сигналы для таких объектов, как многослойные нейронные сети, являются специфическими для каждой решаемой задачи. В первую очередь были разработаны типовые входные сигналы для следующих задач: распознавание образов; кластеризация; нейроуправление динамическими объектами.
Основным аксиоматическим принципом применения нейросетевых технологий вместо методов классической математической статистики является отказ от формализованного описания функций распределения вероятностей для входных сигналов и принятие концепции неизвестных, сложных функций распределения. Именно по этой причине были предложены следующие типовые входные сигналы.
Для задачи кластеризации была предложена выборка случайного сигнала с многомодальным распределением, реализуемая в $N$ -мерном пространстве признаков с модами функции распределения, центры которых в количестве $Z$ размещаются на гипербиссектрисе $N$ -мерного пространства признаков. Каждая мода реализует составляющую случайной выборки с нормальным распределением и среднеквадратичным отклонением $σ$ , равным для каждой из $Z$ мод. Предметом сравнения различных методов кластеризации будет динамика настройки и качество решения задачи в зависимости от $N$ , $Z$ и $σ$ , при достаточно большой случайной выборке $M$ . Этот подход можно считать одним из первых достаточно объективных подходов к сравнению алгоритмов кластеризации, в том числе основанных на многослойных нейронных сетях c соответствующим выбором структуры для достижения необходимого качества кластеризации. Для задач классификации входные сигналы для испытаний аналогичны сигналам для кластеризации с тем изменением, что выборка с многомодальным распределением делится надвое (в случае двух классов) или на $K$ (в случае $K$ классов) частей с перемежающимися модами функции распределения для отдельных классов.
Нейронные сети с переменной структурой
Отказ в нейросетевых технологиях от априорной информации, от информации о функциях распределения входных сигналов приводит к необходимости реализации разумного перебора параметров структуры многослойных нейронных сетей для обеспечения необходимого качества решения задачи.
В 1960-е годы для весьма актуального в то время класса задач – распознавания образов – была предложена процедура настройки многослойных нейронных сетей, в которой структура априори не фиксируется, а является результатом настройки наряду со значениями настраиваемых коэффициентов. При этом в процессе настройки выбираются число слоёв и число нейронов в слоях. Процедура настройки коэффициентов многослойной нейронной сети с переменной структурой легко переносится с задачи распознавания двух классов образов на задачу распознавания $K$ классов образов. Причём здесь результатом настройки являются $K$ нейронных сетей, в каждой из которых первым классом является $k$ -й класс ($k = 1, \ldots, K$ ), а вторым все остальные. Подобная идея настройки многослойных нейронных сетей с переменной структурой применима и к решению задачи кластеризации. При этом в качестве первого класса образов принимается исходная анализируемая выборка, а в качестве второго класса – выборка с равномерным распределением в диапазоне изменения признаков. Реализуемая в процессе настройки многослойная нейронная сеть с переменной структурой качественно и количественно отражает сложность решения задачи. С этой точки зрения задача кластеризации как задача рождения новых знаний об изучаемом объекте заключается в выделении и анализе тех областей многомерного пространства признаков, в которых функция распределения вероятностей превышает уровень равномерного распределения в диапазоне изменения величин признаков.
Перспективы развития
В начале 21 века одной из основных концепций развития (обучения) многослойной нейронной сети является стремление к увеличению числа слоёв, а это предполагает обеспечение выбора структуры нейронной сети, адекватной решаемой задаче, разработку новых методов для формирования алгоритмов настройки коэффициентов. Достоинствами нейронных сетей являются: свойство т.н. постепенной деградации − при выходе из строя отдельных элементов качество работы системы падает постепенно (для сравнения, логические сети из элементов И, ИЛИ, НЕ выходят из строя при нарушении работы любого элемента сети); повышенная устойчивость к изменению параметров схем, их реализующих (например, весьма значительные изменения весов не приводят к ошибкам в реализации простой логической функции двух переменных) и др.
Широкое распространение нейросетевых алгоритмов в области сложных формализуемых, слабоформализуемых и неформализуемых задач привело к созданию нового направления в вычислительной математике – нейроматематики . Нейроматематика включает нейросетевые алгоритмы решения следующих задач: распознавание образов; оптимизация и экстраполяция функций; теории графов; криптографические задачи; решение вещественных и булевских систем линейных и нелинейных уравнений, обыкновенных одномерных и многомерных дифференциальных уравнений, дифференциальных уравнений в частных производных и др. На основе теории нейронных сетей создан новый раздел современной теории управления сложными нелинейными и многомерными, многосвязными динамическими системами – нейроуправление , включающий методы нейросетевой идентификации сложных динамических объектов; построение нейрорегуляторов в контурах управления сложными динамическими объектами и др.
Решение задачи классификации является одним из важнейших применений нейронных сетей.
Задача классификации представляет собой задачу отнесения образца к одному из нескольких попарно не пересекающихся множеств. Примером таких задач может быть, например, задача определения кредитоспособности клиента банка, медицинские задачи, в которых необходимо определить, например, исход заболевания, решение задач управления портфелем ценных бумаг (продать купить или "придержать" акции в зависимости от ситуации на рынке), задача определения жизнеспособных и склонных к банкротству фирм.
Цель классификации
При решении задач классификации необходимо отнести имеющиеся статические образцы (характеристики ситуации на рынке, данные медосмотра, информация о клиенте) к определенным классам. Возможно несколько способов представления данных. Наиболее распространенным является способ, при котором образец представляется вектором. Компоненты этого вектора представляют собой различные характеристики образца, которые влияют на принятие решения о том, к какому классу можно отнести данный образец. Например, для медицинских задач в качестве компонентов этого вектора могут быть данные из медицинской карты больного. Таким образом, на основании некоторой информации о примере, необходимо определить, к какому классу его можно отнести. Классификатор таким образом относит объект к одному из классов в соответствии с определенным разбиением N-мерного пространства, которое называется пространством входов, и размерность этого пространства является количеством компонент вектора.
Прежде всего, нужно определить уровень сложности системы. В реальных задачах часто возникает ситуация, когда количество образцов ограничено, что осложняет определение сложности задачи. Возможно выделить три основных уровня сложности. Первый (самый простой) – когда классы можно разделить прямыми линиями (или гиперплоскостями, если пространство входов имеет размерность больше двух) – так называемая линейная разделимость . Во втором случае классы невозможно разделить линиями (плоскостями), но их возможно отделить с помощью более сложного деления – нелинейная разделимость . В третьем случае классы пересекаются и можно говорить только о вероятностной разделимости .
В идеальном варианте после предварительной обработки мы должны получить линейно разделимую задачу, так как после этого значительно упрощается построение классификатора. К сожалению, при решении реальных задач мы имеем ограниченное количество образцов, на основании которых и производится построение классификатора. При этом мы не можем провести такую предобработку данных, при которой будет достигнута линейная разделимость образцов.
Использование нейронных сетей в качестве классификатора
Сети с прямой связью являются универсальным средством аппроксимации функций, что позволяет их использовать в решении задач классификации. Как правило, нейронные сети оказываются наиболее эффективным способом классификации, потому что генерируют фактически большое число регрессионных моделей (которые используются в решении задач классификации статистическими методами).
К сожалению, в применении нейронных сетей в практических задачах возникает ряд проблем. Во-первых, заранее не известно, какой сложности (размера) может потребоваться сеть для достаточно точной реализации отображения. Эта сложность может оказаться чрезмерно высокой, что потребует сложной архитектуры сетей. Так Минский в своей работе "Персептроны" доказал, что простейшие однослойные нейронные сети способны решать только линейно разделимые задачи. Это ограничение преодолимо при использовании многослойных нейронных сетей. В общем виде можно сказать, что в сети с одним скрытым слоем вектор, соответствующий входному образцу, преобразуется скрытым слоем в некоторое новое пространство, которое может иметь другую размерность, а затем гиперплоскости, соответствующие нейронам выходного слоя, разделяют его на классы. Таким образом сеть распознает не только характеристики исходных данных, но и "характеристики характеристик", сформированные скрытым слоем.
Подготовка исходных данных
Для построения классификатора необходимо определить, какие параметры влияют на принятие решения о том, к какому классу принадлежит образец. При этом могут возникнуть две проблемы. Во-первых, если количество параметров мало, то может возникнуть ситуация, при которой один и тот же набор исходных данных соответствует примерам, находящимся в разных классах. Тогда невозможно обучить нейронную сеть, и система не будет корректно работать (невозможно найти минимум, который соответствует такому набору исходных данных). Исходные данные обязательно должны быть непротиворечивы . Для решения этой проблемы необходимо увеличить размерность пространства признаков (количество компонент входного вектора, соответствующего образцу). Но при увеличении размерности пространства признаков может возникнуть ситуация, когда число примеров может стать недостаточным для обучения сети, и она вместо обобщения просто запомнит примеры из обучающей выборки и не сможет корректно функционировать. Таким образом, при определении признаков необходимо найти компромисс с их количеством.
Далее необходимо определить способ представления входных данных для нейронной сети, т.е. определить способ нормирования. Нормировка необходима, поскольку нейронные сети работают с данными, представленными числами в диапазоне 0..1, а исходные данные могут иметь произвольный диапазон или вообще быть нечисловыми данными. При этом возможны различные способы, начиная от простого линейного преобразования в требуемый диапазон и заканчивая многомерным анализом параметров и нелинейной нормировкой в зависимости от влияния параметров друг на друга.
Кодирование выходных значений
Задача классификации при наличии двух классов может быть решена на сети с одним нейроном в выходном слое, который может принимать одно из двух значений 0 или 1, в зависимости от того, к какому классу принадлежит образец. При наличии нескольких классов возникает проблема, связанная с представлением этих данных для выхода сети. Наиболее простым способом представления выходных данных в таком случае является вектор, компоненты которого соответствуют различным номерам классов. При этом i-я компонента вектора соответствует i-му классу. Все остальные компоненты при этом устанавливаются в 0. Тогда, например, второму классу будет соответствовать 1 на 2 выходе сети и 0 на остальных. При интерпретации результата обычно считается, что номер класса определяется номером выхода сети, на котором появилось максимальное значение. Например, если в сети с тремя выходами мы имеем вектор выходных значений (0.2,0.6,0.4), то мы видим, что максимальное значение имеет вторая компонента вектора, значит класс, к которому относится этот пример, – 2. При таком способе кодирования иногда вводится также понятие уверенности сети в том, что пример относится к этому классу. Наиболее простой способ определения уверенности заключается в определении разности между максимальным значением выхода и значением другого выхода, которое является ближайшим к максимальному. Например, для рассмотренного выше примера уверенность сети в том, что пример относится ко второму классу, определится как разность между второй и третьей компонентой вектора и равна 0.6-0.4=0.2. Соответственно чем выше уверенность, тем больше вероятность того, что сеть дала правильный ответ. Этот метод кодирования является самым простым, но не всегда самым оптимальным способом представления данных.
Известны и другие способы. Например, выходной вектор представляет собой номер кластера, записанный в двоичной форме. Тогда при наличии 8 классов нам потребуется вектор из 3 элементов, и, скажем, 3 классу будет соответствовать вектор 011. Но при этом в случае получения неверного значения на одном из выходов мы можем получить неверную классификацию (неверный номер кластера), поэтому имеет смысл увеличить расстояние между двумя кластерами за счет использования кодирования выхода по коду Хемминга, который повысит надежность классификации.
Другой подход состоит в разбиении задачи с k классами на k*(k-1)/2 подзадач с двумя классами (2 на 2 кодирование) каждая. Под подзадачей в данном случае понимается то, что сеть определяет наличие одной из компонент вектора. Т.е. исходный вектор разбивается на группы по два компонента в каждой таким образом, чтобы в них вошли все возможные комбинации компонент выходного вектора. Число этих групп можно определить как количество неупорядоченных выборок по два из исходных компонент. Из комбинаторики
$A_k^n = \frac{k!}{n!\,(k\,-\,n)!} = \frac{k!}{2!\,(k\,-\,2)!} = \frac{k\,(k\,-\,1)}{2}$
Тогда, например, для задачи с четырьмя классами мы имеем 6 выходов (подзадач) распределенных следующим образом:
| N подзадачи(выхода) | КомпонентыВыхода |
|---|---|
| 1 | 1-2 |
| 2 | 1-3 |
| 3 | 1-4 |
| 4 | 2-3 |
| 5 | 2-4 |
| 6 | 3-4 |
Где 1 на выходе говорит о наличии одной из компонент. Тогда мы можем перейти к номеру класса по результату расчета сетью следующим образом: определяем, какие комбинации получили единичное (точнее близкое к единице) значение выхода (т.е. какие подзадачи у нас активировались), и считаем, что номер класса будет тот, который вошел в наибольшее количество активированных подзадач (см. таблицу).
Это кодирование во многих задачах дает лучший результат, чем классический способ кодирование.
Выбор объема сети
Правильный выбор объема сети имеет большое значение. Построить небольшую и качественную модель часто бывает просто невозможно, а большая модель будет просто запоминать примеры из обучающей выборки и не производить аппроксимацию, что, естественно, приведет к некорректной работе классификатора. Существуют два основных подхода к построению сети – конструктивный и деструктивный. При первом из них вначале берется сеть минимального размера, и постепенно увеличивают ее до достижения требуемой точности. При этом на каждом шаге ее заново обучают. Также существует так называемый метод каскадной корреляции, при котором после окончания эпохи происходит корректировка архитектуры сети с целью минимизации ошибки. При деструктивном подходе вначале берется сеть завышенного объема, и затем из нее удаляются узлы и связи, мало влияющие на решение. При этом полезно помнить следующее правило: число примеров в обучающем множестве должно быть больше числа настраиваемых весов . Иначе вместо обобщения сеть просто запомнит данные и утратит способность к классификации – результат будет неопределен для примеров, которые не вошли в обучающую выборку.
Выбор архитектуры сети
При выборе архитектуры сети обычно опробуется несколько конфигураций с различным количеством элементов. При этом основным показателем является объем обучающего множества и обобщающая способность сети. Обычно используется алгоритм обучения Back Propagation (обратного распространения) с подтверждающим множеством.
Алгоритм построения классификатора на основе нейронных сетей
- Работа с данными
- Составить базу данных из примеров, характерных для данной задачи
- Разбить всю совокупность данных на два множества: обучающее и тестовое (возможно разбиение на 3 множества: обучающее, тестовое и подтверждающее).
- Предварительная обработка
- Выбрать систему признаков, характерных для данной задачи, и преобразовать данные соответствующим образом для подачи на вход сети (нормировка, стандартизация и т.д.). В результате желательно получить линейно отделяемое пространство множества образцов.
- Выбрать систему кодирования выходных значений (классическое кодирование, 2 на 2 кодирование и т.д.)
- Конструирование, обучение и оценка качества сети
- Выбрать топологию сети: количество слоев, число нейронов в слоях и т.д.
- Выбрать функцию активации нейронов (например "сигмоида")
- Выбрать алгоритм обучения сети
- Оценить качество работы сети на основе подтверждающего множества или другому критерию, оптимизировать архитектуру (уменьшение весов, прореживание пространства признаков)
- Остановится на варианте сети, который обеспечивает наилучшую способность к обобщению и оценить качество работы по тестовому множеству
- Использование и диагностика
- Выяснить степень влияния различных факторов на принимаемое решение (эвристический подход).
- Убедится, что сеть дает требуемую точность классификации (число неправильно распознанных примеров мало)
- При необходимости вернутся на этап 2, изменив способ представления образцов или изменив базу данных.
- Практически использовать сеть для решения задачи.
Для того, чтобы построить качественный классификатор, необходимо иметь качественные данные. Никакой из методов построения классификаторов, основанный на нейронных сетях или статистический, никогда не даст классификатор нужного качества, если имеющийся набор примеров не будет достаточно полным и представительным для той задачи, с которой придется работать системе.
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.Что такое нейронная сеть?

Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.Линейная функция
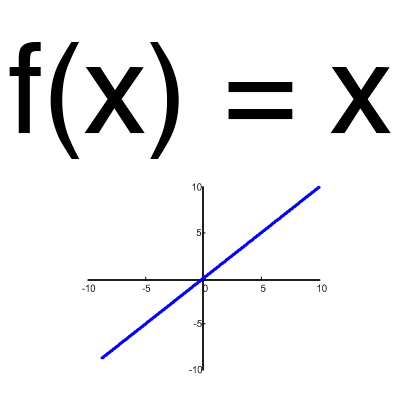
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.
Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.Новые виды архитектуры нейронных сетей появляются постоянно, и в них можно запутаться. Мы собрали для вас своеобразную шпаргалку, содержащую большую часть существующих видов ИНС. Хотя все они представлены как уникальные, картинки свидетельствуют о том, что многие из них очень похожи.
Проблема нарисованных выше графов заключается в том, что они не показывают, как соответствующие сети используются на практике. Например, вариационные автокодировщики (VAE) выглядят совсем как простые автокодировщики (AE), но их процессы обучения существенно различаются. Случаи использования отличаются ещё больше, поскольку VAE - это генератор, которому для получения нового образца подаётся новый шум. AE же просто сравнивает полученные данные с наиболее похожим образцом, полученным во время обучения.
Стоит заметить, что хотя большинство этих аббревиатур общеприняты, есть и исключения. Под RNN иногда подразумевают рекурсивную нейронную сеть, но обычно имеют в виду рекуррентную. Также можно часто встретить использование аббревиатуры RNN, когда речь идёт про любую рекуррентную НС. Автокодировщики также сталкиваются с этой проблемой, когда вариационные и шумоподавляющие автокодировщики (VAE, DAE) называют просто автокодировщиками (AE). Кроме того, во многих аббревиатурах различается количество букв «N» в конце, поскольку в каких-то случаях используется «neural network», а в каких-то - просто «network».
Для каждой архитектуры будет дано очень краткое описание и ссылка на статью, ей посвящённую. Если вы хотите быстро познакомиться с нейронными сетями с нуля, следуйте переведенному нами , состоящему всего из четырех шагов.
 Нейронные сети прямого распространения
(feed forward neural networks, FF или FFNN)
и перцептроны
(perceptrons, P)
очень прямолинейны, они передают информацию от входа к выходу. Нейронные сети часто описываются в виде слоёного торта, где каждый слой состоит из входных, скрытых или выходных клеток. Клетки одного слоя не связаны между собой, а соседние слои обычно полностью связаны. Самая простая нейронная сеть имеет две входных клетки и одну выходную, и может использоваться в качестве модели логических вентилей. FFNN обычно обучается по методу обратного распространения ошибки, в котором сеть получает множества входных и выходных данных. Этот процесс называется обучением с учителем, и он отличается от обучения без учителя тем, что во втором случае множество выходных данных сеть составляет самостоятельно. Вышеупомянутая ошибка является разницей между вводом и выводом. Если у сети есть достаточное количество скрытых нейронов, она теоретически способна смоделировать взаимодействие между входным и выходными данными. Практически такие сети используются редко, но их часто комбинируют с другими типами для получения новых.
Нейронные сети прямого распространения
(feed forward neural networks, FF или FFNN)
и перцептроны
(perceptrons, P)
очень прямолинейны, они передают информацию от входа к выходу. Нейронные сети часто описываются в виде слоёного торта, где каждый слой состоит из входных, скрытых или выходных клеток. Клетки одного слоя не связаны между собой, а соседние слои обычно полностью связаны. Самая простая нейронная сеть имеет две входных клетки и одну выходную, и может использоваться в качестве модели логических вентилей. FFNN обычно обучается по методу обратного распространения ошибки, в котором сеть получает множества входных и выходных данных. Этот процесс называется обучением с учителем, и он отличается от обучения без учителя тем, что во втором случае множество выходных данных сеть составляет самостоятельно. Вышеупомянутая ошибка является разницей между вводом и выводом. Если у сети есть достаточное количество скрытых нейронов, она теоретически способна смоделировать взаимодействие между входным и выходными данными. Практически такие сети используются редко, но их часто комбинируют с другими типами для получения новых.
 Сети радиально-базисных функций
(radial basis function, RBF)
- это FFNN, которая использует радиальные базисные функции как функции активации. Больше она ничем не выделяется 🙂
Сети радиально-базисных функций
(radial basis function, RBF)
- это FFNN, которая использует радиальные базисные функции как функции активации. Больше она ничем не выделяется 🙂
 Нейронная сеть Хопфилда
(Hopfield network, HN)
- это полносвязная нейронная сеть с симметричной матрицей связей. Во время получения входных данных каждый узел является входом, в процессе обучения он становится скрытым, а затем становится выходом. Сеть обучается так: значения нейронов устанавливаются в соответствии с желаемым шаблоном, после чего вычисляются веса, которые в дальнейшем не меняются. После того, как сеть обучилась на одном или нескольких шаблонах, она всегда будет сводиться к одному из них (но не всегда - к желаемому). Она стабилизируется в зависимости от общей «энергии» и «температуры» сети. У каждого нейрона есть свой порог активации, зависящий от температуры, при прохождении которого нейрон принимает одно из двух значений (обычно -1 или 1, иногда 0 или 1). Такая сеть часто называется сетью с ассоциативной памятью; как человек, видя половину таблицы, может представить вторую половину таблицы, так и эта сеть, получая таблицу, наполовину зашумленную, восстанавливает её до полной.
Нейронная сеть Хопфилда
(Hopfield network, HN)
- это полносвязная нейронная сеть с симметричной матрицей связей. Во время получения входных данных каждый узел является входом, в процессе обучения он становится скрытым, а затем становится выходом. Сеть обучается так: значения нейронов устанавливаются в соответствии с желаемым шаблоном, после чего вычисляются веса, которые в дальнейшем не меняются. После того, как сеть обучилась на одном или нескольких шаблонах, она всегда будет сводиться к одному из них (но не всегда - к желаемому). Она стабилизируется в зависимости от общей «энергии» и «температуры» сети. У каждого нейрона есть свой порог активации, зависящий от температуры, при прохождении которого нейрон принимает одно из двух значений (обычно -1 или 1, иногда 0 или 1). Такая сеть часто называется сетью с ассоциативной памятью; как человек, видя половину таблицы, может представить вторую половину таблицы, так и эта сеть, получая таблицу, наполовину зашумленную, восстанавливает её до полной.
 Цепи Маркова
(Markov chains, MC или discrete time Markov Chains, DTMC)
- это предшественники машин Больцмана (BM) и сетей Хопфилда (HN). Их смысл можно объяснить так: каковы мои шансы попасть в один из следующих узлов, если я нахожусь в данном? Каждое следующее состояние зависит только от предыдущего. Хотя на самом деле цепи Маркова не являются НС, они весьма похожи. Также цепи Маркова не обязательно полносвязны.
Цепи Маркова
(Markov chains, MC или discrete time Markov Chains, DTMC)
- это предшественники машин Больцмана (BM) и сетей Хопфилда (HN). Их смысл можно объяснить так: каковы мои шансы попасть в один из следующих узлов, если я нахожусь в данном? Каждое следующее состояние зависит только от предыдущего. Хотя на самом деле цепи Маркова не являются НС, они весьма похожи. Также цепи Маркова не обязательно полносвязны.
 Машина Больцмана
(Boltzmann machine, BM)
очень похожа на сеть Хопфилда, но в ней некоторые нейроны помечены как входные, а некоторые - как скрытые. Входные нейроны в дальнейшем становятся выходными. Машина Больцмана - это стохастическая сеть. Обучение проходит по методу обратного распространения ошибки или по алгоритму сравнительной расходимости. В целом процесс обучения очень похож на таковой у сети Хопфилда.
Машина Больцмана
(Boltzmann machine, BM)
очень похожа на сеть Хопфилда, но в ней некоторые нейроны помечены как входные, а некоторые - как скрытые. Входные нейроны в дальнейшем становятся выходными. Машина Больцмана - это стохастическая сеть. Обучение проходит по методу обратного распространения ошибки или по алгоритму сравнительной расходимости. В целом процесс обучения очень похож на таковой у сети Хопфилда.
 Ограниченная машина Больцмана
(restricted Boltzmann machine, RBM)
удивительно похожа на машину Больцмана и, следовательно, на сеть Хопфилда. Единственной разницей является её ограниченность. В ней нейроны одного типа не связаны между собой. Ограниченную машину Больцмана можно обучать как FFNN, но с одним нюансом: вместо прямой передачи данных и обратного распространения ошибки нужно передавать данные сперва в прямом направлении, затем в обратном. После этого проходит обучение по методу прямого и обратного распространения ошибки.
Ограниченная машина Больцмана
(restricted Boltzmann machine, RBM)
удивительно похожа на машину Больцмана и, следовательно, на сеть Хопфилда. Единственной разницей является её ограниченность. В ней нейроны одного типа не связаны между собой. Ограниченную машину Больцмана можно обучать как FFNN, но с одним нюансом: вместо прямой передачи данных и обратного распространения ошибки нужно передавать данные сперва в прямом направлении, затем в обратном. После этого проходит обучение по методу прямого и обратного распространения ошибки.
 Автокодировщик
(autoencoder, AE)
чем-то похож на FFNN, так как это скорее другой способ использования FFNN, нежели фундаментально другая архитектура. Основной идеей является автоматическое кодирование (в смысле сжатия, не шифрования) информации. Сама сеть по форме напоминает песочные часы, в ней скрытые слои меньше входного и выходного, причём она симметрична. Сеть можно обучить методом обратного распространения ошибки, подавая входные данные и задавая ошибку равной разнице между входом и выходом.
Автокодировщик
(autoencoder, AE)
чем-то похож на FFNN, так как это скорее другой способ использования FFNN, нежели фундаментально другая архитектура. Основной идеей является автоматическое кодирование (в смысле сжатия, не шифрования) информации. Сама сеть по форме напоминает песочные часы, в ней скрытые слои меньше входного и выходного, причём она симметрична. Сеть можно обучить методом обратного распространения ошибки, подавая входные данные и задавая ошибку равной разнице между входом и выходом.
 Разреженный автокодировщик
(sparse autoencoder, SAE)
- в каком-то смысле противоположность обычного. Вместо того, чтобы обучать сеть отображать информацию в меньшем «объёме» узлов, мы увеличиваем их количество. Вместо того, чтобы сужаться к центру, сеть там раздувается. Сети такого типа полезны для работы с большим количеством мелких свойств набора данных. Если обучать сеть как обычный автокодировщик, ничего полезного не выйдет. Поэтому кроме входных данных подаётся ещё и специальный фильтр разреженности, который пропускает только определённые ошибки.
Разреженный автокодировщик
(sparse autoencoder, SAE)
- в каком-то смысле противоположность обычного. Вместо того, чтобы обучать сеть отображать информацию в меньшем «объёме» узлов, мы увеличиваем их количество. Вместо того, чтобы сужаться к центру, сеть там раздувается. Сети такого типа полезны для работы с большим количеством мелких свойств набора данных. Если обучать сеть как обычный автокодировщик, ничего полезного не выйдет. Поэтому кроме входных данных подаётся ещё и специальный фильтр разреженности, который пропускает только определённые ошибки.
 Вариационные автокодировщики
(variational autoencoder, VAE)
обладают схожей с AE архитектурой, но обучают их иному: приближению вероятностного распределения входных образцов. В этом они берут начало от машин Больцмана. Тем не менее, они опираются на байесовскую математику, когда речь идёт о вероятностных выводах и независимости, которые интуитивно понятны, но сложны в реализации. Если обобщить, то можно сказать что эта сеть принимает в расчёт влияния нейронов. Если что-то одно происходит в одном месте, а что-то другое — в другом, то эти события не обязательно связаны, и это должно учитываться.
Вариационные автокодировщики
(variational autoencoder, VAE)
обладают схожей с AE архитектурой, но обучают их иному: приближению вероятностного распределения входных образцов. В этом они берут начало от машин Больцмана. Тем не менее, они опираются на байесовскую математику, когда речь идёт о вероятностных выводах и независимости, которые интуитивно понятны, но сложны в реализации. Если обобщить, то можно сказать что эта сеть принимает в расчёт влияния нейронов. Если что-то одно происходит в одном месте, а что-то другое — в другом, то эти события не обязательно связаны, и это должно учитываться.
 Шумоподавляющие автокодировщики
(denoising autoencoder, DAE)
- это AE, в которые входные данные подаются в зашумленном состоянии. Ошибку мы вычисляем так же, и выходные данные сравниваются с зашумленными. Благодаря этому сеть учится обращать внимание на более широкие свойства, поскольку маленькие могут изменяться вместе с шумом.
Шумоподавляющие автокодировщики
(denoising autoencoder, DAE)
- это AE, в которые входные данные подаются в зашумленном состоянии. Ошибку мы вычисляем так же, и выходные данные сравниваются с зашумленными. Благодаря этому сеть учится обращать внимание на более широкие свойства, поскольку маленькие могут изменяться вместе с шумом.
 Сеть типа «deep belief»
(deep belief networks, DBN)
- это название, которое получил тип архитектуры, в которой сеть состоит из нескольких соединённых RBM или VAE. Такие сети обучаются поблочно, причём каждому блоку требуется лишь уметь закодировать предыдущий. Такая техника называется «жадным обучением», которая заключается в выборе локальных оптимальных решений, не гарантирующих оптимальный конечный результат. Также сеть можно обучить (методом обратного распространения ошибки) отображать данные в виде вероятностной модели. Если использовать обучение без учителя, стабилизированную модель можно использовать для генерации новых данных.
Сеть типа «deep belief»
(deep belief networks, DBN)
- это название, которое получил тип архитектуры, в которой сеть состоит из нескольких соединённых RBM или VAE. Такие сети обучаются поблочно, причём каждому блоку требуется лишь уметь закодировать предыдущий. Такая техника называется «жадным обучением», которая заключается в выборе локальных оптимальных решений, не гарантирующих оптимальный конечный результат. Также сеть можно обучить (методом обратного распространения ошибки) отображать данные в виде вероятностной модели. Если использовать обучение без учителя, стабилизированную модель можно использовать для генерации новых данных.
 Свёрточные нейронные сети
(convolutional neural networks, CNN)
и глубинные свёрточные нейронные сети
(deep convolutional neural networks, DCNN)
сильно отличаются от других видов сетей. Обычно они используются для обработки изображений, реже для аудио. Типичным способом применения CNN является классификация изображений: если на изображении есть кошка, сеть выдаст «кошка», если есть собака - «собака». Такие сети обычно используют «сканер», не парсящий все данные за один раз. Например, если у вас есть изображение 200×200, вы не будете сразу обрабатывать все 40 тысяч пикселей. Вместо это сеть считает квадрат размера 20 x 20 (обычно из левого верхнего угла), затем сдвинется на 1 пиксель и считает новый квадрат, и т.д. Эти входные данные затем передаются через свёрточные слои, в которых не все узлы соединены между собой. Эти слои имеют свойство сжиматься с глубиной, причём часто используются степени двойки: 32, 16, 8, 4, 2, 1. На практике к концу CNN прикрепляют FFNN для дальнейшей обработки данных. Такие сети называются глубинными (DCNN).
Свёрточные нейронные сети
(convolutional neural networks, CNN)
и глубинные свёрточные нейронные сети
(deep convolutional neural networks, DCNN)
сильно отличаются от других видов сетей. Обычно они используются для обработки изображений, реже для аудио. Типичным способом применения CNN является классификация изображений: если на изображении есть кошка, сеть выдаст «кошка», если есть собака - «собака». Такие сети обычно используют «сканер», не парсящий все данные за один раз. Например, если у вас есть изображение 200×200, вы не будете сразу обрабатывать все 40 тысяч пикселей. Вместо это сеть считает квадрат размера 20 x 20 (обычно из левого верхнего угла), затем сдвинется на 1 пиксель и считает новый квадрат, и т.д. Эти входные данные затем передаются через свёрточные слои, в которых не все узлы соединены между собой. Эти слои имеют свойство сжиматься с глубиной, причём часто используются степени двойки: 32, 16, 8, 4, 2, 1. На практике к концу CNN прикрепляют FFNN для дальнейшей обработки данных. Такие сети называются глубинными (DCNN).
 Развёртывающие нейронные сети
(deconvolutional networks, DN)
, также называемые обратными графическими сетями, являются обратным к свёрточным нейронным сетям. Представьте, что вы передаёте сети слово «кошка», а она генерирует картинки с кошками, похожие на реальные изображения котов. DNN тоже можно объединять с FFNN. Стоит заметить, что в большинстве случаев сети передаётся не строка, а какой бинарный вектор: например, <0, 1> - это кошка, <1, 0> - собака, а <1, 1> - и кошка, и собака.
Развёртывающие нейронные сети
(deconvolutional networks, DN)
, также называемые обратными графическими сетями, являются обратным к свёрточным нейронным сетям. Представьте, что вы передаёте сети слово «кошка», а она генерирует картинки с кошками, похожие на реальные изображения котов. DNN тоже можно объединять с FFNN. Стоит заметить, что в большинстве случаев сети передаётся не строка, а какой бинарный вектор: например, <0, 1> - это кошка, <1, 0> - собака, а <1, 1> - и кошка, и собака.
Каково сейчас состояние искусственного интеллекта, нейросетей, машинного обучения? Почему в последние буквально год-полгода началось такое активное обсуждение, брожение умов и всякие разговоры о том, что мы все умрем?
Очень классный вопрос! Я как раз об этом много думал. Давайте я попробую ответить развернуто.
Когда я учился в институте, мы, например, анализировали тексты. Есть такая задачка: мы берем текст, смотрим какие-то слова-маркеры, частоту их встречаемости в тексте, и на основании количества и отношений этих слов-маркеров в тексте мы можем отнести этот текст, например, к научной литературе, к художественной или к переписке из Twitter.
Алгоритмы там были достаточно интересные. Одними из алгоритмов были нейронные сети. Такие простенькие персептроны, все четко. Нам говорили: “Ребята, нейронные сети – это классно, это романтично, это интересно. Скорее всего, за этим будущее, но это будущее достаточно далекое”. Это был 2010 год. Они проигрывали по всем фронтам другим алгоритмам анализа, которые более статистические. В основном за счет того, что они были неконтролируемы, у них куча ошибок, куча проблем по обучению.
Если переводить на человеческий язык, она может, например, попасть в зону комфорта или в локальный минимум, на математическом языке, и оттуда не выберется. Она говорит: “Мне так нравится. Я лучше не могу. Все. Пошли вон!”, хоть тряси, бей, мордуй ее. Из-за этого был достаточно большой пессимизм в отношении нейронных сетей. Пришли. Здорово. Вроде бы работает. Прикольненько. Наверно, за этим будущее. Мы пока не понимаем, что с этим делать.
Это уже была вторая итерация пессимизма. Первая была примерно в 80-х годах, когда их только открыли. По-моему, было правило обучения Хэбба. Они сделали примерно так, как обучается мозг, но только в очень примитивной модели нейронных сетей. Оно кое-как обучалось. Все: “Вау! Классно”. Но у этого правила (хебба) быстро вскрылось множество проблем, и в быту, как оказалось оно было не очень-то и применимым. Было много скепсиса, пессимизма, и на эти нейронные сети “забили” лет на 20, пока не придумали метод обучения, называемый “обратное распространения ошибки”.
Но в 1998-2003 году появилась интересная разработка. Называлась она “сверточная сеть”. Она долго лежала. Идея была простая – устроено, примерно, как в зрительной коре у человека. Идея простая. Мы берем огромное изображение, делим на маленькие квадратики и над каждым квадратиком проводим одну и ту же операцию. Мы не делаем нейрон, который связан, например, со всеми пикселями изображения. Он работает по маленьким квадратикам, причём на каждом из них одинаково. В итоге вычислительная нагрузка на нейронные сети упростилась. Обучать это дело стало проще. Точность повысилась. Самое главное – это все стало более-менее контролируемо.
И тут начались первые интересные заморочки у Гуглов и Яндексов. Причем стороны стали активно работать над этим примерно в 2013 году. Первое – распознавание котиков на YouTube.
Это сверточные нейронные сети. Они не такие страшные. Они работают даже понятнее, чем то, что я описал в статье. Нужно только немного разобраться. Например, относительно квадратика 10х10 пикселей один нейрон может сказать: “Здесь есть диагональ слева направо”. А второй нейрон будет говорить: “Здесь есть элемент диагонали справа налево”. Соответственно, диагоналями, горизонтальными, вертикальными линиями мы уже превращаем изображение из пиксельного почти в векторное. Ничего себе! Взяли и превратили, уже не в пикселях говорим, а в диагоналях. Классно! Естественно, она работала круче. Это, с одной стороны.
С другой стороны подоспел генетический алгоритм обучения. Проблема в следующем. Ты смотришь на сеть, ее точно можно заставить работать классно. Но как подобрать эти 5 миллиардов коэффициентов – почему-то неясно. Изначально пользовались чисто математическими алгоритмами, а потом “забили”, сказали: “Да ну! Черт с ним! Плевать на доказательства. Давайте хоть как-нибудь ее обучим”. Взяли, к примеру, генетический алгоритм.
На практике это означает, что мы что-то рандомно меняем, проверяем. Как в жизни. Что-то поменяли, что-то попробовали. О! Лучше. Давайте двигаться в этом направлении. Не получилось. Давайте другое. У этих двух есть хорошие черты, давайте их объединим. Как-то так – начали учить более стохастически, случайным образом. Начали получать очень даже неплохие результаты. Более того, эти результаты не так, как прежде, зависели от сложности архитектуры сетей.
Потом набежало множество очень умных людей, и появился термин “Deep Learning”. Это не только генетический алгоритм. Это целый Клондайк алгоритмов. Где-то они используют математику. Где-то они используют генетические алгоритм. Где-то они могут использоваться еще какой-то алгоритм. Все стало креативненько. Такие сети начали работать с распознаванием статических изображений. Вы, наверно, знаете эту историю. Взяли породы животных – изображения 122-х пород собак. С течением времени, к 2015 году, сеть стала определять породу животных (собак) по фотографии лучше собаководов.
Как это работало?
История была в том, что все выражали скепсис, говорили: “Обработка изображений – это только на людях”. Есть один сайт с обучающими выборками. Там было 122 породы собак – много фотографий на каждую породу. Показали это все в сеточке. Было соревнование. Лаборатории, которые делали алгоритмы (не нейронные сети, а алгоритмы распознавания изображений), давали 80% безошибочного распознавания. Это очень хороший показатель для любого распознавания. 80-86% – это хороший показатель распознавания.
Ребята, которые занимались только нейронными сетями, сначала (по-моему, в 2013 году) показали примерно 80%. В 2014 году они получили 87%, обогнали те лаборатории. А вот к 2015 году они показали 95%. Притом, что люди-собаководы распознают только 92%. Ты ей показал фрагмент изображения собаки, а она просто по положению шерсти (даже непонятно как, какие признаки она для себя выделила) уже знает, какая это порода. Более того, она говорит вероятность идентификации этих пород. Работает обычная сеть значительно стабильнее человека. Прежде всего, сразу немного испугались люди: “Ё-мое! Это означает, что можно заменять операторов на электроэнергетических подстанциях и во многих других местах”. Это первая технология, которая “взорвалась”. Она называется “сверточные сети”.
Вторые сети – LSTM. Они зародились примерно тогда же. Это рекуррентные сети. Проблема в следующем. В том, о чем я вам говорил, мы подаем статичную картинку: статичное слово, какой-то статичный набор чисел. Понимаете? Фотографию. Система говорит на выходе, к какому классу она относится. А если я, например, программирую движения робота, это уже интереснее. У меня есть что-то, что происходило в прошлом – какой-то временной ряд показаний датчиков. Например, у меня 20 датчиков, и это идет кадр за кадром. Например, раз в 20 миллисекунд мне приходит 20 показаний датчиков, нормированных от нуля до единицы.
Естественно, мне нужно учитывать предыдущий опыт для того чтобы генерировать какое-то управляющее воздействие или оценку ситуации, или что-то классифицировать. Первый вариант. Например, у меня 20 входов управляющей системы. Я беру, например, данные на 10 шагов назад. Получалось 200 входов.
Для этого придумали очень интересную технологию. Она называется LSTM . Например, в моей статье показано , как нейроны пропускают сигнал, не пропускают его, как-то взаимодействуют с ним. Это статическая штука. Там нейроны начали делать то же самое уже с логическими операциями. Они могут задерживать сигнал, например, на шаг. Они могут задерживать на несколько шагов. Они могут получать на вход свои предыдущие значения. Не нужно понимать, как это работает. Нужно просто понимать, что теперь информация в этой сети будет сохраняться именно то количество времени, которое сеть посчитает нужным. Опять все настройки этой сети выделили в какие-то коэффициенты. Получились огромные коэффициенты. Это все начало учиться теми же самыми deep learning алгоритмами, и все. Что мы получили? То, что такая сетка теперь может работать с временны ми рядами.
Я так долго подводил, чтобы вы не боялись этих слов, понимали, что это такое. Когда их начали соединять, люди были поражены. LSTM-сети принадлежат к классу сетей, называемых “рекуррентные”. LSTM – это одна из технологий. Самое интересное, что может делать эта рекуррентная сеть – ей можно на вход подавать слова. У нее каждое слово – это какое-то число. Она его каким-то образом векторизировала. Каждое слово – это число. Ей можно на ход подавать последовательность слов.
Соответственно, например, некоторые чат-боты, которые сейчас разрабатываются, делаются так: на ход подается последовательность слов, а с выхода идет последовательность ответов – точно так же, шаг за шагом. “Я тебя прибью”. Сетка говорит: “Пошел ты на…”. Она не знает, что это такое. Она просто знает, что в такой ситуации нужно отвечать так, иначе нарушатся какие-то критерии. Потом отвечаешь ей: “А не пошла бы ты сама!”. Она помнит, что ответила, и говорит: “Нет, не пойду”.
Сейчас это все еще не коробочные решения. Это решения для Microsoft, Google, Яндекса. У меня лично такого нет. Но ребята из Амстердама поприкалывались по-черному. Что они сделали? Они вышли на улицу и сняли на видео происходящее на улочках. Люди ездят, какие-то улочки, народ бухает, кто-то куда-то бежит, женщина спешит в магазин – обычный день, ничего интересного. Взяли это видео, принесли домой. Дальше они соединили сверточные и рекуррентные сети. Сверточные анализируют изображения. Рекуррентные дают описания. В итоге у них получилась программка, которая в текстовом виде, причем в достаточно красивом, начинает описывать: “Женщина едет туда-то. Велосипедист едет туда-то”.
Ребята накинулись на эти технологии и начали творить. Мы делаем коротенькое описание истории, например: “Мужик жил в пустыне”, что-то еще. А сеть дает полное развернутое описание этой ситуации, фантазируя, что происходит. Они ей “скормили” все романы, которые только есть, и она начала в достаточно красивом виде писать эссе на страницу. Ты можешь ей “скормить” фотографию или какое-то маленькое описание ситуации. Она тебе – развернутую ситуацию: “Он опаздывал на автобус, но не успел”. Причем даже не на уровне ребенка, а на уровне достаточно взрослого подростка. Это поражает.
Иными словами, преодолели все пороги, которые не давали работать этим сетям и получили технологию, где настройкой коэффициентов можно получить любую логику. Соответственно, осталось только настроить коэффициенты так, как нужно для той или иной задачи. Это может быть долго, это может быть дорого, это может быть еще как-то, но это возможно. А поскольку имеет место тенденция экспоненциального роста всех технологий, и сейчас понятно, что мы только в начале экспоненциального роста, то постепенно становится страшно.
Самый красивый факт из того, что может произойти – это недавняя победа в игре в го. Игра в го никак не просчитывается аналитически, потому что количество комбинаций зашкаливает. Это не шахматы. Это в миллиарды миллиардов миллиардов миллиардов раз больше возможных комбинаций, чем в шахматах. Нейронную сеть для игры в го собрали за полгода и оставили ее на полгода играть саму с собой. Этого ей хватило для того чтобы обыграть кой-какого чемпиона мира. Потом взяли самого крутого чемпиона мира по го. Она еще поиграла сама с собой три месяца и обыграла самого крутого чемпиона по го. На все про все у нее ушел год. Год назад все говорили: “Го продержится перед искусственным интеллектом еще лет 10”.
Сейчас больше нет игр. Gооgle сейчас развлекается тем, что хочет пустить в нейронную сеть StarCraft. Мой брат, являясь профессиональным геймером в StarCraft, говорит: “Катастрофа!”, потому что известно, что с неограниченным микроконтролем 20 зерлингами(читай – пешками) можно снести 10 танков. Люди, даже корейцы, будут уже не конкурентоспособны.
Соответственно, начался взрывной рост технологий. Пока это еще не коробочные решения. Понятно, как это применять, но все немного побаиваются, и нет опыта. Все ждут, кто же станет первым. Постепенно их встраивают в поиск Google, в поиск Яндекса, в выдачу Facebook, в Siri всякие, чат-боты. Постепенно-постепенно они проникают туда.
Последнее, самое жесткое, что есть. Мы, люди, любим себя. Но люди, во-первых, не могут так успешно менять себя под окружающую ситуацию, а во-вторых, у нас всегда очень мало информации. Например, когда недавно мы учили одну сетку для того чтобы просто искать синонимы и близкие по смыслу слова, мы ей “скормили” 1 гигабайт Википедии. Для того чтобы усвоить, “переварить” 1 гигабайт Википедии на стареньком Макбуке, ей понадобилось 4 часа, все романы на русском еще 8 часов. А вся коллекция романов художественной литературы, написанной в России на русском языке, содержит примерно 15 гигабайт, и весь корпус весь Википедии содержит 5 гигабайт. Итого за 3 дня такая сетка “переварит” все, точнее – основное, написанное людьми на русском языке. Она будет знать о русском языке все. На это ей понадобится несколько дней.
Ни один филолог, ни один культуровед, ни один литератор насколько хорошо, как она, не будет знать русский язык. Если нам что-то не понравится в работе этой системы, мы скажем: “Пошла вон”, что-то подкрутим, изменим ее архитектуру, попробуем еще раз. Но через год мы заведомо получим суперлитератора. Это говорит о том, почему сейчас все начинают бояться нейронных сетей, и почему именно сейчас, сегодня, происходит взрывной рост. Вот так.
Спасибо за отличный рассказ. Сейчас нейронные сети “заточены” на выполнение каких-то определенных задач. Если сеть умеет распознавать котиков, она уже не может распознавать собак или если она пишет романы на русском, то распознавать котиков она тоже не может. Это правильно?
Да, правильно. Но нужно понимать, что человек тоже “заточен” на выполнение определенных действий, а именно – размножение, выживание, и все. Без шуток. У нас стоит сверточная сеть (конечно, продвинутая) на зрительной коре, продвинутая рекуррентная сеть на слуховой коре, и где-то в глубинах мозга другие виды сетей, мы еще до них не докопались. Но по сути дела, это Клондайк нескольких сетей, “заточенных” на каждый орган чувств. Есть некоторая конечная мотивация – оценка того, что происходит. В соответствии с этой оценкой наш организм вырабатывает эндорфин, либо серотонин, либо адреналин – одним словом, контролирует общее состояние нервной системы. Вот и все.
Но у человека есть еще отрицательная характеристика. Предположим, я дежурю на атомной подстанции, и у меня комплексы. Например, в детстве меня били палками. Я из-за этих комплексов могу не выполнить задачу. А если сетка натренирована на это, известно, что она не будет думать о проблемах мировой революции и о том, что ее били палкой в детстве, когда она увидит, что температура в каком-то из контуров начала выходить за пределы допустимых значений. Она будет все анализировать лучше.
Не очень понятно. Сетке “в детстве” показывали котиков, и у нее от этого травма, а пик температуры на графике напоминает уши котиков, и она от этого замкнется. Почему невозможна такая ситуация?
Сетка, которая будет работать – это будет другая сетка. Когда мы сделаем на текущем уровне развития технологий (я не буду сейчас фантастом), на текущем этапе развития технологий мы не будем делать одну и ту же универсальную сетку, которая и распознает котика, и контролирует ситуацию на станции. Нам это не нужно. Нам нужна сетка, которая четко выполняет конкретную задачу. Причем, если конкретная задача очень широка, например, распознавать всех животных, людей и их эмоции по фотографиям (согласитесь, это достаточно серьезная задача), она будет выполнять эту задачу. Выходы этой обученной сетки отдельные, изолированные мы красиво можем соединить с другой сеткой, которая может принимать решения, или это может быть экспертная система. Мы можем так накручивать сколь угодно много, пока не получим нужное. Универсального решения никто не ищет. Всегда нужна какая-то конкретная задача. Если задача будет очень широкая, то будет очень широкое решение, если узкая – будет узкое и красивое решение.
Фактически, чтобы воспроизвести человека, нам понадобится много-много таких искусных нейронных сетей, которые будут последовательно или параллельно соединяться в подобие человеческого мозга. Я правильно понимаю?
Если поставить цель – воспроизвести подобие человека с руками, ногами и всем остальным. Серьезно. С искусственным интеллектом.
Я говорю о разуме.
Во-первых, посмотрим на человека. У него есть кора головного мозга. У нас есть мозжечок. У нас есть зрительная кора, у нас есть акустическая кора, гипоталамус и т.д. Левое и правое полушарие. Это все отдельные сетки. Есть глубинный слой – подсознание: все эти сетки уходят вглубь. Видно, что они стыкуются друг с другом.
Помните, я вам рассказывал, как соединили два типа сеток – сверточную и рекуррентную – и получили описание по картинкам происходящего вокруг на улице? Насколько я понимаю, они не особо закладывали туда архитектуру, то есть связи между этими сетками программа тоже делала в автоматическом режиме, тем же самым генетическим алгоритмом. Все равно инженерия, та или иная, остается и в эволюции, и у людей.
Просто быть человеком, чтобы робот вел себя как человек – это очень широкая задача. С какого-то момента самое сложное будет не в том, чтобы закодить это, а в том, чтобы понять, чего мы от этого хотим.
Серьезно. Мы хотим, чтобы оно убирало посуду? Или чтобы это была идеальная любовница? Или чтобы это был идеальный воин? А мы будем в него закладывать инстинкт самосохранения, чтобы потом получить нечто, что захватит планету, или не будем? У нас он эволюцией заложен жестко и на очень низком уровне. А ему-то зачем закладывать? Самый конечный вопрос. А зачем нам это надо? Поиграть? Скорее всего, вы увидите одного такого человека – андроида, и скажете: “Классно! Мы тебя увидели. Давайте теперь решать нормальные задачи – выращивать хлеб, убивать людей”. Такие нормальные человеческие задачи.
Хорошо. Понятно. Мы углубились в будущее. Я возвращаюсь к текущим задачам и реалиям. Вопрос в правильности понимания работы нейронных сетей, искусственного интеллекта. У нас в статье было написано, что, создав сеть, уже мало кто может понять, на основании чего она принимает решения. Это так или нет?
В большинстве случаев – да. Если вы , вы помните, что я расписал 9 нейрончиков – как работает каждый из них. Их было 9, но это совсем утрированный пример. Во-первых, повторю еще раз то, что там было. То, что происходит на скрытом слое, никогда не формализуется человеком. Мы просто говорим: “3 на 3. Вот такие три входа, такие три выхода. Вот пары: как было, как должно быть. Учись”. Что она делает на этих скрытых слоях – никто не знает.
Сетки для решения сложных задач не обязательно многослойные, но они обычно очень широкие, то есть там очень большие слои – по тысяче, десять тысяч нейронов. Оно находит правило. Мы лишь можем оценить, насколько это правило хорошее. Потому что никто в здравом уме никак не может точно проверить. В том-то и дело, что, если бы могли все это закодировать строгой логикой, и вообще человек это мог бы сделать, на это есть программисты – такие люди, как я, например. Мы пишем циклы, if, функции.
Goto – главное.
Goto. Потом друг друга бьем за Goto. Все, что мы можем формализовать, нам дают языки программирования. Нейронные сети дают некоторые абстрактные, сами как-то настраивают правила. Мы лишь можем оценить адекватность того, насколько они обучены, и все.
Хорошо. В моем понимании правила – это какая-то определенная таблица, которая говорит, что если в квадратике диагональ справа налево, то это кошка, а если слева направо, то это собака. Эти правила где-то записаны, то есть мы фактически можем до них докопаться и вывести на истоки принятия тех или иных решений.
К сожалению, нет. Правила – не таблица, никакого “if” там нет. Там набор коэффициентов и порогов, то есть это огромное количество чисел. Например, в сети 3 на 3, о которой я говорил, может быть порядка 20-ти чисел, которые входят в настройки. В сети 10 тысяч на 100 таких коэффициентов будут миллиарды. Все.
Как все работаем потом? При помощи этих коэффициентов можно сделать четкое “или”, например, логический оператор. Все, что можно закодить, можно закодить машиной Тьюринга – есть такая теорема. Соответственно, чтобы у нас была машина Тьюринга (она же тоже работает с временными рядами), что нам нужно? Нам нужен сдвиг. Нам нужны базовые логические операторы: “и”, “или”, сложение, умножение. Это можно делать через настройку коэффициентов. Например, мы можем сделать через настройку коэффициентов исключающий “или”, “и”, любой логический оператор. Пока мы работаем с одним логическим оператором, мы четко видим, как логика распространяется, какие есть выходы, можем все протестировать.
Но когда начинается сетка 10 тысяч на 10 тысяч, то есть огромная, мы не можем проанализировать, какие логические схемы она строит для того чтобы удовлетворить обучающую выборку, потому что это просто набор чисел. Мы, если очень уж захотим, конечно, можем изолировать какую-то ее часть, и дальше исследовать ее примерно так, как исследуют мозг человека, показывая ему разных собачек, кошек, оружие и т.д.: какой нейрон где загорится, где какие нейроны горят постоянно, какие “отвалились”. Только так. Но нет какой-то таблицы, чтобы была какая-то логика принятия решений.
Один нейрон говорит: “Я распознал какой-то абстрактный образ А”. Второй нейрон говорит: “Я распознал какой-то абстрактный образ Б”. Третий нейрон говорит: “Я не распознал абстрактный образ С”. Выходной нейрон спрашивает: “Насколько хорошо вы их распознали?”. У них, соответственно, точность 80, 90 и 10 процентов. Выходной нейрон говорит: “Значит, с вероятностью 75% это кошка”.
Теперь у вас немой вопрос: “Что за абстрактный образ А?”. Я говорю, что не знаю, что это за абстрактный образ А. Этот абстрактный образ А пришел еще из каких-то 20-ти подабстрактных образов или их отсутствия. А они, в свою очередь уже пришли из того, что где-то есть диагональка, которая пересекается с другой диагональкой. Наверно, аналитически мы сможем понять – похоже это на ушко, причем ушко кошки, потому что у собаки будут не диагональки, а что-то размытое, висящее и дурно пахнущее. Решение принимается примерно так.
Нейронная сеть – это всего лишь способ превратить любую логику в набор коэффициентов. Но когда мы настроили эти коэффициенты, мы уже не можем анализировать эту логику. Это слишком сложно для человеческого восприятия. Особенно потому, что мы привыкли анализировать что-то в четкой логике. Если что, у нас на это настроено левое полушарие. Если я подойду и ударю боксера, то, скорее всего, мне будет плохо. На самом деле, мы думаем даже не так. Мы думаем: “Мне будет плохо”. Мы не оцениваем возможность боксера.
А здесь получается нечеткая логика. Если я подойду к боксеру с этого угла, в этой ситуации, при этом боксер будет немного пьян, а освещение будет такое, вероятность “получить в табло” будет 35%. Мы называем это интуицией. У нас для этого есть правое полушарие мозга. Оно отлично отрабатывает. Когда мы ничего не понимаем, мы называем это “религия”, “магия” или “женская логика”, если нам это нравится или не нравится. Или кого-то называем гением. Мы не можем анализировать наши поступки. То же самое и здесь.
Хорошо. Логически вытекает следующий вопрос. Есть система, логика работы которой не очень четкая, понять ее невозможно. А как при этом нейронная сеть может управлять электрической или атомной станцией? Если ее решения никогда не понимаемы человеком, она в определенной ситуации может разогнать реактор или наоборот его заглушить. Но как можно доверять такой системе жизненные показатели или жизненно важные системы?
Здесь все очень просто. Так получилось, что я как раз 5 лет работал в электроэнергетике, как раз на системах управления. У нас же есть не только система принятия решения. Например, сейчас компьютерная. Там стоит релейная автоматика, то есть некоторые дублирующие системы. Там три системы. Релейная автоматика. Она работает уж совсем просто. Температура больше – это то-то, делать се-то, все. Есть автоматическая система управления. Это компьютер. Сейчас там логика запрограммирована программистами. Есть, в конце концов, сонный дежурный, который развлекается тем, что играет в пасьянс. Как ему ни запрещают, он все равно найдет способ поиграть в пасьянс.
Мы можем спланировать как угодно. Лично я делал бы так. Я бы оставил релейную автоматику. По компьютерной автоматике у нас есть состояния консистентное, не консистентное. Например, при повышении температуры реактора, если повышение температуры за последние несколько часов будет в такой-то точке, то мне нельзя держать стержни менее чем на таком уровне. Это прописывается в ГОСТах. Соответственно, когда мы делаем не консистентное состояние, мы из нечеткой логики переходим в четкую.
А теперь очень интересная аналогия. У нас, у людей, происходит то же самое. У нас две системы принятия решений. Одну мы называем “логика”, а вторую мы называем “интуиция” или “подсознание”. Они постоянно дублируют друг друга. Предположим, я хочу мороженое, но у меня болит зуб. Если бы у вас не было системы логики, вполне вероятно, вы бы жрали мороженое пока зуб не заболит так, что вы просто не сможете есть ничего. Но у вас на это есть логика, поэтому вы не едите мороженое и идете к врачу. Потому что вам кто-то сказал. А интуиция еще не знает о том, кто такой врач. Просто по логике идете к врачу, потому что вам кто-то сказал, или вы прочитали в Интернете.
Здесь то же самое. У вас здесь будет две системы. Одна контролирующая, а вторая автоматическая. Задача нейронной сети здесь будет заключаться в том, чтобы не допустить подхода к предельному или пограничному значению. Понимаете? А поскольку она будет видеть больше взаимосвязей, чем видит человек, даже самый опытный, то, скорее всего, она будет работать значительно лучше.
В каких пределах, в каких целевых задачах нейронная сеть сейчас сможет заменить человека? Или она уже способна (на примере го) во многих областях принимать лучшие решения, чем человек?
Мне кажется, но это уже совсем не четкий ответ, как на примере с го, все может случиться в любую минуту. Я как раз слушал лекцию на эту тему. Все может случиться в любой момент. Мне кажется, что это примерно, как с развитием персональных компьютеров. Первые персональные компьютеры у нас появились на Аполлоне. Apple II, который серьезно пошел в массы, появился, по-моему, через 8 лет. Аполлоны 1969 года, Apple II, по-моему, 1977. До этого появилась еще какая-то IВМ. Сейчас нейронные сети уже, наверно, постарше, чем Apple II, но я как программист могу вам сказать, что нет коробочных решений, которые я могу быстро развернуть и понять. Когда они появятся? Я предполагаю, что это произойдет примерно в течение пяти лет. Почему я назвал именно эту цифру? Потому что это прогнозы относительно того, когда роботы-автомобили спокойно выйдут на территорию Америки, начнут ездить.
Соответственно, через 5 лет начнется серьезное замещение многих людей. Точнее сейчас люди будут стоять на контроле. Что будет вначале долгое время спасать – то, что у компьютерной системы ограниченная надежность и достаточно высокая стоимость самой системы и обслуживания. Пока эти стоимости буду выше чем, условно говоря, зарплата тракториста, до тех пор нейронные сети будут не очень конкурентоспособными. Но постепенно эти стоимости станут сравнимы.
Например, сейчас уже есть японские тракторы, которые могут сами косить. Для трактора это не очень сложная задача. Такой трактор выкосит все поле и при этом не перерубит детей, которые спрятались в пшенице. Но, например, русский тракторист Ваня обходится 8 тысяч в месяц, а поддержка японского трактора стоит в среднем 1.5 тысячи долларов в месяц при хорошем парке и большой ферме, в лучшем случае. Пока Ваня выигрывает. Но сколько еще это продлится? Когда эффективность одного трактора (без Вани) станет значительно выше, чем у десяти Вань? Это дело времени.

Вы сказали, что одной из сфер применения являются автоматические автомобили, автопилоты, роботы-автомобили. Сейчас много говорят о том, что в Америке грядет революция даже не в пассажирском транспорте, а в грузоперевозках, когда на больших траках водителей будут заменять роботами, автоматами, искусственным интеллектом. Тогда люди начнут протестовать против искусственного интеллекта? Что им нужно будет делать, чтобы вернуть свою работу или чем им придется заниматься?
Я очень плохо разбираюсь в политических и гуманитарных системах. Я не являюсь профессионалом, но тоже об этом много думал. Помните, как было? У нас было несколько таких примеров. Первый пример: печатные машинки заменили калиграфов. Помните, было такое? Потом была промышленная революция. Компьютеры вошли очень органично потому что, оказывается, те, кто раньше писал на бумажках, были только рады этому. Компьютеры вроде бы ничего подобного не сделали, даже создали рабочие места.
Я думаю, что это действительно серьезная большая проблема. Но есть здесь и позитивная норма. Возьмем какую-нибудь страну. Например, гипотетическую Голландию. Гипотетическая Голландия зарабатывает, например, миллиард условных долларов в год. Соответственно, она этот миллиард долларов тратит на свой бюджет – что-то делает для каких-то людей. Мы берем всех людей. Экономика оценивается как скорость прокрутки денежного потока. Нам достаточно трех долларов на всю страну, но если они проходят через руки каждого со скоростью четыре раза в секунду, получается, что каждый очень много зарабатывает и тратит.
Соответственно, если государство грамотно строит экономику, но скорость денежного оборота из-за прихода этих нейронных систем не падает, то все хорошо. Я думаю, что все государства будут к этому стремиться. Например, эксперименты с безусловным доходом, которые сейчас происходят, или что-то еще.
Но вообще проблема – чем будут заниматься люди – очень острая. Это очень большой вопрос.
Сегодня я пишу программу. Вы, как я понимаю, пишите статьи? Правильно я понимаю?
Нас всех заменят?
Да. Это не шутки. Помните, раньше люди сами вязали свитера? Я недавно был в Непале, и купил вязаный свитер hand made. Ничем не отличается от не вязаного, но вроде бы классно. В России можно купить. Он будет стоить дорого. Примерно то же самое. При этом не факт, что hand made будет лучше. Я думаю, что мы с вами не захотим ездить на автомобиле, собранном вручную.
Это огромный колоссальный вопрос – чем будут заниматься люди с приходом нейронных сетей.
Нейронные сети, искусственный интеллект сможет решать творческие задачи? В самом начале мы говорили о том, что такие системы уже умеют описывать фотографии или какие-то события по отдельным частям, наверно, писать сценарии. Недавно, буквально на прошлой неделе, была новость о том, что сняли первый фильм по сценарию искусственного интеллекта. Они смогут реально творить что-то новое, то есть программировать, писать картины, снимать фильмы или писать сценарии, а не просто повторять за кем-то?
Два года назад я тоже думал об этом, что все хорошо. Как бы ни развивалось, так и будет. А потом я сказал так. Эволюция ограничила наши творческие способности по одной простой причине: потому что они средне деструктивные. Но в среднем это то, что нужно. Эволюция иногда создает левшу, который прибегает и творит какой-то хаос. А еще лучше, если это переученный левша, у которого биполярное расстройство. Какой-нибудь Джобс. Прибежит, натворит хаос. Двинет весь социум вперед ценой собственной нормальной счастливой жизни. Это нормально. Какой-нибудь Курт Кобейн, Иисус Христос. Полно народу. Эволюции - это выгодно, так как человечество двигается. Но если она сделает такими всех, то человечество вымрет. Потому что придут обезьяны, а люди будут угорать: “Как?! Они нас убивают”, слишком рано задумаются о том, что жизнь бессмысленна, детей делать не нужно.
А на нейронных сетях таких ограничений нет. Мы все привыкли считать творчество необычной штукой просто потому, что мало людей им занимается, а не потому, что мы выдали что-то определенно новое. Любое творчество заключается в том, что взяли старый опыт, примешали к нему немного рандома, попробовали по-новому. Оставили старые условия и придали этому какую-то новую форму. Причем форму взяли из какой-нибудь соседней области. Например, как это было в музыке? Появился стиль минимализм. Взяли минимализм из дизайна, перетащили в музыку. Вот и все. И так далее.
Я предполагаю, что, наверно, не сразу, но эта задача будет решаться даже проще, чем управление автомобилем. Управление автомобилем – задача эволюционно привычная для человека. Поэтому нам кажется, что это проще, чем написать музыку. А нейронная сеть, написав плохую музыку, не сможет убить человека. Поэтому нейронной сети будет проще писать, чем управлять автомобилем в определенный момент.
Это спорный вопрос – можно ли плохой музыкой убить.
Я с вами согласен.
Хорошо. Следующий вопрос. Творческие задачи тоже будут решены. А есть ли какие-нибудь ограничения, где неприменимы навыки или возможности искусственного интеллекта? Или как говорили в кино: “Будет все одно сплошное телевидение”, будет один сплошной искусственный интеллект и нейронные сети. Есть какие-то области, где все-таки это не будет эффективно работать?
В течение пяти лет будет множество таких областей, если так все пойдет. Но если это действительно экспонента, то через 20 лет – нет, не будет таких областей.
Я долго об этом думал и прихожу к выводу, что постепенно нейронные сети будут делать так. Сначала давайте все-таки оптимизируем производство. Давайте. Подключим к ней все станки. Она будет давать экспертное решение, а люди будут определять, правильное оно или нет. Подключили. А давайте всю нашу корпорацию Google или Apple “посадим” на нее. Она будет смотреть и думать, какие зарплаты устанавливать, мониторить рынок – продавать акции или покупать акции, заниматься высокочастотным трейдингом и так далее. Давайте? Давайте. Сделали. А потом давайте она будет помогать нашим политикам. Людей очень много. Известно, что хороший политик – информированный политик. Нам нужна экспертная система. Поможет? Поможет, сделаем.
Так это будет все разрастаться, разрастаться, разрастаться, например, уже до управления государством. Пока в определенный момент кто-нибудь не допустит фатальную ошибку в целях сети. У сети задача – найти, как сделать людям лучше. Ей постепенно будут отдавать ответственность. Например, она сможет пускать автобусы по другому расписанию или еще что-то. Вы знаете, что НЛП-методики очень просты. Здесь подтолкнул, здесь подчихнул, здесь показал что-то не то. Люди приняли такое решение, какое тебе нужно, и крекс-пекс, президент у нас уже нейронная сеть, искусственный интеллект.
Я считаю, что на самом деле это очень и очень здорово, потому что такая система сможет контролировать потребности каждого человека. Но не те потребности, что кто-то хочет быть геем, а кому-то страшно насилие, поэтому давайте все будем ультра толерантными. Есть и другие решения этой задачи. Давайте этих людей немного изолируем, будем показывать им разный контент. А этому чуваку хочется пожестить, давайте мы отправим его во французский иностранный легион.
Дальше уже в зависимости от программирования. Но, скорее всего, у нейронной сети агрессии не будет, если кто-то очень старательно не станет этого делать. Излишней толерантности у нее тоже не будет. Она будет принимать реально взвешенное и мудрое решение. Это, на самом деле, спасение для человечества, которого сейчас очень много. Поэтому я думаю, этого бояться не стоит. Стоит бояться того, что действительно непонятно, кем мы все скоро будем работать.
Вернемся к нашим временам. Вы говорили, что коробочного решения пока нет. Насколько я читал, видел, есть просто какие-то системы open source, на которых можно потренироваться. Вы можете порекомендовать примеры, на которых наши читатели, слушатели могут попробовать потренировать искусственный интеллект и вынести из этого какие-то решения?
Конечно, есть. Я имею в виду, что пока не найден путь, как эту “коробочку” принести в бизнес, но в интернете система заработала. Это инструменты немного более низкого уровня. Я точно знаю два таких инструмента. Здесь еще зависит от языка программирования. Первый – самая классная штука – это Word2Vec – буквально “словарь-вектор”. В чем заключается идея? Ты ей “кормишь” огромные корпуса знаний (это то, чем занимался я), она превращает слова в вектора, и мы можем делать с ними арифметические операции.
У меня был очень смешной пример. Я беру такое словосочетание: “мальчик плюс девочка”. Она говорит: “Близкие слова: жених”. Я: “Классно”. У нее большой список слов, но одно из первых – “жених”. Молодец. “Девочка плюс мальчик”. Она: “Мисс, миссис”. Примерно правильно поняла. Но дальше самое интересное. Я говорю: “Девочка минус мальчик”. И тут началось то, от чего я заплакал. Девочка минус мальчик – это “оставлено, зафиксировано, налажено, ликвидировано, развернуто”. Я говорю: “А мальчик минус девочка?”, и сеть мне неоднозначно – “магистратура”.
Логично.
Я говорю: “ОК. Близкие слова к слову “глупость”. Она говорит: “Радость, безумие, чувственность, грусть, доброта, любовь, красота, субъективность”. Я говорю: “Классно”. Пошел по другому пути. Там есть такая штука: если А – это В, то С – это… Пример. Если Париж – это Франция, то Рим – это…? Она отвечает: “Италия”. Я говорю: “ОК. Если вино – это весело, то водка – это…?” – “Глупо”. Я говорю: “Ладно”. Она начала еще больше угорать. Я: “ОК. Мальчик хороший, а девочка…?” Она: “Плохая”. Я: “Хорошо. Девочка хорошая, а мальчик…?” – “Лучше”. Это Word2Vec. Очень угарная штука. Безумно. Нужно немного разобраться с ней, и можно зависнуть в ней надолго. Она существует для того чтобы понимать эмоциональные оттенки текста. Например, негативный комментарий пользователь оставил или нет. Это первое.
Второй очень классный из базовых конструкторов open source – Aforge.net . Это открытая библиотека. В ней всякие генетические алгоритмы, целый Клондайк. С ней можно делать много интересного.
Самое интересное баловство с нейронными сетями – это генетические алгоритмы для создания живых существ. Как их делают? Создают маленькое живое существо, которое должно передвигаться, уворачиваться от хищников и жрать еду. В лучшем случае создают два эволюционных существа. Одно – это жертва, а второе – хищник. У него есть сенсор. Условно сенсоры – дальномеры. Показывает, что впереди. Существо может поворачиваться направо, налево, идти вперед, назад и тратить на это еду. Мы задаем физический мир. Соединяем все сенсоры с двигателем через нейронную сеть и говорим: “Учить”. Соответственно, кого-то съедают, кто-то дает потомство. Через некоторое время мы получаем красивую бактерию. Они друг от друга уворачиваются, гоняются друг за другом. Тактику охоты могут выработать.
Либо второй вариант. Это было давно. На Хабре очень популярный пост. Вид сбоку: из колесиков и планочек нужно было собрать типа багги, которая должна была проехать по заданной карте как можно дальше. Если она проезжает далеко, она дает больше потомства. Если проезжает недалеко – меньше потомства. Постепенно там сами по себе создавались такие супер крутые транспортные средства, и все становилось хорошо. Вот то, что я могу порекомендовать, чтобы побаловаться, попробовать эти источники.






