Многоуровневое меню на PHP и MySQL. Сценарий дня рождения мужчины Рождения мужчине search item php i
Регулярные выражения – это очень полезный инструмент для разработчиков. С их помощью можно находить, определять или заменять текст, слова или любые другие символы. В сегодняшней статье собраны 15 наиболее полезных регулярных выражений, которые пригодятся любому веб-разработчику.
Введение в регулярные выражения
Многим начинающим разработчикам кажется, что регулярные выражения очень сложны для понимания и использования. На самом деле, все не так уж сложно, как может показаться. Прежде чем мы непосредственно перейдем к регулярным выражениям, с их полезным и универсальным кодом, давайте взглянем на основы:
Синтаксис регулярных выражений
| Регулярное выражение | Означает |
| foo | Строка “foo” |
| ^foo | Строка начинается с “foo” |
| foo$ | Строка заканчивается на “foo” |
| ^foo$ | «foo» встречается в строке только один раз |
| a, b, или c | |
| любой символ в нижнем регистре | |
| [^A-Z] | любой символ, не находящийся в верхнем регистре |
| (gif|jpg) | Означает как «gif” так и “jpeg” |
| + | Один или более символов нижнего регистра |
| Любая цифра, точка или знак минус | |
| ^{1,}$ | Любое слово, хотя бы одна буква, число или _ |
| ()() | wy, wz, xy, или xz |
| (^A-Za-z0-9) | Любой символ (не число и не буква) |
| ({3}|{4}) | Означает три буквы или 4 цифры |
PHP-функции для регулярных выражений
| Функция | Описание |
| preg_match() | Функция preg_match() ищет строку по заданному шаблону, возвращает true, если строка находится и false, в остальных случаях |
| preg_match_all() | Функция preg_match_all() находит все вхождения строки, заданной по шаблону |
| preg_replace() | Функция preg_replace(), действует по тому же принципу, что и ereg_replace(), за исключением того, что регулярные выражения можно использовать как для задания шаблона поиска, так и для строки, на которую следует заменить, найденное значение. |
| preg_split() | Функция preg_split(), действует так же как split(), за исключением того, что регулярное выражение можно использовать в качестве параметра для шаблона поиска. |
| preg_grep() | Функция preg_grep() ищет все элементы входного массива, возвращая все элементы, соответствующие шаблону регулярного выражения. |
| preg_quote() | Экранирует символы регулярного выражения |
Проверка доменного имени
Проверяем, является ли строка правильным доменным именем
$url = "http://komunitasweb.com/"; if (preg_match("/^(http|https|ftp)://(*(?:.*)+):?(d+)?/?/i", $url)) { echo "Your url is ok."; } else { echo "Wrong url."; }
Подсветка слова в тексте
Это очень полезное регулярное выражение, с его помощью вы можете найти нужное слово и подсветить его. Особенно полезно для отображения результатов поиска.
$text = "Sample sentence from KomunitasWeb, regex has become popular in web programming. Now we learn regex. According to wikipedia, Regular expressions (abbreviated as regex or regexp, with plural forms regexes, regexps, or regexen) are written in a formal language that can be interpreted by a regular expression processor"; $text = preg_replace("/b(regex)b/i", "1", $text); echo $text;
Подсветка результатов поиска в WordPress блоге
Как уже говорилось в предыдущем примере, этот пример кода, удобно использовать в выдаче поисковых результатов и есть отличный способ внедрить эту функцию в wordpress-блог.
Откройте ваш файл search.php, и найдите функцию the_title(). Замените ее следующим кодом:
Echo $title;
Теперь, выше этой строки, добавьте этот код:
\0", $title); ?>
Сохраните файл search.php, и откройте style.css. Добавьте следующую строку:
Strong.search-excerpt { background: yellow; }
Получение всех картинок из HTML-документа
Если вам когда-нибудь требовалось получить все картинки с веб-страницы, этот код должен быть Вы легко сможете создать загрузчик изображений с помощью возможностей cURL
$images = array(); preg_match_all("/(img|src)=("|\")[^"\">]+/i", $data, $media); unset($data); $data = preg_replace("/(img|src)("|\"|="|=\")(.*)/i", "$3", $media); foreach ($data as $url) { $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); } }
Удаление повторяющихся слов (не чувствителен к регистру)
Во время печатания, часто повторяются слова? Поможет это регулярное выражение.
$text = preg_replace("/s(w+s)1/i", "$1", $text);
Удаление повторяющейся пунктуации
То же самое, только для пунктуации. Попрощайтесь с двойными запятыми.
$text = preg_replace("/.+/i", ".", $text);
Поиск XML/HTML тэгов
Эта простая функция, принимает два аргумента. Первый – это тэг, который вам нужно найти, и второй – это переменная, содержащая XML или HTML. Повторюсь, эту функцию очень удобно использовать вместе с cURL.
Function get_tag($tag, $xml) { $tag = preg_quote($tag); preg_match_all("{<".$tag."[^>]*>(.*?)."}", $xml, $matches, PREG_PATTERN_ORDER); return $matches; }
Поиск XHTML/XML тэгов с определенным значением атрибута
Эта функция очень похожа на предыдущую, за исключением того, что вы можете задать тегу нужный атрибут. Например, вы легко сможете найти
Function get_tag($attr, $value, $xml, $tag=null) { if(is_null($tag)) $tag = "\w+"; else $tag = preg_quote($tag); $attr = preg_quote($attr); $value = preg_quote($value); $tag_regex = "/<(".$tag.")[^>]*$attr\s*=\s*". "(["\"])$value\\2[^>]*>(.*?)<\/\\1>/" preg_match_all($tag_regex, $xml, $matches, PREG_PATTERN_ORDER); return $matches; }
Поиск шестнадцатеричных значений цветов
Еще один полезный инструмент для веб-разработчика! Он позволяет вам находить/проверять шестнадцатеричные значение цвета.
$string = "#555555"; if (preg_match("/^#(?:(?:{3}){1,2})$/i", $string)) { echo "example 6 successful."; }
Поиск заголовка статьи
Этот фрагмент кода найдет и выведет на экран текст, находящийся внутри тэгов
$fp = fopen("http://www.catswhocode.com/blog","r"); while (!feof($fp)){ $page .= fgets($fp, 4096); } $titre = eregi("
Парсинг логов Apache
Большинство сайтов запущено на всем известном веб-сервере Apache. Если ваш сайт находится в их числе, почему бы не использовать PHP и регулярные выражения для разбора логов апача?
//Logs: Apache web server //Successful hits to HTML files only. Useful for counting the number of page views. "^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)/[^ ?"]+?.html?)??((?#parameters)[^ ?"]+)? HTTP/+"s+(?#status code)200s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$" //Logs: Apache web server //404 errors only "^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)[^ ?"]+)??((?#parameters)[^ ?"]+)? HTTP/+"s+(?#status code)404s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$"
Замена двойных кавычек “умными” кавычками
Если вы любитель типографики, вам понравится это регулярное выражение, заменяющее обычные двойные кавычки, на “умные кавычки”. Похожее регулярное выражение используется в wordpress в контенте страницы.
Preg_replace("B"b([^"x84x93x94rn]+)b"B", "?1?", $text);
Комплексная проверка пароля
Это регулярное выражение будет следить за тем, чтобы в текстовое поле было введено не менее шести символов, цифры, дефисы и подчеркивания.
Текстовое поле должно содержать как минимум один символ верхнего регистра, один нижнего регистра и одну цифру.
"A(?=[-_a-zA-Z0-9]*?)(?=[-_a-zA-Z0-9]*?)(?=[-_a-zA-Z0-9]*?)[-_a-zA-Z0-9]{6,}z"
WordPress: Использование регулярного выражения для получения картинок из записи
Поскольку многие из вас являются пользователями WordPress, вам возможно пригодится код, который позволяет получить все картинки, из текста статьи, и вывести их.
Для того, чтобы использовать этот код, просто вставьте его в любой файл вашей темы.
post_content;
$szSearchPattern = "~]* />~";
// Run preg_match_all to grab all the images and save the results in $aPics
preg_match_all($szSearchPattern, $szPostContent, $aPics);
// Check to see if we have at least 1 image
$iNumberOfPics = count($aPics);
if ($iNumberOfPics > 0) {
// Now here you would do whatever you need to do with the images
// For this example the images are just displayed
for ($i=0; $i < $iNumberOfPics ; $i++) {
echo $aPics[$i];
};
};
endwhile;
endif;
?>
Генерация автоматических смайлов
Другая функция, используемая в wordpress – позволяет автоматически заменять символы смайлов на картинку смайла.
$texte="A text with a smiley:-)";
echo str_replace(":-)"," ",$texte);
",$texte);
В этой статье я покажу, как можно создавать многоуровневое меню на PHP и MySQL . Безусловно, вариантов его создания можно придумать много, но, судя по количеству Ваших вопросов на эту тему, Вам нужен пример. И его я приведу в этой статье. Сразу отмечу, что данная статья имеет смысл только для тех, кто знает PHP и умеет работать с MySQL . Всем остальным сначала надо пройти этот , либо прочитать какие-нибудь книги по PHP и MySQL .
Для начала создадим таблицу в базе данных со следующими полями:
- id - уникальный идентификатор.
- title - анкор ссылки в меню.
- link - адрес, на который будет вести пункт меню.
- parent_id - родительский ID. Если родительского пункта нет, то здесь будет NULL (либо можно ещё 0 поставить).
С таблицей разобрались, теперь пришло время PHP-кода . Полный PHP-код приведён ниже:
$mysqli = new mysqli("localhost", "root", "", "db"); // Подключаемся к БД
$result_set = $mysqli->query("SELECT * FROM `menu`"); // Делаем выборку всех записей из таблицы с меню
$items = array(); // Массив для пунктов меню
while (($row = $result_set->fetch_assoc()) != false) $items[$row["id"]] = $row; // Заполняем массив выборкой из БД
$childrens = array(); // Массив для соответствий дочерних элементов их родительским
foreach ($items as $item) {
if ($item["parent_id"]) $childrens[$item["id"]] = $item["parent_id"]; // Заполняем массив
}
function printItem($item, $items, $childrens) {
/* Выводим пункт меню */
echo "
echo "".$item["title"]."";
$ul = false; // Выводились ли дочерние элементы?
while (true) {
/* Бесконечный цикл, в котором мы ищем все дочерние элементы */
$key = array_search($item["id"], $childrens); // Ищем дочерний элемент
if (!$key) {
/* Дочерних элементов не найдено */
if ($ul) echo ""; // Если выводились дочерние элементы, то закрываем список
break; // Выходим из цикла
}
unset($childrens[$key]); // Удаляем найденный элемент (чтобы он не выводился ещё раз)
if (!$ul) {
echo "
- "; // Начинаем внутренний список, если дочерних элементов ещё не было
$ul = true; // Устанавливаем флаг
}
echo printItem($items[$key], $items, $childrens); // Рекурсивно выводим все дочерние элементы
}
echo "
}
?>
Этот код полностью рабочий, однако, Вы должны понимать, что так никто не пишет (в частности, вывод через echo HTML-тегов ). И Ваша задача взять алгоритм из этого кода, но не сам код. А дальше этот алгоритм подключить к своему движку. Я постарался тщательно прокомментировать код вывода многоуровневого меню на PHP и MySQL , но, безусловно, он не самый прозрачный и требует уже неплохих начальных знаний. Если Вы ещё плохо знаете PHP и MySQL , то сначала настоятельно рекомендую пройти этот
macros("search", "search_do") ?>
Может быть использован с параметром " ?search_string=поисковый_запрос ". В остальных случаях будет пытаться получить его из URL .
%total%Выводит общее количество новостей в ленте. Можно использовать для макроса %system numpages()% .
%per_page%Выводит значение параметра per_page. Можно использовать для макроса %system numpages()% .
%list-class-first%в случае, если элемент первый, выводит "first"
%list-class-last%в случае, если элемент последний, выводит "last"
%list-class-odd%в случае, если элемент четный, выводит "odd"
%list-class-even%в случае, если элемент нечетный, выводит "even"
%list-position%вставляет порядковый номер в списке
search_empty_result
Используется в том случае, если в результате поиска не найдено ни одной страницы. В таком случае этот блок выводится вместо блока search_block .
%last_search_string%
Выводит предыдущий поисковый запрос, если такой был.
search_block_line_quant
Выводит некий разделитель, который вставляется между результатами поиска.
Примеры использования
Найдено %total% страниц. %lines%%system numpages(%total%, %per_page%)%
END; $FORMS ["search_block_line" ] = <<Название
%search search_do()% — Выводит результаты поиска по сайту.
Параметры: search search_do()
template
Имя шаблона, по которому следует выводить результаты поиска по сайту. В XSLT-шаблонизаторе игнорируется.
Search_string
Поисковая фраза. Если значение не задано, оно берётся из переданного через форму поиска запроса.
Search_types
Список идентификаторов иерархических типов для поиска (указываются через пробел). Если значение не указано, поиск оcуществляется по всем типам.
Search_branches
Список разделов в которых будет осуществляться поиск (указываются через пробел). Если значение не указано, поиск осуществляется по всем разделам. Параметр может принимать как id страниц, так и их URL.
Per_page
Количество результатов на странице. Если параметр не задан, будет взято значение, указанное в настройках модуля "Поиск".
Описание
Выводит результаты поиска, если они переданы через форму, выведенную с помощью макроса %search insert_form()% (поисковый запрос будет присутствовать в URL после отправки данных формы).
По умолчанию для вывода результатов поиска используется системная страница с адресом /search/search_do/ . Можно создать обычную страницу контента, вставить в нее макрос %search search_do(...)% и в форме поиска, выводимой через %search insert_form()% поменять атрибут action у тега form на адрес этой страницы контента.
В результатах поиска искомые слова будут выделены тегом .
By Ibrahim Diallo
Published Jul 2 2014 ~ 16 minutes readSearch is an important feature on a website. When my few readers want to look for a particular passage on my blog, they use the search box. It used to be powered by Google Search, but I have since then changed it to my own home-brewed version not because I can do better but because it was an interesting challenge.
If you are in a hurry and just want your site to be searchable, well do what I did before, use Google.
// In search.php file $term = isset($_GET["query"])?$_GET["query"]: ""; $term = urlencode($term); $website = urlencode("www.yourwebsite.com"); $redirect = "https://www.google.com/search?q=site%3A{$website}+{$term}"; header("Location: $redirect"); exit;
What it does is pretty simple. Get the term passed by the user, and forward it to Google search page. Limit the search result to our current domain using the site: keyword in the search query. All your pages that are indexed by Google will be available through search now. If you do want to handle your search in house however, then keep reading.
Homemade Search Solution
Before we go any further, try using the search box on this blog. It uses the same process that I will describe below. If you feel that this is what you want then please continue reading.
This solution is catered to small websites. I make use of LIKE with wild cards on both ends, meaning your search cannot be indexed. This means the solution will work fine for your blog or personal website that doesn"t contain tons of data. Port it to a bigger website and it might become very slow. MySQL offers Full Text Search which is not what we are doing here.
Note: If you have 5000 blog posts you are still fine. .
We will take the structure of this blog as a reference. Each blog post has:
- A title p_title
- A url p_url
- A summary p_summary
- A post content p_content
- And catergories category.tagname
For every field that matches with our search term, we will give it a score. The score will be based on the importance of the match:
// the exact term matches is found in the title $scoreFullTitle = 6; // match the title in part $scoreTitleKeyword = 5; // the exact term matches is found in the summary $scoreFullSummary = 5; // match the summary in part $scoreSummaryKeyword = 4; // the exact term matches is found in the content $scoreFullDocument = 4; // match the document in part $scoreDocumentKeyword = 3; // matches a category $scoreCategoryKeyword = 2; // matches the url $scoreUrlKeyword = 1;
Before we get started, there are a few words that do not contribute much to a search that should be removed. Example "in","it","a","the","of" ... . We will filter those out and feel free to add any word you think is irrelevant. Another thing is, we want to limit the length of our query. We don"t want a user to write a novel in the search field and crash our MySQL server.
// Remove unnecessary words from the search term and return them as an array function filterSearchKeys($query){ $query = trim(preg_replace("/(\s+)+/", " ", $query)); $words = array(); // expand this list with your words. $list = array("in","it","a","the","of","or","I","you","he","me","us","they","she","to","but","that","this","those","then"); $c = 0; foreach(explode(" ", $query) as $key){ if (in_array($key, $list)){ continue; } $words = $key; if ($c >= 15){ break; } $c++; } return $words; } // limit words number of characters function limitChars($query, $limit = 200){ return substr($query, 0,$limit); }
Our helper functions can now limit character count and filter useless words. The way we will implement our algorithm is by giving a score every time we find a match. We will match words using the if statement and accumulate points as we match more words. At the end we can use that score to sort our results
Note: I will not be showing how to connect to MySQL database. If you are having problems to efficiently connect to the database I recommend reading this .
Let"s give our function a structure first. Note I left placeholders so we can implement sections separately.
Function search($query){ $query = trim($query); if (mb_strlen($query)===0){ // no need for empty search right? return false; } $query = limitChars($query); // Weighing scores $scoreFullTitle = 6; $scoreTitleKeyword = 5; $scoreFullSummary = 5; $scoreSummaryKeyword = 4; $scoreFullDocument = 4; $scoreDocumentKeyword = 3; $scoreCategoryKeyword = 2; $scoreUrlKeyword = 1; $keywords = filterSearchKeys($query); $escQuery = DB::escape($query); // see note above to get db object $titleSQL = array(); $sumSQL = array(); $docSQL = array(); $categorySQL = array(); $urlSQL = array(); /** Matching full occurrences PLACE HOLDER **/ /** Matching Keywords PLACE HOLDER **/ $sql = "SELECT p.p_id,p.p_title,p.p_date_published,p.p_url, p.p_summary,p.p_content,p.thumbnail, ((-- Title score ".implode(" + ", $titleSQL).")+ (-- Summary ".implode(" + ", $sumSQL).")+ (-- document ".implode(" + ", $docSQL).")+ (-- tag/category ".implode(" + ", $categorySQL).")+ (-- url ".implode(" + ", $urlSQL).")) as relevance FROM post p WHERE p.status = "published" HAVING relevance >
In the query, all scores will be summed up as the relevance variable and we can use it to sort the results.
Matching full occurrences
We make sure we have some keywords first then add our query.
If (count($keywords) > 1){ $titleSQL = "if (p_title LIKE "%".$escQuery."%",{$scoreFullTitle},0)"; $sumSQL = "if (p_summary LIKE "%".$escQuery."%",{$scoreFullSummary},0)"; $docSQL = "if (p_content LIKE "%".$escQuery."%",{$scoreFullDocument},0)"; }
Those are the matches with higher score. If the search term matches an article that contains these, they will have higher chances of appearing on top.
Matching keywords occurrences
We loop through all keywords and check if they match any of the fields. For the category match, I used a sub-query since a post can have multiple categories.
Foreach($keywords as $key){ $titleSQL = "if (p_title LIKE "%".DB::escape($key)."%",{$scoreTitleKeyword},0)"; $sumSQL = "if (p_summary LIKE "%".DB::escape($key)."%",{$scoreSummaryKeyword},0)"; $docSQL = "if (p_content LIKE "%".DB::escape($key)."%",{$scoreDocumentKeyword},0)"; $urlSQL = "if (p_url LIKE "%".DB::escape($key)."%",{$scoreUrlKeyword},0)"; $categorySQL = "if ((SELECT count(category.tag_id) FROM category JOIN post_category ON post_category.tag_id = category.tag_id WHERE post_category.post_id = p.post_id AND category.name = "".DB::escape($key)."") > 0,{$scoreCategoryKeyword},0)"; }
Also as pointed by a commenter below, we have to make sure that the these variables are not empty arrays or the query will fail.
// Just incase it"s empty, add 0 if (empty($titleSQL)){ $titleSQL = 0; } if (empty($sumSQL)){ $sumSQL = 0; } if (empty($docSQL)){ $docSQL = 0; } if (empty($urlSQL)){ $urlSQL = 0; } if (empty($tagSQL)){ $tagSQL = 0; }
At the end the queries are all concatenated and added together to determine the relevance of the post to the search term.
// Remove unnecessary words from the search term and return them as an array function filterSearchKeys($query){ $query = trim(preg_replace("/(\s+)+/", " ", $query)); $words = array(); // expand this list with your words. $list = array("in","it","a","the","of","or","I","you","he","me","us","they","she","to","but","that","this","those","then"); $c = 0; foreach(explode(" ", $query) as $key){ if (in_array($key, $list)){ continue; } $words = $key; if ($c >= 15){ break; } $c++; } return $words; } // limit words number of characters function limitChars($query, $limit = 200){ return substr($query, 0,$limit); } function search($query){ $query = trim($query); if (mb_strlen($query)===0){ // no need for empty search right? return false; } $query = limitChars($query); // Weighing scores $scoreFullTitle = 6; $scoreTitleKeyword = 5; $scoreFullSummary = 5; $scoreSummaryKeyword = 4; $scoreFullDocument = 4; $scoreDocumentKeyword = 3; $scoreCategoryKeyword = 2; $scoreUrlKeyword = 1; $keywords = filterSearchKeys($query); $escQuery = DB::escape($query); // see note above to get db object $titleSQL = array(); $sumSQL = array(); $docSQL = array(); $categorySQL = array(); $urlSQL = array(); /** Matching full occurences **/ if (count($keywords) > 1){ $titleSQL = "if (p_title LIKE "%".$escQuery."%",{$scoreFullTitle},0)"; $sumSQL = "if (p_summary LIKE "%".$escQuery."%",{$scoreFullSummary},0)"; $docSQL = "if (p_content LIKE "%".$escQuery."%",{$scoreFullDocument},0)"; } /** Matching Keywords **/ foreach($keywords as $key){ $titleSQL = "if (p_title LIKE "%".DB::escape($key)."%",{$scoreTitleKeyword},0)"; $sumSQL = "if (p_summary LIKE "%".DB::escape($key)."%",{$scoreSummaryKeyword},0)"; $docSQL = "if (p_content LIKE "%".DB::escape($key)."%",{$scoreDocumentKeyword},0)"; $urlSQL = "if (p_url LIKE "%".DB::escape($key)."%",{$scoreUrlKeyword},0)"; $categorySQL = "if ((SELECT count(category.tag_id) FROM category JOIN post_category ON post_category.tag_id = category.tag_id WHERE post_category.post_id = p.post_id AND category.name = "".DB::escape($key)."") > 0,{$scoreCategoryKeyword},0)"; } // Just incase it"s empty, add 0 if (empty($titleSQL)){ $titleSQL = 0; } if (empty($sumSQL)){ $sumSQL = 0; } if (empty($docSQL)){ $docSQL = 0; } if (empty($urlSQL)){ $urlSQL = 0; } if (empty($tagSQL)){ $tagSQL = 0; } $sql = "SELECT p.p_id,p.p_title,p.p_date_published,p.p_url, p.p_summary,p.p_content,p.thumbnail, ((-- Title score ".implode(" + ", $titleSQL).")+ (-- Summary ".implode(" + ", $sumSQL).")+ (-- document ".implode(" + ", $docSQL).")+ (-- tag/category ".implode(" + ", $categorySQL).")+ (-- url ".implode(" + ", $urlSQL).")) as relevance FROM post p WHERE p.status = "published" HAVING relevance > 0 ORDER BY relevance DESC,p.page_views DESC LIMIT 25"; $results = DB::query($sql); if (!$results){ return false; } return $results; }
Now your search.php file can look like this:
$term = isset($_GET["query"])?$_GET["query"]: ""; $search_results = search($term); if (!$search_results) { echo "No results"; exit; } // Print page with results here.
We created a simple search algorithm that can handle a fair amount of content. I arbitrarily chose the score for each match, feel free to tweak it to something that works best for you. And there is always room for improvement.
It is a good idea to track the search term coming from your users, this way you can see if most users search for the same thing. If there is a pattern, then you can save them a trip and just cache the results using Memcached .
If you want to see this search algorithm in action, go ahead and try looking for an article on the search box on top of the page. I have added extra features like returning the part where the match was found in the text. Feel free to add features to yours.
Did you like this article? You can subscribe to read more awesome ones. .
On a related note, here are some interesting articles.
Making your own website shouldn"t be too difficult. Hosting companies like Godaddy or Hostgator make it super easy for anyone to get started; they allow you to create a whole website without ever writing code. For most people, it is plenty to run a WordPress blog. If this is what you are looking for you should head to Godaddy.com right now. We are done here. But on the other hand, if you want to have control and not be limited by the short comings of a shared hosting without busting your wallet, you have come to the right place.
Vim is my favorite text editor on the terminal. After playing for a little while with nano and emacs , I finally settled with vim for its simplicity (bare with me please). Although it can be customized and used like an entire IDE, I use it mostly for editing files on my servers and making small but crucial changes. Let"s not get into Editor war and get started.
Experienced developers are expensive. In a world where cutting cost seems like the best option, companies try to maximize their profit by spending less and less on good talent. It is much cheaper to hire someone who just learned php a few weeks ago then a seasoned developer. But it becomes a very bad investment when the newbie introduces insecure code. The problem is, a lot of things learned from those LAMP CRUD application tutorial do not focus much on security. When this code is introduced to a commercial application, the damage can be very expensive. I like how stackoverflow users are fighting very hard to eradicate SQL injection , but it seems like it is much easier to find insecure code on-line. That said, I will attempt to scare you off your feet so you know better what is the cost of SQL injection.
Comments(45)
Zaryel Aug 12 2015:
Ian Mustafa Sep 26 2015:
Rob Sep 29 2015:
adeem Feb 11 2016:
Ivan Venediktov Apr 9 2016.
Updated on April 30, 2016
I"m going to show you how to create simple search using PHP and MySQL. You"ll learn:
- How to use GET and POST methods
- Connect to database
- Communicate with database
- Find matching database entries with given word or phrase
- Display results
Preparation
You should have Apache, MySQL and PHP installed and running of course (you can use for different platforms or WAMP for windows, MAMP for mac) or a web server/hosting that supports PHP and MySQL databases.
Let"s create database, table and fill it with some entries we can use for search:
- Go to phpMyAdmin, if you have server on your computer you can access it at http://localhost/phpmyadmin/
- Create database, I called mine tutorial_search
- Create table I used 3 fields, I called mine articles.
- Configuration for 1st field. Name: id, type: INT, check AUTO_INCREMENT, index: primary
INT means it"s integer
AUTO_INCREMENT means that new entries will have other(higher) number than previous
Index: primary means that it"s unique key used to identify row
- 2nd field: Name: title, type: VARCHAR, length: 225
VARCHAR means it string of text, maximum 225 characters(it is required to specify maximum length), use it for titles, names, addresses
length means it can"t be longer than 225 characters(you can set it to lower number if you want)
- 3rd field: Name: text, type: TEXT
TEXT means it"s long string, it"s not necessary to specify length, use it for long text.

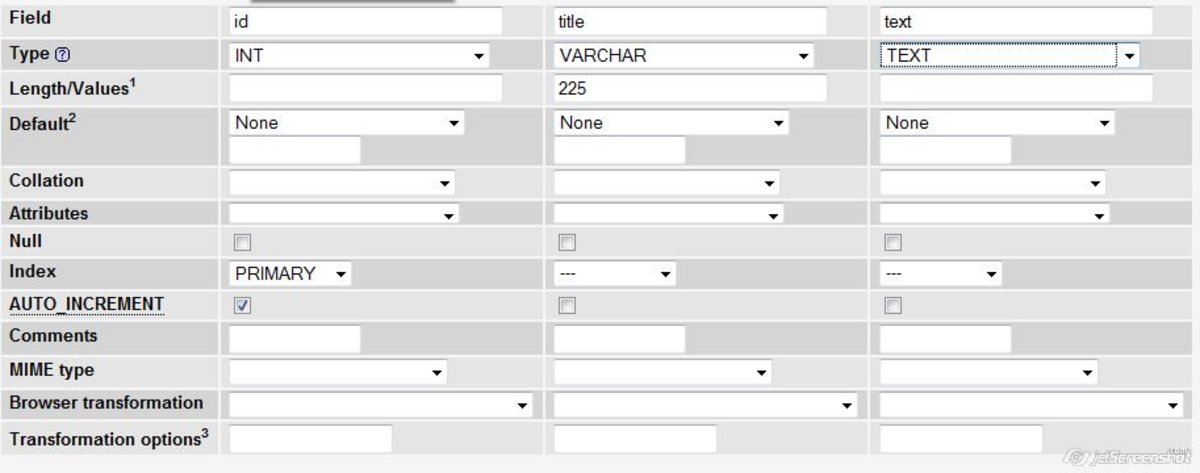
- Fill the table with some random articles(you can find them on news websites, for example: CNN, BBC, etc.). Click insert on the top menu and copy text to a specific fields. Leave "id" field empty. Insert at least three.
It should look something like this:

- Create a folder in your server directory and two files: index.php and search.php (actually we can do all this just with one file, but let"s use two, it will be easier)
- Fill them with default html markup, doctype, head, etc.
- Create a form with search field and submit button in index.php, you can use GET or POST method, set action to search.php. I used "query" as name for text field
GET - means your information will be stored in url (http://localhost/tutorial_search/search.php?query=yourQuery
)
POST - means your information won"t be displayed it is used for passwords, private information, much more secure than GET
Ok, let"s get started with php.
- Open search.php
- Start php ()
- Connect to a database(read comments in following code)
< to > $query = mysql_real_escape_string($query); // makes sure nobody uses SQL injection $raw_results = mysql_query("SELECT * FROM articles WHERE (`title` LIKE "%".$query."%") OR (`text` LIKE "%".$query."%")") or die(mysql_error()); // * means that it selects all fields, you can also write: `id`, `title`, `text` // articles is the name of our table // "%$query%" is what we"re looking for, % means anything, for example if $query is Hello // it will match "hello", "Hello man", "gogohello", if you want exact match use `title`="$query" // or if you want to match just full word so "gogohello" is out use "% $query %" ...OR ... "$query %" ... OR ... "% $query" if(mysql_num_rows($raw_results) >
".$results["title"]."
".$results["text"].""; // posts results gotten from database(title and text) you can also show id ($results["id"]) } } else{ // if there is no matching rows do following echo "No results"; } } else{ // if query length is less than minimum echo "Minimum length is ".$min_length; } ?>Done!
Now it works. Try different words, variations, editing code, experiment. I"m adding full code of both files in case you think you"ve missed something. Feel free to ask questions or ask for tutorials.
index.php
search.php






