Компьютерная нейросеть. Нейросети для начинающих – нейронная сеть для чайников. Так что же такое классное мы только что сделали
Всем привет!
Буквально вчера нашел книгу Тарика Рашида «Создай свою нейросеть». Книга является бестселлером (топ 1 продаж) в разделе «Искусственный интеллект». Книга свежая, вышла в прошлом году.
Впечатления от первых разделов замечательные. Одно из лучших введений в сферу нейросетей из всех мною виденных. Книга мне так понравилась, что я решил перевести ее на русский язык и выкладывать сюда в виде статей. Часть материала из книги пойдет на улучшение уже существующих глав, часть на следующие.
Перевел уже два первых раздела 1 главы. Вы можете этих разделов.
Читайте - наслаждайтесь!
1 Глава. Как они работают.
1.1 Легко для меня, тяжело для тебя
Все компьютеры являются калькуляторами в душе. Они умеют очень быстро считать.
Не стоит их в этом упрекать. Они отлично выполняют свою работу: считают цену с учетом скидки, начисляют долговые проценты, рисуют графики по имеющимся данным и так далее.
Даже просмотр телевизора или прослушивание музыки с помощью компьютера представляют собой выполнение огромного количества арифметических операций снова и снова. Это может прозвучать удивительно, но отрисовка каждого кадра изображения из нулей и единиц, полученных через интернет задействует вычисления, которые не сильно сложнее тех задач, которые мы все решали в школе.
Однако, способность компьютера складывать тысячи и миллионы чисел в секунду вовсе не является искусственным интеллектом. Человеку сложно так быстро складывать числа, но согласитесь, что эта работа не требует серьезных интеллектуальных затрат. Надо придерживаться заранее известного алгоритма по складыванию чисел и ничего более. Именно этим и занимаются все компьютеры - придерживаются четкого алгоритма.
С компьютерами все ясно. Теперь давайте поговорим о том, в чем мы хороши по сравнению с ними.
Посмотрите на картинки ниже и определите, что на них изображено:

Вы видите лица людей на первой картинке, морду кошки на второй и дерево на третьей. Вы распознали объекты на этих картинках. Заметьте, что вам хватило лишь взгляда, чтобы безошибочно понять, что на них изображено. Мы редко ошибаемся в таких вещах.
Мы мгновенно и без особого труда воспринимаем огромное количество информации, которое содержат изображения и очень точно определяем объекты на них. А вот для любого компьютера такая задача встанет поперек горла.
У любого компьютера вне зависимости от его сложности и быстроты нет одного важного качества - интеллекта, которым обладает каждый человек.
Но мы хотим научить компьютеры решать подобные задачи, потому что они быстрые и не устают. Искусственный интеллект как раз занимается решением подобного рода задач.
Конечно компьютеры и дальше будут состоять из микросхем. Задача искусственного интеллекта - найти новые алгоритмы работы компьютера, которые позволят решать интеллектуальные задачи. Эти алгоритмы не всегда идеальны, но они решают поставленные задачи и создают впечатление, что компьютер ведет себя как человек.
Ключевые моменты
- Есть задачи легкие для обычных компьютеров, но вызывающие трудности и людей. Например, умножение миллиона чисел друг на друга.
- С другой стороны, существуют не менее важные задачи, которые невероятно сложны для компьютера и не вызывают проблем у людей. Например, распознавание лиц на фотографиях.
1.2 Простая предсказательная машина
Давайте начнем с чего-нибудь очень простого. Дальше мы будет отталкиваться от материала, изученного в этом разделе.
Представьте себе машину, которая получает вопрос, «обдумывает» его и затем выдает ответ. В примере выше вы получали картинку на вход, анализировали ее с помощью мозгов и делали вывод об объекте, который на ней изображен. Выглядит это как-то так:

Компьютеры на самом деле ничего не «обдумывают». Они просто применяют заранее известные арифметические операции. Поэтому давайте будем называть вещи своими именами:

Компьютер принимает какие-то данные на вход, производит необходимые вычисления и выдает готовый результат. Рассмотрим следующий пример. Если на вход компьютеру поступает выражение \(3 \times 4 \) , то оно преобразуется в более простую последовательность сложений. Как итог, получаем результат - 12.

Выглядит не слишком впечатляюще. Это нормально. С помощью этих тривиальных примеров вы увидите идею, которую реализуют нейросети.
Теперь представьте себе машину, которая преобразует километры в мили:

Теперь представьте, что мы не знаем формулу, с помощью которой километры переводятся в мили. Мы знаем только, что зависимость между двумя этими величинами линейная . Это означает, что если мы в два раза увеличим дистанцию в милях, то дистанция в километрах тоже увеличится в два раза. Это интуитивно понятно. Вселенная была бы очень странной, если бы это правило не выполнялось.
Линейная зависимость между километрами и милями дает нам подсказку, в какой форме надо преобразовывать одну величину в другую. Мы можем представить эту зависимость так:
\[ \text{мили} = \text{километры} \times C \]
В выражении выше \(C \) выступает в роли некоторого постоянного числа - константы. Пока мы не знаем, чему равно \(C \) .
Единственное, что нам известно - несколько заранее верно отмеренных расстояний в километрах и милях.
И как же узнать значение \(C \) ? А давайте просто придумаем случайное число и скажем, что ему-то и равна наша константа. Пусть \(C = 0.5 \) . Что же произойдет?

Принимая, что \(C = 0.5 \) мы из 100 километров получаем 50 миль. Это отличный результат принимая во внимания тот факт, что \(C = 0.5 \) мы выбрали совершенно случайно! Но мы знаем, что наш ответ не совсем верен, потому что согласно таблице верных замеров мы должны были получить 62.137 мили.
Мы промахнулись на 12.137 миль. Это наша погрешность - разница между полученным ответом и заранее известным правильным результатом, который в данном случае мы имеем в таблице.
\[ \begin{gather*} \text{погрешность} = \text{правильное значение} — \text{полученный ответ} \\ = 62.137 — 50 \\ = 12.137 \end{gather*} \]

Вновь смотрим на погрешность. Полученное расстояние короче на 12.137. Так как формула по переводу километров в мили линейная (\(\text{мили} = \text{километры} \times C \) ), то увеличение значения \(C \) увеличит и выходной результат в милях.
Давайте теперь примем, что \(C = 0.6 \) и посмотрим, что произойдет.
Так как \(C=0.6 \) , то для 100 километров имеем \(100 \times 0.6 = 60 \) миль. Это гораздо лучше предыдущей попытки (в тот раз было 50 миль)! Теперь наша погрешность очень мала - всего 2.137 мили. Вполне себе точный результат.

Теперь обратите внимание на то, как мы использовали полученную погрешность для корректировки значения константы \(C \) . Нам нужно было увеличить выходное число миль и мы немного увеличили значение \(C \) . Заметьте, что мы не используем алгебру для получения точного значения \(C \) , а ведь мы могли бы. Почему? Потому что на свете полно задач, которые не имеют простой математической связи между полученным входом и выдаваемым результатом.
Именно для задач, которые практически не решаются простым подсчетом нам и нужны такие изощренные штуки, как нейронные сети.

Боже мой! Мы хватанули слишком много и превысили правильный результат. Наша предыдущая погрешность равнялась 2.137, а теперь она равна -7.863. Минус означает, что наш результат оказался больше правильного ответа, так как погрешность вычисляется как правильный ответ — (минус) полученный ответ.
Получается, что при \(C=0.6 \) мы имеем гораздо более точный выход. На этом можно было бы и закончить. Но давайте все же увеличим \(C \) , но не сильно! Пусть \(C=0.61 \) .

Так-то лучше! Наша машина выдает 61 милю, что всего на 1.137 милю меньше, чем правильный ответ (62.137).
Из этой ситуации с превышением правильного ответа надо вынести важный урок. По мере приближения к правильному ответу параметры машины стоит менять все слабее и слабее. Это поможет избежать неприятных ситуаций, которые приводят к превышению правильного ответа.
Величина нашей корректировки \(C \) зависит от погрешности. Чем больше наша погрешность, тем более сильно мы меняем значение \(C \) . Но когда погрешность становиться маленькой, необходимо менять \(C \) по чуть-чуть. Логично, не так ли?
Верьте или нет, но только что вы поняли самую суть работы нейронных сетей. Мы тренируем «машины» постепенно выдавать все более и более точный результат.
Важно понимать и то, как мы решали эту задачу. Мы не решали ее в один заход, хотя в данном случае так можно было бы поступить. Вместо этого, мы приходили к правильному ответу по шагам так, что с каждым шагом наши результаты становились лучше.
Не правда ли объяснения очень простые и понятные? Лично я не встречал более лаконичного способа объяснить, что такое нейросети.
Если вам что-то непонятно, задавайте вопросы на форуме.
Мне важно ваше мнение - оставляйте комментарии 🙂
В закладки
Рассказываем, как за несколько шагов создать простую нейронную сеть и научить её узнавать известных предпринимателей на фотографиях.
Шаг 0. Разбираемся, как устроены нейронные сети
Проще всего разобраться с принципами работы нейронных сетей можно на примере Teachable Machine - образовательного проекта Google.
В качестве входящих данных - то, что нужно обработать нейронной сети - в Teachable Machine используется изображение с камеры ноутбука. В качестве выходных данных - то, что должна сделать нейросеть после обработки входящих данных - можно использовать гифку или звук.
Например, можно научить Teachable Machine при поднятой вверх ладони говорить «Hi». При поднятом вверх большом пальце - «Cool», а при удивленном лице с открытым ртом - «Wow».
Для начала нужно обучить нейросеть. Для этого поднимаем ладонь и нажимаем на кнопку «Train Green» - сервис делает несколько десятков снимков, чтобы найти на изображениях закономерность. Набор таких снимков принято называть «датасетом».
Теперь остается выбрать действие, которое нужно вызывать при распознании образа - произнести фразу, показать GIF или проиграть звук. Аналогично обучаем нейронную сеть распознавать удивленное лицо и большой палец.
Как только нейросеть обучена, её можно использовать. Teachable Machine показывает коэффициент «уверенности» - насколько система «уверена», что ей показывают один из навыков.
Кроткое видео о работе Teachable Machine
Шаг 1. Готовим компьютер к работе с нейронной сетью
Теперь сделаем свою нейронную сеть, которая при отправке изображения будет сообщать о том, что изображено на картинке. Сначала научим нейронную сеть распознавать цветы на картинке: ромашку, подсолнух, одуванчик, тюльпан или розу.
Для создания собственной нейронной сети понадобится Python - один из наиболее минималистичных и распространенных языков программирования, и TensorFlow - открытая библиотека Google для создания и тренировки нейронных сетей.
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.
Линейная функция
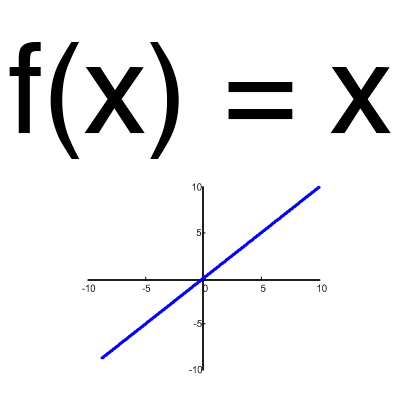
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно
не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.

Root MSE


Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.

Решение
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Что такое нейрон смещения?

Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов - нейрон смещения. Нейрон смещения или bias нейрон - это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов - со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост - нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:
- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Об Rprop и ГА речь пойдет в других статьях, а сейчас мы с вами посмотрим на основу основ - метод обратного распространения, который использует алгоритм градиентного спуска.
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у - ошибка соответствующая этому весу(e).

Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум - точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку - e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой - локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:

Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?

Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:

А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1. Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148δH1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом: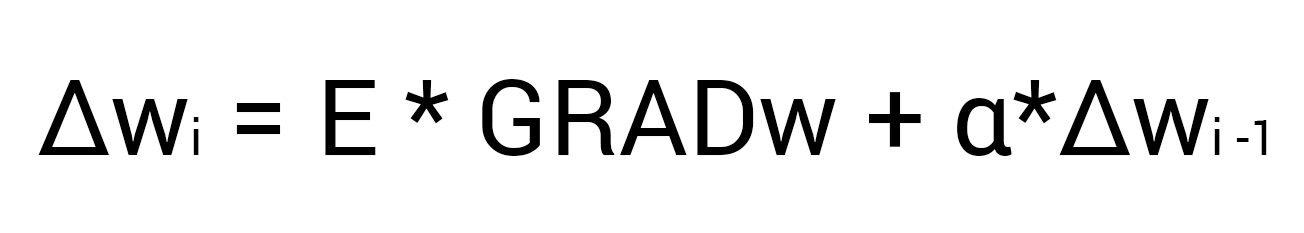
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, α (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).
Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры - это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:
- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
В других типах НС присутствуют дополнительные гиперпараметры, но о них мы говорить не будем. Подбор верных гиперпараметров очень важен и будет напрямую влиять на сходимость вашей НС. Понять стоит ли использовать нейроны смещения или нет достаточно просто. Количество скрытых слоев и нейронов в них можно вычислить перебором основываясь на одном простом правиле - чем больше нейронов, тем точнее результат и тем экспоненциально больше время, которое вы потратите на ее обучение. Однако стоит помнить, что не стоит делать НС с 1000 нейронов для решения простых задач. А вот с выбором момента и скорости обучения все чуточку сложнее. Эти гиперпараметры будут варьироваться, в зависимости от поставленной задачи и архитектуры НС. Например, для решения XOR скорость обучения может быть в пределах 0.3 - 0.7, но в НС которая анализирует и предсказывает цену акций, скорость обучения выше 0.00001 приводит к плохой сходимости НС. Не стоит сейчас заострять свое внимание на гиперпараметрах и пытаться досконально понять, как же их выбирать. Это придет с опытом, а пока что советую просто экспериментировать и искать примеры решения той или иной задачи в сети.
Что такое сходимость?

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх - вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.

Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Искусственная нейронная сеть — совокупность нейронов, взаимодействующих друг с другом. Они способны принимать, обрабатывать и создавать данные. Это настолько же сложно представить, как и работу человеческого мозга. Нейронная сеть в нашем мозгу работает для того, чтобы вы сейчас могли это прочитать: наши нейроны распознают буквы и складывают их в слова.
Искусственная нейронная сеть - это подобие мозга. Изначально она программировалась с целью упростить некоторые сложные вычислительные процессы. Сегодня у нейросетей намного больше возможностей. Часть из них находится у вас в смартфоне. Ещё часть уже записала себе в базу, что вы открыли эту статью. Как всё это происходит и для чего, читайте далее.
С чего всё началось
Людям очень хотелось понять, откуда у человека разум и как работает мозг. В середине прошлого века канадский нейропсихолог Дональд Хебб это понял. Хебб изучил взаимодействие нейронов друг с другом, исследовал, по какому принципу они объединяются в группы (по-научному - ансамбли) и предложил первый в науке алгоритм обучения нейронных сетей.
Спустя несколько лет группа американских учёных смоделировала искусственную нейросеть, которая могла отличать фигуры квадратов от остальных фигур.
Как же работает нейросеть?
Исследователи выяснили, нейронная сеть - это совокупность слоёв нейронов, каждый из которых отвечает за распознавание конкретного критерия: формы, цвета, размера, текстуры, звука, громкости и т. д. Год от года в результате миллионов экспериментов и тонн вычислений к простейшей сети добавлялись новые и новые слои нейронов. Они работают по очереди. Например, первый определяет, квадрат или не квадрат, второй понимает, квадрат красный или нет, третий вычисляет размер квадрата и так далее. Не квадраты, не красные и неподходящего размера фигуры попадают в новые группы нейронов и исследуются ими.
Какими бывают нейронные сети и что они умеют
Учёные развили нейронные сети так, что те научились различать сложные изображения, видео, тексты и речь. Типов нейронных сетей сегодня очень много. Они классифицируются в зависимости от архитектуры - наборов параметров данных и веса этих параметров, некой приоритетности. Ниже некоторые из них.
Свёрточные нейросети
Нейроны делятся на группы, каждая группа вычисляет заданную ей характеристику. В 1993 году французский учёный Ян Лекун показал миру LeNet 1 - первую свёрточную нейронную сеть, которая быстро и точно могла распознавать цифры, написанные на бумаге от руки. Смотрите сами:
Сегодня свёрточные нейронные сети используются в основном с мультимедиными целями: они работают с графикой, аудио и видео.
Рекуррентные нейросети
Нейроны последовательно запоминают информацию и строят дальнейшие действия на основе этих данных. В 1997 году немецкие учёные модифицировали простейшие рекуррентные сети до сетей с долгой краткосрочной памятью. На их основе затем были разработаны сети с управляемыми рекуррентными нейронами.
Сегодня с помощью таких сетей пишутся и переводятся тексты, программируются боты, которые ведут осмысленные диалоги с человеком, создаются коды страниц и программ.
Использование такого рода нейросетей - это возможность анализировать и генерировать данные, составлять базы и даже делать прогнозы.
В 2015 году компания SwiftKey выпустила первую в мире клавиатуру, работающую на рекуррентной нейросети с управляемыми нейронами. Тогда система выдавала подсказки в процессе набранного текста на основе последних введённых слов. В прошлом году разработчики обучили нейросеть изучать контекст набираемого текста, и подсказки стали осмысленными и полезными:

Комбинированные нейросети (свёрточные + рекуррентные)
Такие нейронные сети способны понимать, что находится на изображении, и описывать это. И наоборот: рисовать изображения по описанию. Ярчайший пример продемонстрировал Кайл Макдональд, взяв нейронную сеть на прогулку по Амстердаму. Сеть мгновенно определяла, что находится перед ней. И практически всегда точно:

Нейросети постоянно самообучаются. Благодаря этому процессу:
1. Skype внедрил возможность синхронного перевода уже для 10 языков. Среди которых, на минуточку, есть русский и японский - одни из самых сложных в мире. Конечно, качество перевода требует серьёзной доработки, но сам факт того, что уже сейчас вы можете общаться с коллегами из Японии по-русски и быть уверенными, что вас поймут, вдохновляет.
2. Яндекс на базе нейронных сетей создал два поисковых алгоритма: «Палех» и «Королёв». Первый помогал найти максимально релевантные сайты для низкочастотных запросов. «Палех» изучал заголовки страниц и сопоставлял их смысл со смыслом запросов. На основе «Палеха» появился «Королёв». Этот алгоритм оценивает не только заголовок, но и весь текстовый контент страницы. Поиск становится всё точнее, а владельцы сайтов разумнее начинают подходить к наполнению страниц.
3. Коллеги сеошников из Яндекса создали музыкальную нейросеть: она сочиняет стихи и пишет музыку. Нейрогруппа символично называется Neurona, и у неё уже есть первый альбом:

4. У Google Inbox с помощью нейросетей осуществляется ответ на сообщение. Развитие технологий идет полный ходом, и сегодня сеть уже изучает переписку и генерирует возможные варианты ответа. Можно не тратить время на печать и не бояться забыть какую-нибудь важную договорённость.

5. YouTube использует нейронные сети для ранжирования роликов, причём сразу по двум принципам: одна нейронная сеть изучает ролики и реакции аудитории на них, другая проводит исследование пользователей и их предпочтений. Именно поэтому рекомендации YouTube всегда в тему.
6. Facebook активно работает над DeepText AI - программой для коммуникаций, которая понимает жаргон и чистит чатики от обсценной лексики.
7. Приложения вроде Prisma и Fabby, созданные на нейросетях, создают изображения и видео:

Colorize восстанавливает цвета на чёрно-белых фото (удивите бабушку!).

MakeUp Plus подбирает для девушек идеальную помаду из реального ассортимента реальных брендов: Bobbi Brown, Clinique, Lancome и YSL уже в деле.

8.
Apple и Microsoft постоянно апгрейдят свои нейронные Siri и Contana. Пока они только исполняют наши приказы, но уже в ближайшем будущем начнут проявлять инициативу: давать рекомендации и предугадывать наши желания.
А что ещё нас ждет в будущем?
Самообучающиеся нейросети могут заменить людей: начнут с копирайтеров и корректоров. Уже сейчас роботы создают тексты со смыслом и без ошибок. И делают это значительно быстрее людей. Продолжат с сотрудниками кол-центров, техподдержки, модераторами и администраторами пабликов в соцсетях. Нейронные сети уже умеют учить скрипт и воспроизводить его голосом. А что в других сферах?
Аграрный сектор
Нейросеть внедрят в спецтехнику. Комбайны будут автопилотироваться, сканировать растения и изучать почву, передавая данные нейросети. Она будет решать - полить, удобрить или опрыскать от вредителей. Вместо пары десятков рабочих понадобятся от силы два специалиста: контролирующий и технический.
Медицина
В Microsoft сейчас активно работают над созданием лекарства от рака. Учёные занимаются биопрограммированием - пытаются оцифрить процесс возникновения и развития опухолей. Когда всё получится, программисты смогут найти способ заблокировать такой процесс, по аналогии будет создано лекарство.
Маркетинг
Маркетинг максимально персонализируется. Уже сейчас нейросети за секунды могут определить, какому пользователю, какой контент и по какой цене показать. В дальнейшем участие маркетолога в процессе сведётся к минимуму: нейросети будут предсказывать запросы на основе данных о поведении пользователя, сканировать рынок и выдавать наиболее подходящие предложения к тому моменту, как только человек задумается о покупке.
Ecommerce
Ecommerce будет внедрён повсеместно. Уже не потребуется переходить в интернет-магазин по ссылке: вы сможете купить всё там, где видите, в один клик. Например, читаете вы эту статью через несколько лет. Очень вам нравится помада на скрине из приложения MakeUp Plus (см. выше). Вы кликаете на неё и попадаете сразу в корзину. Или смотрите видео про последнюю модель Hololens (очки смешанной реальности) и тут же оформляете заказ прямо из YouTube.
Едва ли не в каждой области будут цениться специалисты со знанием или хотя бы пониманием устройства нейросетей, машинного обучения и систем искусственного интеллекта. Мы будем существовать с роботами бок о бок. И чем больше мы о них знаем, тем спокойнее нам будет жить.
P. S.
Зинаида Фолс - нейронная сеть Яндекса, пишущая стихи. Оцените произведение, которое машина написала, обучившись на Маяковском (орфография и пунктуация сохранены):
« Это »
это
всего навсего
что-то
в будущем
и мощь
у того человека
есть на свете все или нет
это кровьа вокруг
по рукам
жиреет
слава у
земли
с треском в клюве
Впечатляет, правда?
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется методом обратного распространения ошибки .
Вкратце: вы оцениваете, насколько сеть ошиблась, и изменяете вес входных значений (синие числа на первой картинке).
Процесс идёт от конца к началу, так как мы начинаем с конца сети (смотрим, насколько отклоняется от истины догадка сети) и двигаемся назад, изменяя по пути веса, пока не дойдём до ввода. Для вычисления всего этого вручную потребуются знания матанализа. Khan Academy предоставляет хорошие курсы по матанализу, но я изучал его в университете. Также можно не заморачиваться и воспользоваться библиотеками, которые посчитают весь матан за вас.
Скриншот из руководства Мэтта Мазура по методу обратного распространения ошибки.
Вот три источника, которые помогли мне разобраться в этом методе:
В процессе прочтения первых двух статей вам обязательно нужно кодить самим, это поможет вам в дальнейшем. Да и вообще, в нейронных сетях нельзя как следует разобраться, если пренебречь практикой. Третья статья тоже классная, но это скорее энциклопедия, поскольку она размером с целую книгу. Она содержит подробные объяснения всех важных принципов работы нейронных сетей. Эти статьи также помогут вам изучить такие понятия, как функция стоимости и градиентный спуск.
Шаг 4. Создание своей нейронной сети
При прочтении различных статей и руководств вы так или иначе будете писать маленькие нейронные сети. Рекомендую именно так и делать, поскольку это - очень эффективный метод обучения.
Ещё одной полезной статьёй оказалась






