Etsi alimerkkijonoa tekstistä (merkkijono). Raaka voima -algoritmi. Katso, mitä "raaka voimamenetelmä" on muissa sanakirjoissa
Algoritmien kehittämismenetelmät n Raaka voima -menetelmä ("raaka voima") n Hajotusmenetelmä n Ongelman koon pienennysmenetelmä n Muunnosmenetelmä n Dynaaminen ohjelmointi n Ahneet menetelmät n Haun vähentämismenetelmät n ... © T. A. Pavlovskaya (SPb NRU ITMO) 1

 Raaka voima -menetelmä n Suora lähestymistapa ongelman ratkaisemiseen, joka perustuu yleensä suoraan ongelman lauseeseen ja sen käyttämien käsitteiden määritelmiin Esimerkki: luvun potenssin laskeminen kertomalla 1 tällä luvulla n kertaa n Soveltuu melkein mihin tahansa ongelmaan n Usein osoittautuu helpoimmaksi käyttää n tuottaa harvoin kauniita ja tehokkaita algoritmeja n Tehokkaamman algoritmin kehittämisen kustannukset voivat olla kohtuuttomia, jos vain muutama ongelma on ratkaistava n Voi olla hyödyllistä pienten tapausten ratkaisemisessa ongelmasta. n Voi toimia mittarina muiden algoritmien tehokkuuden määrittämisessä ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 3
Raaka voima -menetelmä n Suora lähestymistapa ongelman ratkaisemiseen, joka perustuu yleensä suoraan ongelman lauseeseen ja sen käyttämien käsitteiden määritelmiin Esimerkki: luvun potenssin laskeminen kertomalla 1 tällä luvulla n kertaa n Soveltuu melkein mihin tahansa ongelmaan n Usein osoittautuu helpoimmaksi käyttää n tuottaa harvoin kauniita ja tehokkaita algoritmeja n Tehokkaamman algoritmin kehittämisen kustannukset voivat olla kohtuuttomia, jos vain muutama ongelma on ratkaistava n Voi olla hyödyllistä pienten tapausten ratkaisemisessa ongelmasta. n Voi toimia mittarina muiden algoritmien tehokkuuden määrittämisessä ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 3
 n Esimerkki: valinta ja kuplalajittelu 28 -5 ©T A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 16 0 29 3 -4 56 4
n Esimerkki: valinta ja kuplalajittelu 28 -5 ©T A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 16 0 29 3 -4 56 4
 Kattava haku on raa'an voiman lähestymistapa kombinatorisiin ongelmiin. Siinä: n generoidaan kaikki mahdolliset elementit ongelmanmäärittelyalueelta n valitaan ne, jotka täyttävät ongelmaehdon asettamat rajoitukset n etsitään haluttu elementti (esimerkiksi ongelman tavoitefunktion arvon optimointi). Esimerkkejä: Matkamyyjän ongelma: etsi lyhin polku Tarkastele tietyn n kohteen joukon kaikkia osajoukkoja, annettuja N kaupunkia, niin että jokaisessa vieraillussa kaupungissa lasketaan vain kunkin niiden kokonaispaino hyväksyttävyyden määrittämiseksi, kerran ja lopullinen kohde on alkuperäinen. valitse kelvollisesta osajoukosta, jolla on enimmäispaino. n Hanki kaikki mahdolliset reitit generoimalla kaikki Reppu-ongelmat: annetaan N tietyn painoista tuotetta ja sellaisen repun hinta, joka kestää painon W. Lataa reppu n - 1 välikaupungin permutaatioilla laskemalla maksimikustannuksilla. vastaavien polkujen pituus ja lyhimmän löytäminen. Nämä ovat NP-kovia ongelmia (ei ole tunnettua algoritmia, joka ratkaisee ne polynomiajassa). n ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 5
Kattava haku on raa'an voiman lähestymistapa kombinatorisiin ongelmiin. Siinä: n generoidaan kaikki mahdolliset elementit ongelmanmäärittelyalueelta n valitaan ne, jotka täyttävät ongelmaehdon asettamat rajoitukset n etsitään haluttu elementti (esimerkiksi ongelman tavoitefunktion arvon optimointi). Esimerkkejä: Matkamyyjän ongelma: etsi lyhin polku Tarkastele tietyn n kohteen joukon kaikkia osajoukkoja, annettuja N kaupunkia, niin että jokaisessa vieraillussa kaupungissa lasketaan vain kunkin niiden kokonaispaino hyväksyttävyyden määrittämiseksi, kerran ja lopullinen kohde on alkuperäinen. valitse kelvollisesta osajoukosta, jolla on enimmäispaino. n Hanki kaikki mahdolliset reitit generoimalla kaikki Reppu-ongelmat: annetaan N tietyn painoista tuotetta ja sellaisen repun hinta, joka kestää painon W. Lataa reppu n - 1 välikaupungin permutaatioilla laskemalla maksimikustannuksilla. vastaavien polkujen pituus ja lyhimmän löytäminen. Nämä ovat NP-kovia ongelmia (ei ole tunnettua algoritmia, joka ratkaisee ne polynomiajassa). n ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 5

 Hajotusmenetelmä Se on myös "hajota ja hallitse" -menetelmä: n Tehtävän ilmentymä jaetaan useisiin pienempiin saman tehtävän esiintymiin, mieluiten samankokoisiin. n Pienemmät ongelman esiintymät ratkaistaan (yleensä rekursiivisesti, vaikka joskus käytetään jotain muuta algoritmia pienempiin instansseihin). n Tarvittaessa ratkaisu alkuperäiseen ongelmaan löydetään yhdistämällä pienempien tapausten ratkaisuja. Hajotusmenetelmä on ihanteellinen rinnakkaislaskentaan. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 7
Hajotusmenetelmä Se on myös "hajota ja hallitse" -menetelmä: n Tehtävän ilmentymä jaetaan useisiin pienempiin saman tehtävän esiintymiin, mieluiten samankokoisiin. n Pienemmät ongelman esiintymät ratkaistaan (yleensä rekursiivisesti, vaikka joskus käytetään jotain muuta algoritmia pienempiin instansseihin). n Tarvittaessa ratkaisu alkuperäiseen ongelmaan löydetään yhdistämällä pienempien tapausten ratkaisuja. Hajotusmenetelmä on ihanteellinen rinnakkaislaskentaan. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 7
 Toistuva hajoamisyhtälö n Yleensä n-kokoisen ongelman ilmentymä voidaan jakaa useisiin koon n/b esiintymiin, joista se on ratkaistava. n Yleistetty toistuva hajoamisyhtälö: (1) n yksinkertaisuuden vuoksi oletetaan, että koko n on yhtä suuri kuin teho b. n Kasvujärjestys riippuu a:sta, b:stä ja f:stä. ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 8
Toistuva hajoamisyhtälö n Yleensä n-kokoisen ongelman ilmentymä voidaan jakaa useisiin koon n/b esiintymiin, joista se on ratkaistava. n Yleistetty toistuva hajoamisyhtälö: (1) n yksinkertaisuuden vuoksi oletetaan, että koko n on yhtä suuri kuin teho b. n Kasvujärjestys riippuu a:sta, b:stä ja f:stä. ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 8
 Perushajotuslause (1) n Voit määrittää algoritmin tehokkuusluokan ratkaisematta itse toistuvuusyhtälöä. n Tämän lähestymistavan avulla voit määrittää ratkaisun kasvujärjestyksen ilman tuntemattomia tekijöitä. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 9
Perushajotuslause (1) n Voit määrittää algoritmin tehokkuusluokan ratkaisematta itse toistuvuusyhtälöä. n Tämän lähestymistavan avulla voit määrittää ratkaisun kasvujärjestyksen ilman tuntemattomia tekijöitä. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 9
 Yhdistä lajittelu Lajittelee tietyn taulukon jakamalla sen kahteen puolikkaaseen, lajittelemalla kukin puolikas rekursiivisesti ja yhdistämällä kaksi lajiteltua puoliskoa yhdeksi lajitetuksi taulukoksi: Yhdistä (A), jos n>1 Ensimmäinen puolisko A -> taulukkoon B Toinen puolisko A -> taulukkoon C Mergesort(B) Mergesort(C) Merge(B, C, A) // yhdistä © Pavlovskaya T. A. (SPb NRU ITMO) 10
Yhdistä lajittelu Lajittelee tietyn taulukon jakamalla sen kahteen puolikkaaseen, lajittelemalla kukin puolikas rekursiivisesti ja yhdistämällä kaksi lajiteltua puoliskoa yhdeksi lajitetuksi taulukoksi: Yhdistä (A), jos n>1 Ensimmäinen puolisko A -> taulukkoon B Toinen puolisko A -> taulukkoon C Mergesort(B) Mergesort(C) Merge(B, C, A) // yhdistä © Pavlovskaya T. A. (SPb NRU ITMO) 10
Src="http://present5.com/presentation/54441564_438337950/image-11.jpg" alt="Mergesort (A) jos n>1 A:n ensimmäinen puolisko -> taulukkoon B A:n toinen puolisko"> Mergesort (A) if n>1 Первая половина А -> в массив В Вторая половина А > в массив С Mergesort(B) Mergesort(C) Меrgе(В, С, А) ©Павловская Т. А. (СПб НИУ ИТМО) 11!}
 Taulukon yhdistäminen n Kaksi taulukkoindeksiä osoittavat alustuksen jälkeen yhdistettyjen taulukoiden ensimmäisiin elementteihin. n Elementtejä verrataan ja pienempi lisätään uuteen taulukkoon. n Pienemmän elementin indeksiä kasvatetaan (se osoittaa välittömästi kopioitua elementtiä seuraavaan). Tätä toimintoa toistetaan, kunnes yksi yhdistetyistä taulukoista on käytetty loppuun. Toisen taulukon loput elementit lisätään uuden taulukon loppuun. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 12
Taulukon yhdistäminen n Kaksi taulukkoindeksiä osoittavat alustuksen jälkeen yhdistettyjen taulukoiden ensimmäisiin elementteihin. n Elementtejä verrataan ja pienempi lisätään uuteen taulukkoon. n Pienemmän elementin indeksiä kasvatetaan (se osoittaa välittömästi kopioitua elementtiä seuraavaan). Tätä toimintoa toistetaan, kunnes yksi yhdistetyistä taulukoista on käytetty loppuun. Toisen taulukon loput elementit lisätään uuden taulukon loppuun. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 12
 Yhdistämisen lajitteluanalyysi n Olkoon tiedoston pituus potenssilla 2. n Avainvertailujen lukumäärä: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 pahimmassa tapauksessa (avainvertailujen määrä yhdistämisen aikana) n Pahimmassa tapauksessa Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n -1 Cw (n ) (n log n) – perusarvon mukaan. lause ©Pavlovskaya T.A. (SPb NRU ITMO) (1) 13
Yhdistämisen lajitteluanalyysi n Olkoon tiedoston pituus potenssilla 2. n Avainvertailujen lukumäärä: C(n) = 2*C(n/2) + Cmerge (n) n > 1, C(1)=0 n Cmerge (n) = n-1 pahimmassa tapauksessa (avainvertailujen määrä yhdistämisen aikana) n Pahimmassa tapauksessa Cw: d=1 a=2 b=2 Cw(n) = 2*Cw (n/2) +n -1 Cw (n ) (n log n) – perusarvon mukaan. lause ©Pavlovskaya T.A. (SPb NRU ITMO) (1) 13
 n Yhdistelmälajittelulla suoritettujen avainvertailujen määrä on pahimmassa tapauksessa hyvin lähellä minkään vertailupohjaisen lajittelualgoritmin teoreettista vähimmäisvertailujen määrää. n Yhdistelmälajittelun suurin haittapuoli on lisämuistin tarve, jonka määrä on lineaarisesti verrannollinen syötetyn tiedon kokoon. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 14
n Yhdistelmälajittelulla suoritettujen avainvertailujen määrä on pahimmassa tapauksessa hyvin lähellä minkään vertailupohjaisen lajittelualgoritmin teoreettista vähimmäisvertailujen määrää. n Yhdistelmälajittelun suurin haittapuoli on lisämuistin tarve, jonka määrä on lineaarisesti verrannollinen syötetyn tiedon kokoon. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 14
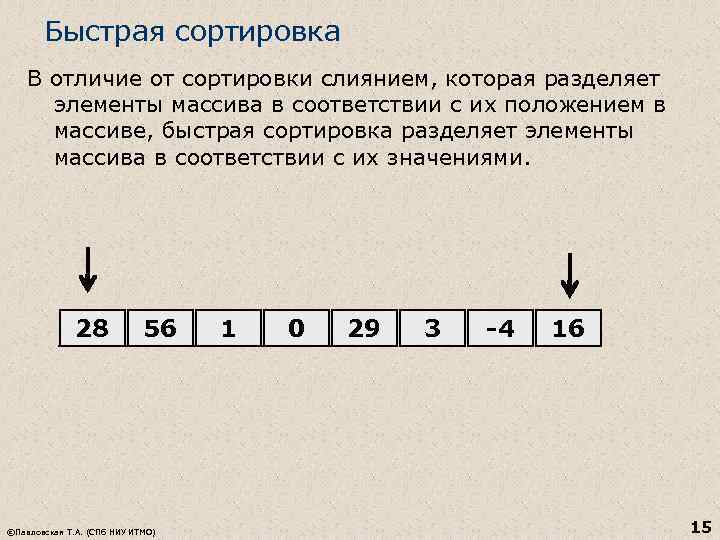 Pikalajittelu Toisin kuin yhdistämislajittelu, joka erottaa taulukkoelementit niiden sijainnin mukaan, pikalajittelu erottaa taulukkoelementit niiden arvojen mukaan. 28 56 ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 1 0 29 3 -4 16 15
Pikalajittelu Toisin kuin yhdistämislajittelu, joka erottaa taulukkoelementit niiden sijainnin mukaan, pikalajittelu erottaa taulukkoelementit niiden arvojen mukaan. 28 56 ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 1 0 29 3 -4 16 15
 Algoritmin kuvaus n Valitse referenssielementti n Suorita elementtien permutaatio osion saamiseksi, kun kaikki alkiot johonkin paikkaan s asti eivät ylitä elementtiä A [s] ja paikan s jälkeiset elementit eivät ole sitä pienempiä. n On selvää, että osioinnin jälkeen A [s] on lopullisessa asemassa, ja voimme lajitella kaksi elementtialiryhmää ennen ja jälkeen A [s] itsenäisesti (samalla tai eri menetelmällä) © T. A. Pavlovskaya (SPb NRU ITMO) 16
Algoritmin kuvaus n Valitse referenssielementti n Suorita elementtien permutaatio osion saamiseksi, kun kaikki alkiot johonkin paikkaan s asti eivät ylitä elementtiä A [s] ja paikan s jälkeiset elementit eivät ole sitä pienempiä. n On selvää, että osioinnin jälkeen A [s] on lopullisessa asemassa, ja voimme lajitella kaksi elementtialiryhmää ennen ja jälkeen A [s] itsenäisesti (samalla tai eri menetelmällä) © T. A. Pavlovskaya (SPb NRU ITMO) 16
 Toimenpide elementtien permutointiin n Tehokas menetelmä, joka perustuu kahteen aliryhmän läpikulkuun - vasemmalta oikealle ja oikealta vasemmalle. Jokaisella ajokerralla elementtejä verrataan referenssiin. n Siirtyminen vasemmalta oikealle (i) ohittaa viittausta pienemmät elementit ja pysähtyy ensimmäiseen elementtiin, joka ei ole pienempi kuin referenssi. n Siirto oikealta vasemmalle (j) ohittaa viitearvoa suuremmat elementit ja pysähtyy ensimmäiseen elementtiin, joka ei ole suurempi kuin referenssi. n Jos skannausindeksit eivät leikkaa, vaihdamme löydetyt elementit ja jatkamme kulkua. n Jos indeksit leikkaavat, vaihda tukielementti Aj:n kanssa © T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 17
Toimenpide elementtien permutointiin n Tehokas menetelmä, joka perustuu kahteen aliryhmän läpikulkuun - vasemmalta oikealle ja oikealta vasemmalle. Jokaisella ajokerralla elementtejä verrataan referenssiin. n Siirtyminen vasemmalta oikealle (i) ohittaa viittausta pienemmät elementit ja pysähtyy ensimmäiseen elementtiin, joka ei ole pienempi kuin referenssi. n Siirto oikealta vasemmalle (j) ohittaa viitearvoa suuremmat elementit ja pysähtyy ensimmäiseen elementtiin, joka ei ole suurempi kuin referenssi. n Jos skannausindeksit eivät leikkaa, vaihdamme löydetyt elementit ja jatkamme kulkua. n Jos indeksit leikkaavat, vaihda tukielementti Aj:n kanssa © T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 17
 Pikalajittelun tehokkuus n Paras tapaus: kaikki osiot päätyvät vastaavien aliryhmien keskelle n Pahimmassa tapauksessa kaikki osiot osoittautuvat sellaisiksi, että yksi aliryhmistä on tyhjä ja toisen koko on 1 pienempi kuin osioidun taulukon koko (neliöinen riippuvuus). n Keskimääräisessä tapauksessa oletetaan, että osio voidaan suorittaa jokaisessa paikassa samalla todennäköisyydellä: Cavg 2 n ln n 1, 38 n log 2 n © T. A. Pavlovskaya (SPb NRU ITMO) 18
Pikalajittelun tehokkuus n Paras tapaus: kaikki osiot päätyvät vastaavien aliryhmien keskelle n Pahimmassa tapauksessa kaikki osiot osoittautuvat sellaisiksi, että yksi aliryhmistä on tyhjä ja toisen koko on 1 pienempi kuin osioidun taulukon koko (neliöinen riippuvuus). n Keskimääräisessä tapauksessa oletetaan, että osio voidaan suorittaa jokaisessa paikassa samalla todennäköisyydellä: Cavg 2 n ln n 1, 38 n log 2 n © T. A. Pavlovskaya (SPb NRU ITMO) 18
 Algoritmin parannuksia n parannettuja menetelmiä referenssielementin valitsemiseksi n siirtyminen yksinkertaisempaan lajitteluun pienten aliryhmien osalta n rekursion poistaminen Kaikki nämä parannukset voivat lyhentää algoritmin ajoaikaa 20 -25 % (R. Sedgwick) © T. A. Pavlovskaya (SPb) NRU ITMO) 19
Algoritmin parannuksia n parannettuja menetelmiä referenssielementin valitsemiseksi n siirtyminen yksinkertaisempaan lajitteluun pienten aliryhmien osalta n rekursion poistaminen Kaikki nämä parannukset voivat lyhentää algoritmin ajoaikaa 20 -25 % (R. Sedgwick) © T. A. Pavlovskaya (SPb) NRU ITMO) 19
 Binaaripuun läpikulku Tämä on toinen esimerkki hajottelumenetelmän käyttämisestä n Ennakkotilauksen läpikäymisessä käydään ensin puun juuressa ja sitten vasemmassa ja oikeassa alipuussa. n Symmetrisessä läpikäymisessä juureen vieraillaan vasemman alipuun jälkeen, mutta ennen oikeanpuoleisen alipuun käyntiä. n Käänteisessä läpikäymisessä juureen käydään vasemman ja oikean alipuun jälkeen. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 20
Binaaripuun läpikulku Tämä on toinen esimerkki hajottelumenetelmän käyttämisestä n Ennakkotilauksen läpikäymisessä käydään ensin puun juuressa ja sitten vasemmassa ja oikeassa alipuussa. n Symmetrisessä läpikäymisessä juureen vieraillaan vasemman alipuun jälkeen, mutta ennen oikeanpuoleisen alipuun käyntiä. n Käänteisessä läpikäymisessä juureen käydään vasemman ja oikean alipuun jälkeen. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 20
 Puuproseduurin läpikulku print_tree(tree); begin print_tree(left_subtree) vieraile juuressa print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 21 25 30 21
Puuproseduurin läpikulku print_tree(tree); begin print_tree(left_subtree) vieraile juuressa print_tree(right_subtree) end; 1 6 8 10 20 ©Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 21 25 30 21

 Ongelman koon pienennysmenetelmä perustuu yhteyden käyttämiseen tietyn ongelmailmentymän ratkaisun ja saman ongelman pienemmän ilmentymän ratkaisun välillä. Kun tällainen suhde on muodostettu, sitä voidaan käyttää joko ylhäältä alas (rekursiivisesti) tai alhaalta ylös (ei-rekursiivisesti). (esimerkki - luvun nostaminen potenssiin) Kokoon pienentämiseen on kolme päävaihtoehtoa: n pienentäminen vakiomäärällä (yleensä 1); n vähennys vakiokertoimella (yleensä 2 kertaa); n vaihteleva koon pienennys. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 23
Ongelman koon pienennysmenetelmä perustuu yhteyden käyttämiseen tietyn ongelmailmentymän ratkaisun ja saman ongelman pienemmän ilmentymän ratkaisun välillä. Kun tällainen suhde on muodostettu, sitä voidaan käyttää joko ylhäältä alas (rekursiivisesti) tai alhaalta ylös (ei-rekursiivisesti). (esimerkki - luvun nostaminen potenssiin) Kokoon pienentämiseen on kolme päävaihtoehtoa: n pienentäminen vakiomäärällä (yleensä 1); n vähennys vakiokertoimella (yleensä 2 kertaa); n vaihteleva koon pienennys. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 23
 Lisäyslajittelu Oletetaan, että dimensioiden n-1 taulukon lajitteluongelma on ratkaistu. Sitten ei enää tarvitse kuin lisätä An oikeaan paikkaan: n taulukon läpi katsominen vasemmalta oikealle n taulukon läpi katsominen oikealta vasemmalle n Lisäyspaikan binäärihaku n Vaikka lisäyslajittelu perustuu rekursiiviseen lähestymistapaan , on tehokkaampaa toteuttaa se alhaalta ylöspäin (iteratiivinen). ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 24
Lisäyslajittelu Oletetaan, että dimensioiden n-1 taulukon lajitteluongelma on ratkaistu. Sitten ei enää tarvitse kuin lisätä An oikeaan paikkaan: n taulukon läpi katsominen vasemmalta oikealle n taulukon läpi katsominen oikealta vasemmalle n Lisäyspaikan binäärihaku n Vaikka lisäyslajittelu perustuu rekursiiviseen lähestymistapaan , on tehokkaampaa toteuttaa se alhaalta ylöspäin (iteratiivinen). ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 24
 Pseudokooditoteutus i = 1 - n - 1 do v = 0 ja A[j] > v do A
Pseudokooditoteutus i = 1 - n - 1 do v = 0 ja A[j] > v do A
 Lisäyslajittelun tehokkuus n Huonoin tapaus: suorittaa saman määrän vertailuja kuin valintalajittelu n Paras tapaus (alkuperäisessä lajittelussa): vertaa vain 1 kerran jokaista ulomman silmukan läpimenoa kohden n Keskimääräinen tapaus (satunnainen matriisi): suorittaa ~2 kertaa vähemmän vertailuja kuin laskevan taulukon tapauksessa. Että. , keskimääräinen tapaus on 2 kertaa parempi kuin huonoin tapaus. Yhdessä sen ylivoimaisen suorituskyvyn kanssa lähes lajiteltujen taulukoiden kanssa, tämä tekee lisäyslajittelusta erottuvan muista perusalgoritmeista (valinta- ja kupla-algoritmeista). n Menetelmän muunnelma on useiden elementtien lisääminen kerrallaan, jotka lajitellaan ennen lisäystä. n Lisäyslajittelun laajennus, Shell sort, tarjoaa vielä paremman algoritmin melko suurten tiedostojen lajitteluun. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 26
Lisäyslajittelun tehokkuus n Huonoin tapaus: suorittaa saman määrän vertailuja kuin valintalajittelu n Paras tapaus (alkuperäisessä lajittelussa): vertaa vain 1 kerran jokaista ulomman silmukan läpimenoa kohden n Keskimääräinen tapaus (satunnainen matriisi): suorittaa ~2 kertaa vähemmän vertailuja kuin laskevan taulukon tapauksessa. Että. , keskimääräinen tapaus on 2 kertaa parempi kuin huonoin tapaus. Yhdessä sen ylivoimaisen suorituskyvyn kanssa lähes lajiteltujen taulukoiden kanssa, tämä tekee lisäyslajittelusta erottuvan muista perusalgoritmeista (valinta- ja kupla-algoritmeista). n Menetelmän muunnelma on useiden elementtien lisääminen kerrallaan, jotka lajitellaan ennen lisäystä. n Lisäyslajittelun laajennus, Shell sort, tarjoaa vielä paremman algoritmin melko suurten tiedostojen lajitteluun. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 26

 Kombinatoristen objektien luominen n Tärkeimmät kombinatoristen objektien tyypit ovat permutaatiot, yhdistelmät ja tietyn joukon osajoukot. n Ne syntyvät tyypillisesti ongelmissa, jotka vaativat erilaisten valintojen harkintaa. n Lisäksi on olemassa käsitteet sijoittaminen ja osiointi. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 28
Kombinatoristen objektien luominen n Tärkeimmät kombinatoristen objektien tyypit ovat permutaatiot, yhdistelmät ja tietyn joukon osajoukot. n Ne syntyvät tyypillisesti ongelmissa, jotka vaativat erilaisten valintojen harkintaa. n Lisäksi on olemassa käsitteet sijoittaminen ja osiointi. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 28
 Permutaatioiden generointi Permutaatioiden lukumäärä n Olkoon n-alkiojoukko (joukko). n Ensimmäinen paikka permutaatiossa voi olla mikä tahansa elementti, eli on n tapaa valita ensimmäinen elementti. n Permutaation toisen elementin valitsemiseen on jäljellä (n-1) elementtiä (toisen elementin valitsemiseen on (n-1) tapaa). n Permutaatiossa on jäljellä (n-2) elementtiä, joilla valitaan kolmas elementti jne. n Yhteensä, n-elementtijärjestetty joukko voidaan saada: tavoilla © T. A. Pavlovskaya (SPb NRU ITMO) 29
Permutaatioiden generointi Permutaatioiden lukumäärä n Olkoon n-alkiojoukko (joukko). n Ensimmäinen paikka permutaatiossa voi olla mikä tahansa elementti, eli on n tapaa valita ensimmäinen elementti. n Permutaation toisen elementin valitsemiseen on jäljellä (n-1) elementtiä (toisen elementin valitsemiseen on (n-1) tapaa). n Permutaatiossa on jäljellä (n-2) elementtiä, joilla valitaan kolmas elementti jne. n Yhteensä, n-elementtijärjestetty joukko voidaan saada: tavoilla © T. A. Pavlovskaya (SPb NRU ITMO) 29
 Koon pienennysmenetelmän soveltaminen n:n kaikkien permutaatioiden saamisen ongelmaan Yksinkertaisuuden vuoksi oletetaan, että permutoitavien elementtien joukko on kokonaislukujen joukko 1:stä n:ään. n Yhdellä pienempi tehtävä on generoida kaikki (n - 1)! permutaatioita. n Olettaen, että se on ratkaistu, voimme saada ratkaisun suurempaan ongelmaan lisäämällä n jokaiseen n mahdolliseen paikkaan kunkin n - 1 elementin permutaatioiden elementtien joukossa. n Kaikki tällä tavalla saadut permutaatiot ovat erilaisia ja niiden kokonaismäärä: n(n- 1)! = n! n Voit lisätä n:n aiemmin luotuihin permutaatioihin vasemmalta oikealle tai oikealta vasemmalle. On edullista aloittaa oikealta vasemmalle ja vaihtaa suuntaa joka kerta, kun siirryt joukon uuteen permutaatioon (1, . . . , n - 1). ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 30
Koon pienennysmenetelmän soveltaminen n:n kaikkien permutaatioiden saamisen ongelmaan Yksinkertaisuuden vuoksi oletetaan, että permutoitavien elementtien joukko on kokonaislukujen joukko 1:stä n:ään. n Yhdellä pienempi tehtävä on generoida kaikki (n - 1)! permutaatioita. n Olettaen, että se on ratkaistu, voimme saada ratkaisun suurempaan ongelmaan lisäämällä n jokaiseen n mahdolliseen paikkaan kunkin n - 1 elementin permutaatioiden elementtien joukossa. n Kaikki tällä tavalla saadut permutaatiot ovat erilaisia ja niiden kokonaismäärä: n(n- 1)! = n! n Voit lisätä n:n aiemmin luotuihin permutaatioihin vasemmalta oikealle tai oikealta vasemmalle. On edullista aloittaa oikealta vasemmalle ja vaihtaa suuntaa joka kerta, kun siirryt joukon uuteen permutaatioon (1, . . . , n - 1). ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 30
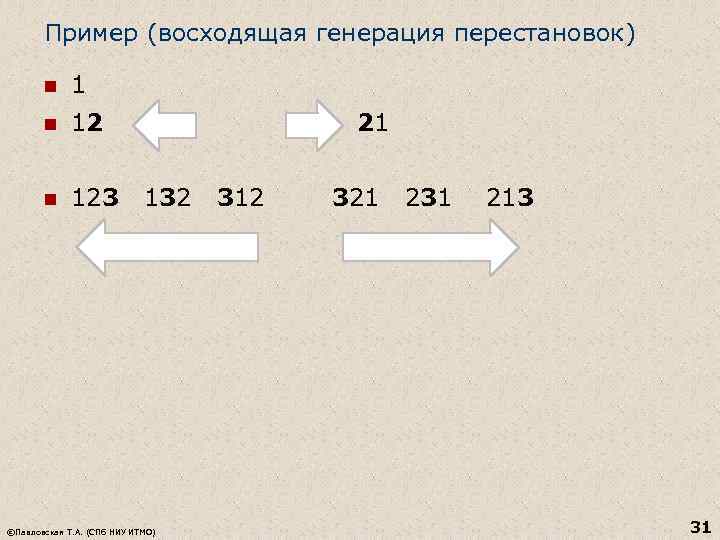 Esimerkki (permutaatioiden nouseva sukupolvi) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (SPb NRU ITMO) 31
Esimerkki (permutaatioiden nouseva sukupolvi) n 12 21 n 123 132 312 321 231 213 © Pavlovskaya T. A. (SPb NRU ITMO) 31
 Johnson-Trotter-algoritmi Esitetään liikkuvan elementin käsite. Jokainen elementti liittyy nuoleen, jos nuoli osoittaa pienempään viereiseen elementtiin. n Alusta ensimmäinen permutaatio arvolla 1 2. . . n (kaikki nuolet vasemmalle) n kun on matkapuhelinnumero k do n Etsi suurin matkapuhelinnumero k Vaihda k ja viereinen numero, johon nuoli osoittaa k n n Muuta nuolien suuntaa kaikille numeroille, jotka ovat suurempia kuin k © Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 32
Johnson-Trotter-algoritmi Esitetään liikkuvan elementin käsite. Jokainen elementti liittyy nuoleen, jos nuoli osoittaa pienempään viereiseen elementtiin. n Alusta ensimmäinen permutaatio arvolla 1 2. . . n (kaikki nuolet vasemmalle) n kun on matkapuhelinnumero k do n Etsi suurin matkapuhelinnumero k Vaihda k ja viereinen numero, johon nuoli osoittaa k n n Muuta nuolien suuntaa kaikille numeroille, jotka ovat suurempia kuin k © Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 32
 Leksikografinen järjestys n Olkoon ensimmäinen permutaatio (esim. 1234). n Jokaisen seuraavan etsiminen: 1. Skannaa nykyinen permutaatio oikealta vasemmalle etsiäksesi ensimmäistä naapurielementtiparia siten, että a[i]
Leksikografinen järjestys n Olkoon ensimmäinen permutaatio (esim. 1234). n Jokaisen seuraavan etsiminen: 1. Skannaa nykyinen permutaatio oikealta vasemmalle etsiäksesi ensimmäistä naapurielementtiparia siten, että a[i]
 Esimerkki algoritmin ymmärtämiseksi 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 3412 3421 342 343 2 4 321 ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 34
Esimerkki algoritmin ymmärtämiseksi 1234 1243 1324 1342 1423 1432 2134 2143 2314 2341 2413 2431 3124 3142 3214 3241 3412 3421 342 343 2 4 321 ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 34
 Kaikkien n alkion permutaatioiden lukumäärä P(n) = n! ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 35
Kaikkien n alkion permutaatioiden lukumäärä P(n) = n! ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 35
 Osajoukot n Joukko A on joukon B osajoukko, jos jokin ryhmään A kuuluva alkio kuuluu myös ryhmään B: A B tai A B n Mikä tahansa joukko on oma osajoukkonsa. Tyhjä joukko on minkä tahansa joukon osajoukko. n Kaikkien osajoukkojen joukkoa merkitään 2 A (setä kutsutaan myös tehojoukoksi, tehojoukoksi, joukko-asteeksi, Boolen arvoksi, eksponentiaalijoukoksi). n N:stä elementistä koostuvan äärellisen joukon osajoukkojen määrä on yhtä suuri kuin 2 n (todiste, katso Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
Osajoukot n Joukko A on joukon B osajoukko, jos jokin ryhmään A kuuluva alkio kuuluu myös ryhmään B: A B tai A B n Mikä tahansa joukko on oma osajoukkonsa. Tyhjä joukko on minkä tahansa joukon osajoukko. n Kaikkien osajoukkojen joukkoa merkitään 2 A (setä kutsutaan myös tehojoukoksi, tehojoukoksi, joukko-asteeksi, Boolen arvoksi, eksponentiaalijoukoksi). n N:stä elementistä koostuvan äärellisen joukon osajoukkojen määrä on yhtä suuri kuin 2 n (todiste, katso Wikipedia) © Pavlovskaya T. A. (SPb NRU ITMO) 36
 Kaikkien osajoukkojen generointi n Sovelletaan menetelmää pienentää tehtävän kokoa yhdellä. n Kaikki osajoukot A = (a 1, . . . , an) voidaan jakaa kahteen ryhmään - ne, jotka sisältävät elementin an ja ne jotka eivät sisällä sitä. n Ensimmäinen ryhmä on kaikki osajoukot (a 1, . . . , an-1); kaikki toisen ryhmän elementit saadaan lisäämällä elementti an ensimmäisen ryhmän osajoukkoon. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) On kätevää määrittää bittielementtejä rivien elementteihin: 000 001 010 011 100 101 110 111 n Muut järjestykset: tiheä; Harmaa koodi: n 000 001 010 111 100 ©T A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 37
Kaikkien osajoukkojen generointi n Sovelletaan menetelmää pienentää tehtävän kokoa yhdellä. n Kaikki osajoukot A = (a 1, . . . , an) voidaan jakaa kahteen ryhmään - ne, jotka sisältävät elementin an ja ne jotka eivät sisällä sitä. n Ensimmäinen ryhmä on kaikki osajoukot (a 1, . . . , an-1); kaikki toisen ryhmän elementit saadaan lisäämällä elementti an ensimmäisen ryhmän osajoukkoon. (a 1) (a 2) (a 1, a 2) (a 3) (a 1, a 3) (a 2, a 3) (a 1, a 2, a 3) On kätevää määrittää bittielementtejä rivien elementteihin: 000 001 010 011 100 101 110 111 n Muut järjestykset: tiheä; Harmaa koodi: n 000 001 010 111 100 ©T A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 37
 Gray-koodien luominen n Gray-koodi n bitille voidaan muodostaa rekursiivisesti n–1 bitin koodista: n kirjoittamalla koodit käänteisessä järjestyksessä n ketjuttamalla alkuperäiset ja käänteiset listat n lisäämällä 0 jokaisen koodin alkuun alkuperäinen luettelo ja 1 käänteisen luettelon koodien alkuun. Esimerkki: n Koodit n = 2 bittiä: 00, 01, 10 n Käänteinen koodiluettelo: 10, 11, 00 n Yhdistetty luettelo: 00, 01, 10, 11, 00 n Nollat lisätty alkuperäiseen luetteloon: 000, 001 , 010 , 11, 00 n Käänteiseen luetteloon lisätyt yksiköt: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (SPb NRU ITMO) 38
Gray-koodien luominen n Gray-koodi n bitille voidaan muodostaa rekursiivisesti n–1 bitin koodista: n kirjoittamalla koodit käänteisessä järjestyksessä n ketjuttamalla alkuperäiset ja käänteiset listat n lisäämällä 0 jokaisen koodin alkuun alkuperäinen luettelo ja 1 käänteisen luettelon koodien alkuun. Esimerkki: n Koodit n = 2 bittiä: 00, 01, 10 n Käänteinen koodiluettelo: 10, 11, 00 n Yhdistetty luettelo: 00, 01, 10, 11, 00 n Nollat lisätty alkuperäiseen luetteloon: 000, 001 , 010 , 11, 00 n Käänteiseen luetteloon lisätyt yksiköt: 000, 001, 010, 111, 100 © Pavlovskaya T. A. (SPb NRU ITMO) 38
 K-elementtiosajoukot n K-alkioisten osajoukkojen lukumäärää n (0 k n) kutsutaan yhdistelmien lukumääräksi (binomikerroin): n Suora ratkaisu on tehoton tekijätekijän nopean kasvun vuoksi. n Pääsääntöisesti k-alkioisten osajoukkojen generointi suoritetaan leksikografisessa järjestyksessä (joista kahdesta osajoukosta generoidaan ensimmäisenä se, jonka elementtiindeksien avulla voidaan muodostaa pienempi k-numeroinen luku n- lukujärjestelmä). n Menetelmä: n kardinaalisuuden k osajoukon ensimmäinen alkio voi olla mikä tahansa alkio, alkaen ensimmäisestä ja päättyen (n-k+1):nneen. n Kun osajoukon ensimmäisen alkion indeksi on kiinteä, on jäljellä valita k-1 elementtiä elementeistä, joiden indeksi on suurempi kuin ensimmäinen. n Jatka sitten samalla tavalla pienentämällä ongelmaa pienemmäksi, kunnes viimeinen elementti valitaan alimmalla rekursiotasolla, minkä jälkeen valittu osajoukko voidaan tulostaa tai käsitellä. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 39
K-elementtiosajoukot n K-alkioisten osajoukkojen lukumäärää n (0 k n) kutsutaan yhdistelmien lukumääräksi (binomikerroin): n Suora ratkaisu on tehoton tekijätekijän nopean kasvun vuoksi. n Pääsääntöisesti k-alkioisten osajoukkojen generointi suoritetaan leksikografisessa järjestyksessä (joista kahdesta osajoukosta generoidaan ensimmäisenä se, jonka elementtiindeksien avulla voidaan muodostaa pienempi k-numeroinen luku n- lukujärjestelmä). n Menetelmä: n kardinaalisuuden k osajoukon ensimmäinen alkio voi olla mikä tahansa alkio, alkaen ensimmäisestä ja päättyen (n-k+1):nneen. n Kun osajoukon ensimmäisen alkion indeksi on kiinteä, on jäljellä valita k-1 elementtiä elementeistä, joiden indeksi on suurempi kuin ensimmäinen. n Jatka sitten samalla tavalla pienentämällä ongelmaa pienemmäksi, kunnes viimeinen elementti valitaan alimmalla rekursiotasolla, minkä jälkeen valittu osajoukko voidaan tulostaa tai käsitellä. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 39
 Esimerkki: yhdistelmät 6 - 3 #sisältää const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
Esimerkki: yhdistelmät 6 - 3 #sisältää const int N = 6, K = 3; int a[K]; void rec(int i) ( if (i == K) ( for (int j = 0; j 0 ? a + 1: 1); a[i]
 Yhdistelmien ominaisuudet n Tietyn elementtijoukon jokainen n-elementtiosajoukko vastaa yhtä ja vain yhtä saman joukon n-k-elementin osajoukkoa: n © T. A. Pavlovskaya (SPb NRU ITMO) 41
Yhdistelmien ominaisuudet n Tietyn elementtijoukon jokainen n-elementtiosajoukko vastaa yhtä ja vain yhtä saman joukon n-k-elementin osajoukkoa: n © T. A. Pavlovskaya (SPb NRU ITMO) 41

 Sijoitukset n n elementin järjestely m:llä on jono, joka koostuu m:stä jonkin n-alkiojoukon eri elementistä (yhdistelmiä, jotka muodostuvat annetusta n elementistä m elementillä ja jotka eroavat joko itse elementeiltä tai elementtien järjestyksestä Erot yhdistelmien ja sijoitusten määritelmissä: n Yhdistelmä – osajoukko, joka sisältää m elementtiä n:stä (elementtien järjestyksellä ei ole merkitystä). n Järjestely on sekvenssi, joka sisältää m elementtiä n:stä (alkioiden järjestys on tärkeä). Sarjaa muodostettaessa elementtien järjestys on tärkeä, mutta osajoukkoa muodostettaessa järjestyksellä ei ole merkitystä. ©Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 44
Sijoitukset n n elementin järjestely m:llä on jono, joka koostuu m:stä jonkin n-alkiojoukon eri elementistä (yhdistelmiä, jotka muodostuvat annetusta n elementistä m elementillä ja jotka eroavat joko itse elementeiltä tai elementtien järjestyksestä Erot yhdistelmien ja sijoitusten määritelmissä: n Yhdistelmä – osajoukko, joka sisältää m elementtiä n:stä (elementtien järjestyksellä ei ole merkitystä). n Järjestely on sekvenssi, joka sisältää m elementtiä n:stä (alkioiden järjestys on tärkeä). Sarjaa muodostettaessa elementtien järjestys on tärkeä, mutta osajoukkoa muodostettaessa järjestyksellä ei ole merkitystä. ©Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 44
 Sijoitusten määrä n Sijoitusten lukumäärä n:stä m: Esimerkki 1: Kuinka monta kaksinumeroista lukua on olemassa, joissa kymmenluku ja yksikkönumero ovat erilaisia ja parittomia? Perusjoukko: (1, 3, 5, 7, 9) – parittomat luvut, n=5 n Yhteys – kaksinumeroinen luku m=2, järjestys on tärkeä, mikä tarkoittaa, että tämä on sijoittelu "viisi kertaa kaksi". n Permutaatioita voidaan pitää sijoitusten erikoistapauksena, jossa m=n Esimerkki 2: Kuinka monella tavalla voit tehdä lipun, joka koostuu kolmesta eri värisestä vaakasuorasta raidasta, jos materiaalia on viisi väriä? ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 45
Sijoitusten määrä n Sijoitusten lukumäärä n:stä m: Esimerkki 1: Kuinka monta kaksinumeroista lukua on olemassa, joissa kymmenluku ja yksikkönumero ovat erilaisia ja parittomia? Perusjoukko: (1, 3, 5, 7, 9) – parittomat luvut, n=5 n Yhteys – kaksinumeroinen luku m=2, järjestys on tärkeä, mikä tarkoittaa, että tämä on sijoittelu "viisi kertaa kaksi". n Permutaatioita voidaan pitää sijoitusten erikoistapauksena, jossa m=n Esimerkki 2: Kuinka monella tavalla voit tehdä lipun, joka koostuu kolmesta eri värisestä vaakasuorasta raidasta, jos materiaalia on viisi väriä? ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 45
 Toistoja sisältävät sijoittelut n Sijoitukset, joissa on toistoa joukon E = (a 1, a 2, . . . , an) n alkiosta k:lla - mikä tahansa äärellinen sarja, joka koostuu tietyn joukon E k alkiosta. n Kaksi toistoa sisältävää sijoitusta on katsotaan erilaisiksi, jos niillä ainakin yhdessä paikassa on erilaisia joukon E alkioita. n Eri sijoittelujen määrä toistoilla välillä n - k on yhtä suuri kuin nk. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 46
Toistoja sisältävät sijoittelut n Sijoitukset, joissa on toistoa joukon E = (a 1, a 2, . . . , an) n alkiosta k:lla - mikä tahansa äärellinen sarja, joka koostuu tietyn joukon E k alkiosta. n Kaksi toistoa sisältävää sijoitusta on katsotaan erilaisiksi, jos niillä ainakin yhdessä paikassa on erilaisia joukon E alkioita. n Eri sijoittelujen määrä toistoilla välillä n - k on yhtä suuri kuin nk. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 46
 Joukkojen osiointi n Joukon osiointi on sen esitys mielivaltaisen määrän pareittain hajallaan olevien osajoukkojen liittona. n n-elementin järjestämättömien osioiden määrä k osaan - 2. tyyppinen Stirling-luku: n n-elementin järjestetyn osion määrä, joka on asetettu m:ään kiinteän kokoiseen osaan - moninominen kerroin: n n-elementtijoukon kaikkien järjestämättömien osioiden lukumäärä saadaan Bell-numerolla: © Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 47
Joukkojen osiointi n Joukon osiointi on sen esitys mielivaltaisen määrän pareittain hajallaan olevien osajoukkojen liittona. n n-elementin järjestämättömien osioiden määrä k osaan - 2. tyyppinen Stirling-luku: n n-elementin järjestetyn osion määrä, joka on asetettu m:ään kiinteän kokoiseen osaan - moninominen kerroin: n n-elementtijoukon kaikkien järjestämättömien osioiden lukumäärä saadaan Bell-numerolla: © Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 47
 Vähennysmenetelmä vakiokertoimella n Esimerkki: binäärihaku n Tällaiset algoritmit ovat logaritmisia ja erittäin nopeina melko harvinaisia. Muuttuvan tekijän n vähentämismenetelmä Esimerkkejä: haku ja lisääminen binäärihakupuuhun, interpolointihaku: © Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 48
Vähennysmenetelmä vakiokertoimella n Esimerkki: binäärihaku n Tällaiset algoritmit ovat logaritmisia ja erittäin nopeina melko harvinaisia. Muuttuvan tekijän n vähentämismenetelmä Esimerkkejä: haku ja lisääminen binäärihakupuuhun, interpolointihaku: © Pavlovskaya T. A. (Pietarin valtionyliopisto ITMO) 48
 Suorituskykyanalyysi n Interpolaatiohaku vaatii keskimäärin vähemmän kuin log 2 n+1 avainvertailua, kun haetaan n satunnaisen arvon luetteloa. n Tämä funktio kasvaa niin hitaasti, että kaikille n:n todellisille käytännön arvoille sitä voidaan pitää vakiona. n Pahimmassa tapauksessa interpolointihaku kuitenkin rappeutuu lineaarihauksi, jota pidetään pahimpana mahdollisena etsintänä. n Interpolaatiohakua käytetään parhaiten suurille tiedostoille ja sovelluksille, joissa tietojen vertailu tai hakeminen on kallista. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 49
Suorituskykyanalyysi n Interpolaatiohaku vaatii keskimäärin vähemmän kuin log 2 n+1 avainvertailua, kun haetaan n satunnaisen arvon luetteloa. n Tämä funktio kasvaa niin hitaasti, että kaikille n:n todellisille käytännön arvoille sitä voidaan pitää vakiona. n Pahimmassa tapauksessa interpolointihaku kuitenkin rappeutuu lineaarihauksi, jota pidetään pahimpana mahdollisena etsintänä. n Interpolaatiohakua käytetään parhaiten suurille tiedostoille ja sovelluksille, joissa tietojen vertailu tai hakeminen on kallista. ©Pavlovskaya T. A. (Pietarin kansallinen tutkimusyliopisto ITMO) 49
 Muunnosmenetelmä n Koostuu siitä, että ongelman ilmentymä muunnetaan toiseksi, syystä tai toisesta helpommin ratkaistavaksi. n Tästä menetelmästä on kolme pääversiota: ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 50
Muunnosmenetelmä n Koostuu siitä, että ongelman ilmentymä muunnetaan toiseksi, syystä tai toisesta helpommin ratkaistavaksi. n Tästä menetelmästä on kolme pääversiota: ©T. A. Pavlovskaya (Pietarin kansallinen tutkimusyliopisto ITMO) 50
 Esimerkki 1: Array-elementtien ainutlaatuisuuden tarkistaminen n Raakavoima-algoritmi vertaa kaikkia elementtejä pareittain, kunnes löydetään kaksi identtistä tai kunnes kaikki mahdolliset parit on tarkasteltu. Pahimmassa tapauksessa hyötysuhde on neliöllinen. n Voit lähestyä ongelmaa toisella tavalla - lajittele ensin taulukko ja vertaa sitten vain peräkkäisiä elementtejä. n Algoritmin ajoaika on lajitteluajan ja viereisten elementtien tarkistusajan summa. n Jos käytät hyvää lajittelualgoritmia, myös koko taulukkoelementtien ainutlaatuisuuden tarkistamisalgoritmin tehokkuus on O (n log n) © T. A. Pavlovskaya (SPb NRU ITMO) 51
Esimerkki 1: Array-elementtien ainutlaatuisuuden tarkistaminen n Raakavoima-algoritmi vertaa kaikkia elementtejä pareittain, kunnes löydetään kaksi identtistä tai kunnes kaikki mahdolliset parit on tarkasteltu. Pahimmassa tapauksessa hyötysuhde on neliöllinen. n Voit lähestyä ongelmaa toisella tavalla - lajittele ensin taulukko ja vertaa sitten vain peräkkäisiä elementtejä. n Algoritmin ajoaika on lajitteluajan ja viereisten elementtien tarkistusajan summa. n Jos käytät hyvää lajittelualgoritmia, myös koko taulukkoelementtien ainutlaatuisuuden tarkistamisalgoritmin tehokkuus on O (n log n) © T. A. Pavlovskaya (SPb NRU ITMO) 51
Raaka voima -menetelmä on suora lähestymistapa ratkaisuun
ongelman, yleensä suoraan ongelman ilmaisuun ja sen käyttämien käsitteiden määritelmiin.
Raakavoima-algoritmia yleisen hakuongelman ratkaisemiseksi kutsutaan peräkkäiseksi hauksi. Tämä algoritmi yksinkertaisesti vertaa tietyn listan elementtejä hakuavaimeen yksitellen, kunnes löydetään elementti, jolla on määritetty avainarvo (onnistunut haku) tai koko luettelo tarkistetaan, mutta haluttua elementtiä ei löydy (epäonnistunut haku). Usein käytetään yksinkertaista lisätemppua: jos lisäät hakunäppäimen luettelon loppuun, haku onnistuu varmasti, joten voit poistaa luettelon valmistumisen tarkistuksen jokaisessa algoritmin iteraatiossa. Seuraava on sellaisen parannetun version pseudokoodi; oletetaan, että syöttödata on taulukon muodossa.
Jos alkuperäinen luettelo on lajiteltu, voit hyödyntää toista parannusta: tällaisen luettelon haku voidaan lopettaa heti, kun havaitaan elementti, joka ei ole pienempi kuin hakuavain. Sekvenssihaku tarjoaa erinomaisen kuvan raakavoimamenetelmästä sen tunnusomaisilla vahvuuksilla (yksinkertaisuus) ja heikkouksilla (matala tehokkuus).
On ilmeistä, että tämän algoritmin ajoaika voi vaihdella hyvin laajoissa rajoissa samalle koon n listalle Pahimmassa tapauksessa eli. kun lista ei sisällä haluttua elementtiä tai kun haluttu elementti on listan viimeisenä, algoritmi suorittaa suurimman määrän operaatioita vertaamalla avainta listan kaikkiin n elementtiin: C(n) = n.
1.2. Rabinin algoritmi.
Rabinin algoritmi on muunnos lineaarisesta algoritmista, se perustuu hyvin yksinkertaiseen ajatukseen:
”Kuvitellaan, että sanasta A, jonka pituus on m, etsimme mallia X, jonka pituus on n. Leikataan n-kokoinen "ikkuna" ja siirretään sitä syötesanaa pitkin. Olemme kiinnostuneita siitä, vastaako "laatikon" sana annettua mallia. Kirjeiden vertaaminen kestää kauan. Sen sijaan korjataan jokin numeerinen funktio sanoihin, joiden pituus on n, jolloin ongelma rajoittuu lukujen vertailuun, mikä on epäilemättä nopeampaa. Jos tämän funktion arvot sanalla "laatikossa" ja näytteessä ovat erilaiset, ei ole sattumaa. Vain jos arvot ovat samat, on tarpeen tarkistaa kirjain kirjaimelta vastaavuus peräkkäin."
Tämä algoritmi suorittaa lineaarisen kulkemisen rivin yli (n askelta) ja lineaarisen läpikulun koko tekstille (m askelta), joten kokonaisajoaika on O(n+m). Samanaikaisesti emme ota huomioon hash-funktion laskemisen aikaista monimutkaisuutta, koska algoritmin ydin on, että tämän funktion tulee olla niin helppo laskea, ettei sen toiminta vaikuta algoritmin kokonaistoimintaan.
Rabinin algoritmi ja sekventiohakualgoritmi ovat vähiten työvoimavaltaisia algoritmeja, joten ne soveltuvat käytettäväksi tietyn luokan tehtävien ratkaisemisessa. Nämä algoritmit eivät kuitenkaan ole optimaalisimpia.
1.3. Knuth-Morris-Pratt (kmp) algoritmi.
KMP-menetelmä käyttää hakumerkkijonon esikäsittelyä, eli: sen perusteella luodaan etuliitefunktio. Käytetään seuraavaa ajatusta: jos i-pituisen merkkijonon etuliite (alias suffiksi) on pidempi kuin yksi merkki, niin se on myös i-1 pituisen osajonon etuliite. Näin ollen tarkistamme edellisen osamerkkijonon etuliitettä, jos se ei täsmää, niin sen etuliitettä jne. Tekemällä tämän löydämme suurimman vaaditun etuliitteen. Seuraava kysymys, johon kannattaa vastata, on: miksi prosessin ajoaika on lineaarinen, koska se sisältää sisäkkäisen silmukan? No, ensinnäkin etuliitefunktion antaminen tapahtuu tasan m kertaa, muun ajan muuttuja k muuttuu. Siksi ohjelman kokonaisajoaika on O(n+m), eli lineaarinen aika.
Osamerkkijonon haku merkkijonosta suoritetaan tietyn mallin mukaan, eli. jokin merkkijono, jonka pituus ei ylitä alkuperäisen merkkijonon pituutta. Haun tehtävänä on määrittää, sisältääkö merkkijono tietyn mallin, ja osoittaa merkkijonon sijainti (indeksi), jos vastaavuus löytyy.
Raaka voima -algoritmi on yksinkertaisin ja hitain, ja se koostuu kaikkien tekstin paikkojen tarkistamisesta, jotta näet, vastaavatko ne kuvion alkua. Jos kuvion alku on sama, näytteen ja tekstin seuraavaa kirjainta verrataan ja niin edelleen viimeisimpään yksinkertaiseen ja hitaimpaan vastaukseen, onko sellainen elementti vai ei, ilmoittamatta, onko se jo lajiteltu kuvion täydellisen vastaavuuden puutteen tai seuraavan kirjaimen eron mukaan.
int BFSearch(merkki *s, merkki *p)
for (int i = 1; strlen(s) - strlen(p); i++)
for (int j = 1; strlen(p); j++)
jos (p[j] != s)
jos (j = strlen(p))
BFSearch-toiminto etsii osamerkkijonoa p merkkijonosta s ja palauttaa alimerkkijonon ensimmäisen merkin indeksin tai 0:n, jos osamerkkijonoa ei löydy. Vaikka tämä menetelmä, kuten useimmat raakavoimamenetelmät, on yleensä tehoton, joissain tilanteissa se on täysin hyväksyttävää.
Kahden tiedemiehen - Boyerin (Robert S. Boyer) ja Mooren (J. Strother Moore) kehittämää Boyer-Moore-algoritmia, jonka olemus on seuraava, pidetään nopeimpana yleiskäyttöisten algoritmien joukossa, jotka on suunniteltu etsimään alimerkkijonoa. merkkijonossa.
Boyer-Mooren algoritmi
Boyer-Moore-algoritmin yksinkertaisin versio koostuu seuraavista vaiheista. Ensimmäinen askel on luoda siirtymätaulukko halutulle näytteelle. Taulukon rakentamisprosessi kuvataan alla. Seuraavaksi rivin alku ja kuvio yhdistetään ja tarkistus alkaa kuvion viimeisestä merkistä. Jos kuvion viimeinen merkki ja päällekkäin asetettu rivin vastaava merkki eivät täsmää, kuviota siirretään suhteessa riviin offset-taulukosta saadun määrän verran ja vertailu suoritetaan uudelleen, alkaen rivin viimeisestä merkistä. kaava. Jos merkit täsmäävät, verrataan otoksen toiseksi viimeistä merkkiä ja niin edelleen. Jos kaikki kuvion merkit vastaavat merkkijonon päällekkäisiä merkkejä, osamerkkijono on löydetty ja haku on päättynyt. Jos kuvion jokin (ei viimeinen) merkki ei vastaa merkkijonon vastaavaa merkkiä, siirrämme kuviota yhden merkin oikealle ja aloitamme tarkistamisen uudelleen viimeisestä merkistä. Koko algoritmia suoritetaan, kunnes joko löydetään halutun kuvion esiintyminen tai saavutetaan merkkijonon loppu.
Siirron määrä, jos viimeinen merkki ei täsmää, lasketaan säännön mukaan: kuvion siirtymän on oltava minimaalinen, jotta kuvion esiintyminen rivillä ei jää huomaamatta. Jos tietty merkkijonomerkki esiintyy kuviossa, kuviota siirretään niin, että merkkijono vastaa merkin oikeanpuoleisinta esiintymää kuviossa. Jos kuvio ei sisällä tätä merkkiä ollenkaan, kuviota siirretään sen pituuden verran, jolloin kuvion ensimmäinen merkki asettuu testattavan viivan seuraavan merkin päälle.
Kuvion kunkin merkin offset-arvo riippuu vain kuvion merkkien järjestyksestä, joten on kätevää laskea siirtymät etukäteen ja tallentaa ne yksiulotteisen taulukon muodossa, jossa jokainen aakkosten merkki vastaa siirtymää suhteessa kuvion viimeiseen merkkiin. Selitämme kaikki edellä mainitut yksinkertaisella esimerkillä. Olkoon viiden merkin joukko: a, b, c, d, e, ja sinun on löydettävä kuvion ”abbad” esiintyminen merkkijonosta ”abecccacbadbabbad”. Seuraavat kaaviot havainnollistavat algoritmin kaikkia vaiheita:
"Abbad"-näytteen siirtymätaulukko.
Aloita haku. Kuvion viimeinen merkki ei vastaa merkkijonon peittomerkkiä. Siirrä näytettä oikealle 5 paikkaa:
Kolme esimerkkisymboleista täsmäsi, mutta neljäs ei. Siirrä näyte oikeaan asentoon:
Viimeinen merkki ei taaskaan vastaa merkkijonon merkkiä. Siirrämme näytettä kahdella asemalla siirtymätaulukon mukaisesti:
Jälleen kerran siirrämme näytettä 2 asemalla:
Nyt siirrämme kuviota taulukon mukaisesti yhdellä asemalla ja saamme kuvion halutun esiintymisen:
Toteutetaan määritetty algoritmi. Ensinnäkin sinun on määritettävä offset-taulukon tietotyyppi. 256 merkistä koostuvan kooditaulukon rakenteen määritelmä näyttää tältä:
BMTable MakeBMTable(char *p)
for (i = 0; i<= 255; i++) bmt->bmtarr[i] = strlen(p);
for (i = strlen(p); i<= 1; i--)
if (bmt->bmtarr] == strlen(p))
bmt->bmtarr] = strlen(p)-i;
Nyt kirjoitetaan funktio, joka suorittaa haun.
int BMSearch(int startpos, char *s, char *p)
pos = startpos + lp - 1;
kun (pos< strlen(s))
if (p != s) pos = pos + bmt->bmtarr];
for (i = lp - 1; i<= 1; i--)
jos (p[i] != s)
paluu(pos - lp + 1);
BMSearch-funktio palauttaa kuvion p ensimmäisen esiintymän ensimmäisen merkin sijainnin merkkijonossa s. Jos sekvenssiä p in s ei löydy, funktio palauttaa arvon 0. Startpos-parametrilla voit määrittää merkkijonon s kohdan, josta haku aloitetaan. Tästä voi olla hyötyä, jos haluat löytää kaikki p:n esiintymät s:ssä. Jos haluat etsiä merkkijonon alusta, aseta startpos arvoon 1. Jos hakutulos on muu kuin nolla, niin löytääksesi seuraavan esiintymän p:ssä s:ssä, aseta startpos arvoksi "edellinen tulos plus kuvion pituus".
Binäärinen (binäärinen) haku
Binaarihakua käytetään, kun haettava taulukko on jo järjestetty.
Muuttujat lb ja ub sisältävät vastaavasti sen matriisin segmentin vasemman ja oikean rajan, jossa haluttu elementti sijaitsee. Haku alkaa aina segmentin keskielementin tarkastelulla. Jos haluttu arvo on pienempi kuin keskielementti, sinun on siirryttävä etsimään segmentin yläpuoliskosta, jossa kaikki elementit ovat pienempiä kuin juuri valittu. Toisin sanoen ub:n arvoksi tulee (m – 1) ja seuraavassa iteraatiossa tarkistetaan puolet alkuperäisestä taulukosta. Siten jokaisen tarkistuksen tuloksena hakualue kaventuu puoleen. Esimerkiksi, jos taulukossa on 100 numeroa, ensimmäisen iteraation jälkeen hakualue pienenee 50 numeroon, toisen jälkeen 25, kolmannen jälkeen 13, neljännen jälkeen 7 jne. Jos taulukon pituus on n, niin noin log 2 n vertailut riittävät alkioiden taulukon etsimiseen.
ja seuraava funktio: function show(pos, polku, w, h) ( var canvas = document.getElementById("canID"); // hanki kanvasobjekti var ctx = canvas.getContext("2d"); // it on ominaisuus - piirustuskonteksti var x0 = 10 // karttapohjan vasemman yläkulman sijainti. leveys = w+2*x0 // muuta kokoa kankaasta (hieman suurempi kuin w x k) ctx.beginPath( // aloita moniviivan piirtäminen ctx.moveTo(x0+pos.x,y0+pos.y)// siirry 0. kaupunkiin for(var i=1); i Esimerkki funktiokutsun tuloksesta. Piirustuskomentojen merkitys tulee selväksi koodissa. Ensin piirretään suljettu polyline. kaupungin ympyrät ja kaupunkinumerot on piirretty niiden päälle piirtää, joka yksinkertaistaa tätä työtä ja mahdollistaa samalla kuvien vastaanottamisen svg-muodossa.
Overkill ajastimessa
Kattavan hakualgoritmin toteuttaminen ajastimen lyhimmän polun löytämiseksi ei ole vaikeaa. Tallentaaksesi parhaan polun taulukkoon minWay, kirjoitetaan funktio taulukon elementtien arvojen kopioimiseksi src joukkoon des:
Funktio copy(des, src) ( if(des.length !== src.length) des = new Array(src.length); for(var i=0; i






