Mikä on ansi. ANSI-paineluokat. Lyhyt koodausten historia
ANSI lumen (lm, lm), mittayksikkö on...
ANSI-luumen on multimediaprojektoreiden valaistuksen mittayksikkö, jonka lamppu valaisee linssin läpi. "Lumen" on latinaa "light", ANSI tarkoittaa "American National Standards Institute". Tämä on standardi valovirran mittaamiseen ja sitä käytetään projektorien vertailuun.
American National Standards Institute otti tämän parametrin käyttöön vuonna 1992 yksikkönä, joka kuvaa keskimääräistä valovirtaa 40" diagonaalisella vertailunäytöllä projektorin zoom-objektiivin vähimmäispolttovälillä.
Mittaus suoritetaan täysin valkoiselle kuvalle (täysvalkoinen), näytön valaistus mitataan valomittarilla lukseina (Lux) näytön 9 säätöpisteessä. Valovirran arvo lasketaan näiden 9 mittauksen keskiarvona - kerrottuna sen pinta-alalla ja lasketaan keskiarvo.
Tuloksena oleva valoenergia näytöllä jokaista neliömetriä kohden ilmaistaan luxeina ja saadaan kaavalla: lux = lumen / m². Lumen/lux-mittaus vaihtelee kuitenkin ympäristön, valaisimen asennuksen ja projisoidun kuvan mukaan, joten ANSI-luumenit hyväksytään nyt laajalti standardina.
Tämän mittauksen avulla voit arvioida valovirran jakautumisen tasaisuutta näytön pinnalla. Kuvan reunojen kirkkauden heikkenemistä kutsutaan "kuumaksi pisteeksi" tai valopisteeksi. Valovirran jakautumisen tasaisuus lasketaan saaduista valaistusmittauksista pienimmän ja suurimman suhteena. Hyvissä projektoreissa tämä arvo ei putoa alle 70 %.
Tämä tekniikka kuvaa tarkasti mittausten suorittamismenettelyn. Tiukasti määritellyissä ympäristöolosuhteissa ja laiteasetuksissa näytölle projisoitu kuva jaetaan yhdeksään yhtä suureen osaan, joista kussakin määritetään valoenergia. Kaikkien yhdeksän mittauksen keskiarvo kerrottuna näytön pinta-alalla m² antaa ANSI Lumen -arvon.
Mielenkiintoista on, että valovirta, toisin kuin valaistusvoimakkuus (mitattuna ANSI-lumeneina), ei riipu projisoidusta alueesta. Lisäksi valmistajan määrittämät ANSI-luumenarvot perustuvat usein referenssimaksimiasetuksiin, joita käytetään harvoin käytännössä.
Lisäksi ANSI-lumenit ovat usein vain keskiarvoja, joten on vaikea arvioida, kuinka hyvin tai huonosti projektori jakaa valon koko näytön pinnalle.
Digitaalisten projektorien ANSI-lumenit voivat vaihdella vanhojen mallien 900 ANSI-lumenista nykyaikaisten suuritehoisten laitteiden 4700 ANSI-lumeniin. Hyvässä digitaalisessa kotiteatteriprojektorissa pitäisi olla noin 2000 ANSI lumenia.
Reg.ru: verkkotunnukset ja hosting
Venäjän suurin rekisterinpitäjä ja hosting-palvelujen tarjoaja.
Yli 2 miljoonaa verkkotunnusta käytössä.
Promootio, verkkotunnuksen sähköposti, yritysratkaisut.
Yli 700 tuhatta asiakasta ympäri maailmaa on jo tehnyt valintansa.
*Keskeytä vieritys viemällä hiiri päälle.
Takaisin eteenpäin
Koodaukset: hyödyllistä tietoa ja lyhyt katsaus
Päätin kirjoittaa tämän artikkelin lyhyeksi katsaukseksi koodauksista.
Selvitämme, mikä koodaus yleensä on, ja kosketamme hieman niiden esiintymishistoriaa periaatteessa.
Puhumme joistakin niiden ominaisuuksista ja pohdimme myös kohtia, joiden avulla voimme työskennellä koodausten kanssa tietoisemmin ja välttää ns. krakozyabrov, eli lukemattomia merkkejä.
Mennään siis...
Mitä on koodaus?
Yksinkertaisesti, koodaus- tämä on taulukko merkkien kohdistamisesta, jotka voimme nähdä näytöllä tiettyihin numerokoodeihin.
Nuo. Jokainen merkki, jonka syötämme näppäimistöltä tai näemme näyttöruudulla, on koodattu tietyllä bittisarjalla (nollat ja ykköset). 8 bittiä, kuten luultavasti tiedät, vastaa 1 tavua tietoa, mutta siitä lisää myöhemmin.
Kirjasintiedostot määräävät itse merkkien ulkonäön jotka on asennettu tietokoneellesi. Siksi prosessia tekstin näyttämiseksi näytöllä voidaan kuvata nollien ja ykkösten sekvenssien jatkuvana vertailuna joihinkin tiettyihin kirjasimeen kuuluviin merkkeihin.
Kaikkien nykyaikaisten koodausten esi-isä voidaan pitää ASCII.
Tämä lyhenne tarkoittaa American Standard Code for Information Interchange(Amerikkalainen vakiomerkkisarja tulostettaville merkeille ja tietyille erikoiskoodeille).
Tämä yksitavuinen koodaus, joka sisältää aluksi vain 128 merkkiä: latinalaisten aakkosten kirjaimet, arabialaiset numerot jne.

Myöhemmin sitä laajennettiin (alun perin se ei käyttänyt kaikkia 8 bittiä), joten tuli mahdolliseksi käyttää ei 128, vaan 256 (2 - 8. potenssi) eri merkkiä, jotka voidaan koodata yhteen tietotavuun.
Tämä parannus mahdollisti lisäämisen ASCII:hen kansallisten kielten symboleja, jo olemassa olevien latinalaisten aakkosten lisäksi.
Laajennetulle ASCII-koodaukselle on monia vaihtoehtoja, koska maailmassa on myös monia kieliä. Luulen, että monet teistä ovat kuulleet sellaisesta koodauksesta kuin KOI8-R on myös laajennettu ASCII-koodaus, suunniteltu toimimaan venäjän kielen merkkien kanssa.
Seuraavana askeleena koodausten kehittämisessä voidaan pitää ns ANSI-koodaukset.
Pohjimmiltaan ne olivat samat ASCII:n laajennetut versiot Niistä kuitenkin poistettiin erilaisia pseudograafisia elementtejä ja lisättiin typografisia symboleja, joille ei aiemmin ollut tarpeeksi "vapaita tiloja".
Esimerkki tällaisesta ANSI-koodauksesta on hyvin tunnettu Windows-1251. Typografisten symbolien lisäksi tämä koodaus sisälsi myös venäjää lähellä olevien kielten (ukraina, valkovenäläinen, serbia, makedonia ja bulgaria) aakkosten kirjaimia.
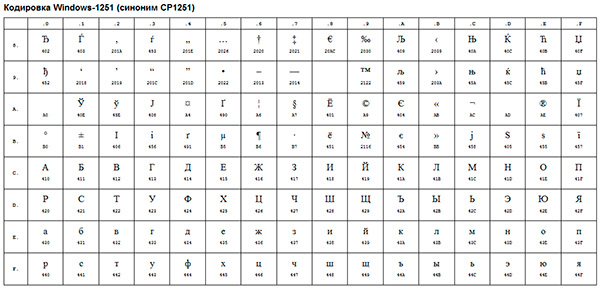
ANSI-koodaus on kollektiivinen nimi. Todellisuudessa varsinainen koodaus ANSI:tä käytettäessä määräytyy Windows-käyttöjärjestelmän rekisterissä määritellyn perusteella. Venäjän tapauksessa tämä on Windows-1251, mutta muilla kielillä se on erilainen ANSI-maku.
Kuten ymmärrät, joukko koodausta ja yhtenäisen standardin puute ei johtanut mihinkään hyvään, mikä oli syynä säännöllisiin tapaamisiin ns. krakozebras- lukukelvoton, merkityksetön merkkijoukko.
Syy niiden ulkonäköön on yksinkertainen - se on yrittää näyttää yhdellä merkistöllä koodattuja merkkejä käyttämällä toista merkistöä.
Verkkokehityksen yhteydessä saatamme kohdata bugeja, kun esim. Venäjänkielinen teksti on vahingossa tallennettu eri koodauksella kuin palvelimella.
Tämä ei tietenkään ole ainoa tapaus, jolloin voimme saada lukukelvotonta tekstiä - tässä on paljon vaihtoehtoja, varsinkin jos otetaan huomioon, että on myös tietokanta, johon tiedot on myös tallennettu tietyssä koodauksessa, on yhteyskartoitus tietokantaan jne.
Kaikkien näiden ongelmien ilmaantuminen toimi kannustimena uuden luomiseen. Sen täytyi olla koodaus, joka kykeni koodaamaan minkä tahansa kielen maailmassa (kun loppujen lopuksi yksitavuisten koodausten avulla, vaikka kuinka yrittäisit, et voi kuvailla kaikkia esimerkiksi kiinan kielen merkkejä, missä on selvästi yli 256), mahdolliset lisäerikoismerkit ja typografia.
Sanalla sanoen, oli pakko luoda yleinen koodaus, joka ratkaisee keksejä koskevan ongelman lopullisesti.
Unicode – yleinen tekstikoodaus (UTF-32, UTF-16 ja UTF-8)
Itse standardia ehdotti vuonna 1991 voittoa tavoittelematon järjestö "Unicode-konsortio"(Unicode Consortium, Unicode Inc.), ja hänen työnsä ensimmäinen tulos oli koodauksen luominen UTF-32.
Muuten, itse lyhenne UTF tarkoittaa Unicode-muunnosmuoto(Unicode-muunnosmuoto).
Tässä koodauksessa yhden merkin koodaamiseksi sen piti käyttää yhtä montaa merkkiä 32 bittiä, eli 4 tavua tietoa. Jos vertaamme tätä numeroa yksitavuisiin koodauksiin, tulemme yksinkertaiseen johtopäätökseen: tarvitset yhden merkin koodaamiseksi tässä yleisessä koodauksessa 4 kertaa enemmän bittejä, mikä tekee tiedostosta 4 kertaa raskaamman.
On myös selvää, että tällä koodauksella mahdollisesti kuvattavien merkkien määrä ylittää kaikki kohtuulliset rajat ja on teknisesti rajoitettu kahteen 32. potenssiin. On selvää, että tämä oli selvästi ylivoimaista ja tuhlausta tiedostojen painon kannalta, joten tämä koodaus ei ollut laajalle levinnyt.
Se korvattiin uudella kehityksellä - UTF-16.
Kuten nimestä käy ilmi, tässä koodauksessa yksi merkki on koodattu ei enää 32 bittiä, vaan vain 16(eli 2 tavua). Ilmeisesti tämä tekee mistä tahansa merkistä kaksi kertaa "kevyemmän" kuin UTF-32:ssa, mutta myös kaksi kertaa "raskaamman" kuin mikä tahansa yksitavuisella koodauksella koodattu merkki.
UTF-16-koodaukseen käytettävissä olevien merkkien määrä on vähintään 2 potenssiin 16, ts. 65536 merkkiä. Kaikki näyttää olevan kunnossa, ja lisäksi UTF-16:n lopullinen koodiavaruus on laajennettu yli 1 miljoonaan merkkiin.
Tämä koodaus ei kuitenkaan täysin täyttänyt kehittäjien tarpeita. Jos esimerkiksi kirjoitat käyttämällä yksinomaan latinalaisia merkkejä, kunkin tiedoston paino kaksinkertaistui sen jälkeen, kun ASCII-koodauksen laajennetusta versiosta on vaihdettu UTF-16.
Tuloksena, toinen yritys yritettiin luoda jotain universaalia, ja tästä tuli tunnettu UTF-8-koodaus.
UTF-8- Tämä monitavuinen vaihtuvamittainen koodaus. Nimeä tarkasteltaessa saatat ajatella, analogisesti UTF-32:n ja UTF-16:n kanssa, että tässä käytetään 8 bittiä yhden merkin koodaamiseen, mutta näin ei ole. Tarkemmin sanottuna ei aivan niin.
Tosiasia on, että UTF-8 tarjoaa parhaan yhteensopivuuden vanhempien järjestelmien kanssa, jotka käyttivät 8-bittisiä merkkejä. Yhden merkin koodaamiseen UTF-8:ssa käytetään itse asiassa 1-4 tavua(hypoteettisesti jopa 6 tavua ovat mahdollisia).
UTF-8:ssa kaikki latinalaiset merkit on koodattu 8-bittisiksi, aivan kuten ASCII:ssa.. Toisin sanoen ASCII-koodauksen perusosa (128 merkkiä) on siirtynyt UTF-8:aan, jonka avulla voit "viettää" vain 1 tavun niiden esittämiseen säilyttäen samalla koodauksen universaalisuuden, jonka vuoksi kaikki oli aloitettu.
Joten jos ensimmäiset 128 merkkiä on koodattu 1 tavulla, kaikki muut merkit on koodattu 2 tavulla tai enemmän. Erityisesti jokainen kyrillinen merkki on koodattu täsmälleen 2 tavua.
Näin ollen olemme saaneet yleisen koodauksen, jonka avulla voimme peittää kaikki mahdolliset näytettävät merkit ilman, että tiedostot raskautuvat tarpeettomasti.
Tuoteluettelolla vai ilman materiaalia?
Jos olet työskennellyt tekstieditorien (koodieditorien), esim. Muistio++, phpDesigner, nopea PHP jne., niin luultavasti huomasit, että määrittäessäsi koodausta, jolla sivu luodaan, voit yleensä valita 3 vaihtoehtoa:
ANSI
- UTF-8
- UTF-8 ilman tuoteluetteloa
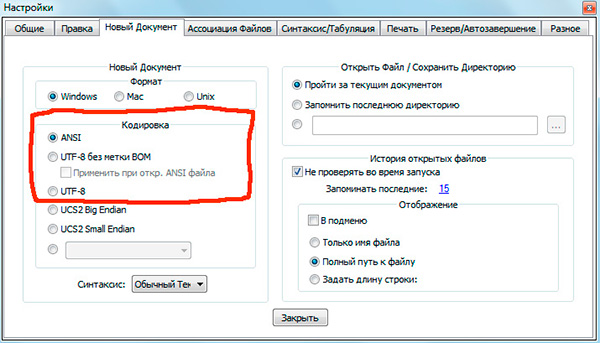
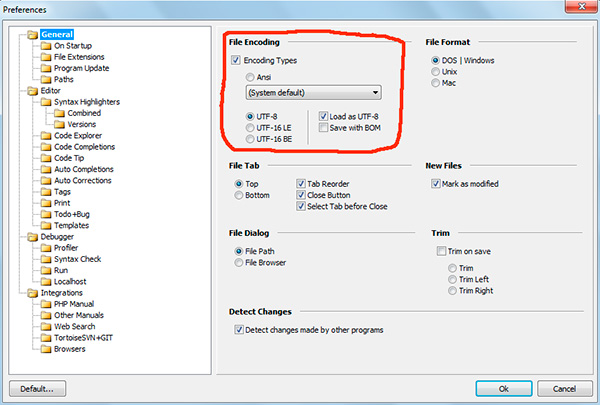
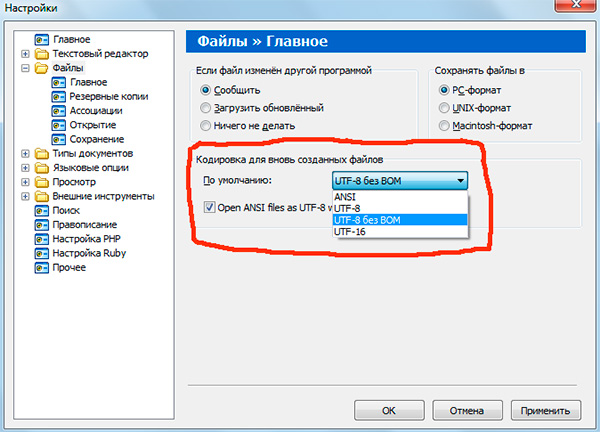
Sanon heti, että sinun tulee aina valita viimeinen vaihtoehto - UTF-8 ilman tuoteluetteloa.
Joten, mikä on BOM ja miksi emme tarvitse sitä?
BOM tarkoittaa Tavujärjestysmerkki. Tämä on erityinen Unicode-merkki, jota käytetään ilmaisemaan tekstitiedoston tavujärjestys. Erittelyn mukaan sen käyttö ei ole pakollista, mutta jos BOM käytetään, se on asetettava tekstitiedoston alkuun.
Emme mene työn yksityiskohtiin BOM. Meidän kannaltamme tärkein johtopäätös on seuraava: Tämän palvelumerkin käyttäminen yhdessä UTF-8:n kanssa estää ohjelmia lukemasta koodausta normaalisti, mikä johtaa virheisiin komentosarjoissa.
American National Standards Institute(Englanti) A merikaaninen n kansallinen s tandarteja i instituutti, ANSI) on amerikkalaisten teollisuuden ja yritysryhmien yhdistys, joka kehittää kaupan ja viestinnän standardeja. Hän on ISO- ja IEC-järjestöjen jäsen ja edustaa siellä Yhdysvaltain etuja.
Tarina
ANSI perustettiin alun perin vuonna 1918, kun viisi insinööriyhdistystä ja kolme valtion virastoa perustivat "American Engineering Standards Committeen" ( AESC- Englanti American Engineering Standards Committee). Vuonna 1928 komitea tunnettiin nimellä American Standards Association. A.S.A.- Englanti American Standards Association). Vuonna 1966 ASA organisoitiin uudelleen ja siitä tuli "United States Standards Institute" ( USASI- Englanti Yhdysvaltain standardiinstituutti). Nykyinen nimi otettiin käyttöön vuonna 1969.
Ennen vuotta 1918 teknisten standardien kehittämiseen osallistui viisi insinööriyhdistystä:
- American Institute of Electrical Engineers (AIEE, nyt IEEE)
- American Society of Mechanical Engineers (ASME)
- American Society of Civil Engineers (ASCE)
- American Institute of Mining Engineers (AIME, nykyään American Institute of Mining, Metallurgical and Petroleum Engineers)
- American Society for Testing and Materials (nykyisin ASTM)
Vuonna 1916 American Institute of Electrical Engineers (nykyään IEEE) teki aloitteen yhdistääkseen näiden organisaatioiden ponnistelut itsenäisen kansallisen elimen luomiseksi koordinoimaan standardien kehittämistä, harmonisoimaan ja hyväksymään kansallisia standardeja. Yllä mainituista viidestä organisaatiosta tuli United Engineering Societyn (UES) ydinjäseniä, minkä jälkeen se kutsui Yhdysvaltain sotaministeriön, laivaston (yhdistettiin vuonna 1947 Yhdysvaltain puolustusministeriöksi) ja kaupan perusjäseniksi.
Vuonna 1931 organisaatiosta (nimettiin uudelleen ASA:ksi vuonna 1928) tuli osa Yhdysvaltain Kansainvälisen sähköteknisen komission (IEC) kansallista komiteaa, joka perustettiin vuonna 1904 kehittämään sähkö- ja elektroniikkatekniikan standardeja.
Jäsenet
ANSI:n jäseniä ovat valtion virastot, järjestöt, akateemiset ja kansainväliset järjestöt sekä yksityishenkilöt. Yhteensä instituutti edustaa yli 270 000 yrityksen ja organisaation sekä 30 miljoonan ammattilaisen etuja ympäri maailmaa /
Toiminta
Vaikka ANSI ei itse kehitä standardeja, instituutti valvoo standardien kehittämistä ja käyttöä akkreditoimalla standardeja kehittävien organisaatioiden menettelyt. ANSI-akkreditointi tarkoittaa, että standardeja asettavien organisaatioiden käyttämät menettelyt täyttävät instituutin avoimuutta, tasapainoa, konsensusta ja asianmukaista menettelyä koskevat vaatimukset.
ANSI määrittelee tietyt standardit myös American National Standards tai ANS, kun instituutti toteaa, että standardit on kehitetty ympäristössä, joka on oikeudenmukainen, helposti saatavilla ja vastaa eri sidosryhmien tarpeita.
Kansainvälinen toiminta
Yhdysvaltain standardointitoiminnan lisäksi ANSI edistää yhdysvaltalaisten standardien kansainvälistä käyttöä, puolustaa Yhdysvaltain politiikkaa ja teknisiä kantoja kansainvälisissä ja alueellisissa standardointijärjestöissä ja kannustaa kansainvälisten standardien hyväksymistä kansallisina standardeina.
Instituutti on Yhdysvaltojen virallinen edustaja kahdessa suuressa kansainvälisessä standardointijärjestössä, Kansainvälisessä standardointijärjestössä (ISO) perustajajäsenenä ja Kansainvälisessä sähköteknisessä toimikunnassa (IEC) Yhdysvaltain kansallisen komitean (USNC) kautta. ANSI osallistuu lähes koko ISO- ja IEC-tekniseen ohjelmaan ja johtaa monia keskeisiä komiteoita ja alaryhmiä. Monissa tapauksissa yhdysvaltalaiset standardit toimitetaan ISO:lle ja IEC:lle ANSI:n tai USNC:n kautta, missä ne hyväksytään kokonaan tai osittain kansainvälisiksi standardeiksi.
ISO- ja IEC-standardien hyväksyminen amerikkalaisina standardeina lisääntyi vuoden 1986 0,2 prosentista 15,5 prosenttiin toukokuussa 2012.
Standardoinnin ohjeet
Instituutti hallinnoi yhdeksää standardiryhmää:
- ANSI Homeland Defense and Security Standardization Collaborative (HDSSC)
- ANSI Nanotechnology Standards Panel (ANSI-NSP)
- ID-varkauksien ehkäisy ja henkilöllisyystodistusten hallintastandardien paneeli
- ANSI Energy Efficiency Standardization Coordination Collaborative
- Nuclear Energy Standards Coordination Collaborative (NESCC)
- Electric Vehicles Standards Panel (EVSP)
- ANSI-NAM-verkosto kemikaalien sääntelystä
- ANSI Biofuels Standards Coordination Panel
- Healthcare Information Technology Standards Panel (HITSP)
- American Pipeline and Machinery Certification Agency
Jokainen ryhmä on vastuussa näiden alojen vapaaehtoisten standardien tunnistamisesta, koordinoinnista ja niistä sopimisesta. Vuonna 2009 ANSI ja (NIST) perustivat ydinenergiastandardien koordinointiyhteistyön (NESCC). NESCC on yhteistyöhanke, jonka tarkoituksena on tunnistaa ja vastata nykyiseen ydinalan standardien tarpeeseen.
Standardit
Instituutin hyväksymistä standardeista tunnetaan:
Vastoin yleistä käsitystä ANSI ei ottanut käyttöön 8-bittisiä koodisivustandardeja, vaikka se osallistui ISO-8859-1-koodauksen ja mahdollisesti joidenkin muidenkin kehittämiseen.
Huomautuksia
- Tietoja ANSI:sta
- RFC
- ANSI: Historical Review (määrittämätön) . ansi.org. Haettu 31. lokakuuta 2016.
- ANSI:n historia
Usein web-ohjelmoinnissa ja html-sivujen ulkoasussa joutuu miettimään muokattavan tiedoston koodausta – jos koodaus valitaan väärin, on mahdollista, että selain ei pysty tunnistamaan sitä automaattisesti ja seurauksena käyttäjä näkee ns. "krakozyabry"
Ehkä olet itse nähnyt joillakin sivustoilla outoja symboleja ja kysymysmerkkejä tavallisen tekstin sijaan. Kaikki tämä tapahtuu, kun html-sivun koodaus ja itse tämän sivun tiedoston koodaus eivät täsmää.
Ollenkaan, mikä on tekstin koodaus? Se on vain joukko merkkejä englanniksi "merkkisarja" (merkkisarja). Sitä tarvitaan tekstiinformaation muuttamiseksi databiteiksi ja siirtämiseksi esimerkiksi Internetin kautta.
Itse asiassa tärkeimmät koodaukset erottavat parametrit ovat tavujen määrä ja erikoismerkkien joukko, joihin lähdetekstin jokainen merkki muunnetaan.
Lyhyt koodauksen historia:
Yksi ensimmäisistä digitaalisen tiedon välittäjistä oli ASCII-koodauksen ilmestyminen - American Standard Code for Information Interchange – amerikkalainen standardikooditaulukko, hyväksynyt American National Standards Institute - American National Standards Institute (ANSI).
Voit hämmentyä näissä lyhenteissä Käytännön kannalta on tärkeää ymmärtää, että luotujen tekstitiedostojen lähdekoodaus ei välttämättä tue joidenkin aakkosten kaikkia merkkejä (esimerkiksi hieroglyfit), joten on taipumus siirtyä aakkosten käyttöön. niin sanottu. standardi Unicode, joka tukee yleisiä koodauksia - Utf-8, Utf-16, Utf-32 jne.
Suosituin Unicode-koodaus on Utf-8. Yleensä verkkosivustojen sivut asetetaan nyt siihen ja kirjoitetaan erilaisia skriptejä. Sen avulla voit helposti näyttää erilaisia hieroglyfejä, kreikkalaisia kirjaimia ja muita kuviteltavia ja käsittämättömiä symboleja (merkkikoko jopa 4 tavua). Erityisesti kaikki WordPress- ja Joomla-tiedostot on kirjoitettu tällä koodauksella. Ja myös jotkut verkkotekniikat (erityisesti AJAX) voivat käsitellä vain utf-8-merkkejä normaalisti.
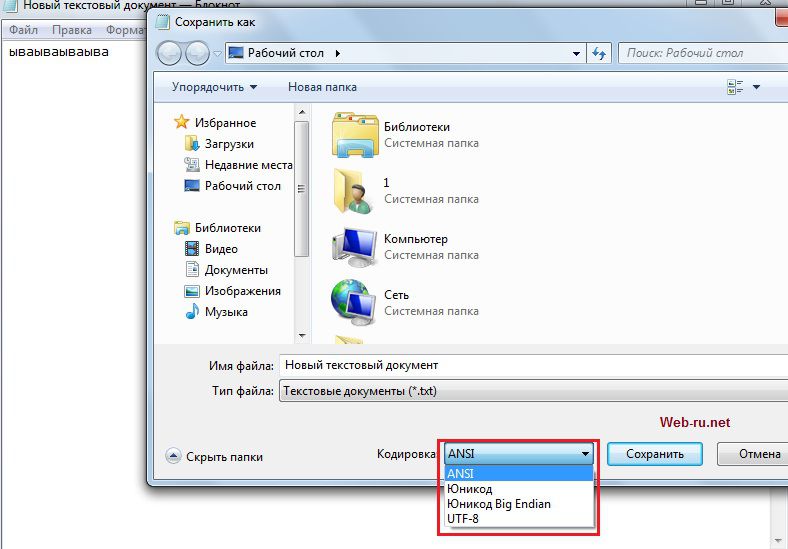
Tekstitiedoston koodausten asettaminen, kun se luodaan tavallisella muistilehtiöllä. Napsautettava
RuNetistä löydät edelleen sivustoja, jotka on kirjoitettu koodaus mielessä. Windows-1251 (tai cp-1251). Tämä on erityinen koodaus, joka on suunniteltu erityisesti kyrillisiin aakkosiin.
On syytä huomata, että kaikilla ANSI-paineluokkamerkinnöillä on tietty merkitys, nimittäin painearvo, mutta vain muissa yksiköissä kuin mihin olemme tottuneet. Kaikki numerot ANSI:n jälkeen osoittavat ehdollisen (nimellis)paineen arvon: ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 ja ANSI 4500. Esimerkiksi ANSI 150 on nimellispaine 150 pos. neliö tuumaa. Englanniksi se on kirjoitettu muodossa Pound-force per Square Inch tai lyhyesti PSI.
Vastaavasti tällä tavalla voit tehdä oman muunnosi psi:stä bar (100 kPa) tai MPa:ksi. Laskeaksesi tarkan itsenäisesti, sinun on tiedettävä, että 1 PSI = 6894,76 Pa. Kaikki ANSI bar- ja Pascal-painelaskelmat voidaan tehdä, kun on aikaa ja tarve tarkkojen tietojen saamiseksi, kun taas useimmissa ANSI-standardipaineluokissa on jo vakiobar- ja MPa-arvot. Sen helpottamiseksi olemme laatineet sinulle lyhyen taulukon:
Taulukko ANSI-paineluokista muunnettuina bariksi ja MPa:iksi
|
ANSI paineluokka |
||






