GPU-оптимизация – прописные истины. Параллельные вычисления на GPU NVIDIA или суперкомпьютер в каждом доме Просчет с gpu на cpu
Сегодня новости об использовании графических процессоров для общих вычислений можно услышать на каждом углу. Такие слова, как CUDA, Stream и OpenCL, за каких-то два года стали чуть ли не самыми цитируемыми в айтишном интернете. Однако, что значат эти слова, и что несут стоящие за ними технологии, известно далеко не каждому. А для линуксоидов, привыкших "быть в пролете", так и вообще все это видится темным лесом.
Рождение GPGPU
Мы все привыкли думать, что единственным компонентом компа, способным выполнять любой код, который ему прикажут, является центральный процессор. Долгое время почти все массовые ПК оснащались единственным процессором, который занимался всеми мыслимыми расчетами, включая код операционной системы, всего нашего софта и вирусов.
Позже появились многоядерные процессоры и многопроцессорные системы, в которых таких компонентов было несколько. Это позволило машинам выполнять несколько задач одновременно, а общая (теоретическая) производительность системы поднялась ровно во столько раз, сколько ядер было установлено в машине. Однако оказалось, что производить и конструировать многоядерные процессоры слишком сложно и дорого.
В каждом ядре приходилось размещать полноценный процессор сложной и запутанной x86-архитектуры, со своим (довольно объемным) кэшем, конвейером инструкций, блоками SSE, множеством блоков, выполняющих оптимизации и т.д. и т.п. Поэтому процесс наращивания количества ядер существенно затормозился, и белые университетские халаты, которым два или четыре ядра было явно мало, нашли способ задействовать для своих научных расчетов другие вычислительные мощности, которых было в достатке на видеокарте (в результате даже появился инструмент BrookGPU, эмулирующий дополнительный процессор с помощью вызовов функций DirectX и OpenGL).
Графические процессоры, лишенные многих недостатков центрального процессора, оказались отличной и очень быстрой счетной машинкой, и совсем скоро к наработкам ученых умов начали присматриваться сами производители GPU (а nVidia так и вообще наняла большинство исследователей на работу). В результате появилась технология nVidia CUDA, определяющая интерфейс, с помощью которого стало возможным перенести вычисление сложных алгоритмов на плечи GPU без каких-либо костылей. Позже за ней последовала ATi (AMD) с собственным вариантом технологии под названием Close to Metal (ныне Stream), а совсем скоро появилась ставшая стандартом версия от Apple, получившая имя OpenCL.
GPU — наше все?
Несмотря на все преимущества, техника GPGPU имеет несколько проблем. Первая из них заключается в очень узкой сфере применения. GPU шагнули далеко вперед центрального процессора в плане наращивания вычислительной мощности и общего количества ядер (видеокарты несут на себе вычислительный блок, состоящий из более чем сотни ядер), однако такая высокая плотность достигается за счет максимального упрощения дизайна самого чипа.
В сущности основная задача GPU сводится к математическим расчетам с помощью простых алгоритмов, получающих на вход не очень большие объемы предсказуемых данных. По этой причине ядра GPU имеют очень простой дизайн, мизерные объемы кэша и скромный набор инструкций, что в конечном счете и выливается в дешевизну их производства и возможность очень плотного размещения на чипе. GPU похожи на китайскую фабрику с тысячами рабочих. Какие-то простые вещи они делают достаточно хорошо (а главное — быстро и дешево), но если доверить им сборку самолета, то в результате получится максимум дельтаплан.
Поэтому первое ограничение GPU — это ориентированность на быстрые математические расчеты, что ограничивает сферу применения графических процессоров помощью в работе мультимедийных приложений, а также любых программ, занимающихся сложной обработкой данных (например, архиваторов или систем шифрования, а также софтин, занимающихся флуоресцентной микроскопией, молекулярной динамикой, электростатикой и другими, малоинтересными для линуксоидов вещами).
Вторая проблема GPGPU в том, что адаптировать для выполнения на GPU можно далеко не каждый алгоритм. Отдельно взятые ядра графического процессора довольно медлительны, и их мощь проявляется только при работе сообща. А это значит, что алгоритм будет настолько эффективным, насколько эффективно его сможет распараллелить программист. В большинстве случаев с такой работой может справиться только хороший математик, которых среди разработчиков софта совсем немного.
И третье: графические процессоры работают с памятью, установленной на самой видеокарте, так что при каждом задействовании GPU будет происходить две дополнительных операции копирования: входные данные из оперативной памяти самого приложения и выходные данные из GRAM обратно в память приложения. Нетрудно догадаться, что это может свести на нет весь выигрыш во времени работы приложения (как и происходит в случае с инструментом FlacCL, который мы рассмотрим позже).
Но и это еще не все. Несмотря на существование общепризнанного стандарта в лице OpenCL, многие программисты до сих пор предпочитают использовать привязанные к производителю реализации техники GPGPU. Особенно популярной оказалась CUDA, которая хоть и дает более гибкий интерфейс программирования (кстати, OpenCL в драйверах nVidia реализован поверх CUDA), но намертво привязывает приложение к видеокартам одного производителя.
KGPU или ядро Linux, ускоренное GPU Исследователи из университета Юты разработали систему KGPU, позволяющую выполнять некоторые функции ядра Linux на графическом процессоре с помощью фреймворка CUDA. Для выполнения этой задачи используется модифицированное ядро Linux и специальный демон, который работает в пространстве пользователя, слушает запросы ядра и передает их драйверу видеокарты с помощью библиотеки CUDA. Интересно, что несмотря на существенный оверхед, который создает такая архитектура, авторам KGPU удалось создать реализацию алгоритма AES, который поднимает скорость шифрования файловой системы eCryptfs в 6 раз. |
Что есть сейчас?
В силу своей молодости, а также благодаря описанным выше проблемам, GPGPU так и не стала по-настоящему распространенной технологией, однако полезный софт, использующий ее возможности, существует (хоть и в мизерном количестве). Одними из первых появились крэкеры различных хэшей, алгоритмы работы которых очень легко распараллелить.
Также родились мультимедийные приложения, например, кодировщик FlacCL, позволяющий перекодировать звуковую дорожку в формат FLAC. Поддержкой GPGPU обзавелись и некоторые уже существовавшие ранее приложения, самым заметным из которых стал ImageMagick, который теперь умеет перекладывать часть своей работы на графический процессор с помощью OpenCL. Также есть проекты по переводу на CUDA/OpenCL (не любят юниксоиды ATi) архиваторов данных и других систем сжатия информации. Наиболее интересные из этих проектов мы рассмотрим в следующих разделах статьи, а пока попробуем разобраться с тем, что нам нужно для того, чтобы все это завелось и стабильно работало.
GPU уже давно обогнали x86-процессоры в производительности
· Во-вторых, в систему должны быть установлены последние проприетарные драйвера для видеокарты, они обеспечат поддержку как родных для карточки технологий GPGPU, так и открытого OpenCL.
· И в-третьих, так как пока дистрибутивостроители еще не начали распространять пакеты приложений с поддержкой GPGPU, нам придется собирать приложения самостоятельно, а для этого нужны официальные SDK от производителей: CUDA Toolkit или ATI Stream SDK. Они содержат в себе необходимые для сборки приложений заголовочные файлы и библиотеки.
Ставим CUDA Toolkit
Идем по вышеприведенной ссылке и скачиваем CUDA Toolkit для Linux (выбрать можно из нескольких версий, для дистрибутивов Fedora, RHEL, Ubuntu и SUSE, есть версии как для архитектуры x86, так и для x86_64). Кроме того, там же надо скачать комплекты драйверов для разработчиков (Developer Drivers for Linux, они идут первыми в списке).
Запускаем инсталлятор SDK:
$ sudo sh cudatoolkit_4.0.17_linux_64_ubuntu10.10.run
Когда установка будет завершена, приступаем к установке драйверов. Для этого завершаем работу X-сервера:
# sudo /etc/init.d/gdm stop
Открываем консоль
$ sudo sh devdriver_4.0_linux_64_270.41.19.run
После окончания установки стартуем иксы:
Чтобы приложения смогли работать с CUDA/OpenCL, прописываем путь до каталога с CUDA-библиотеками в переменную LD_LIBRARY_PATH:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64
Или, если ты установил 32-битную версию:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib32
Также необходимо прописать путь до заголовочных файлов CUDA, чтобы компилятор их нашел на этапе сборки приложения:
$ export C_INCLUDE_PATH=/usr/local/cuda/include
Все, теперь можно приступить к сборке CUDA/OpenCL-софта.
Ставим ATI Stream SDK
Stream SDK не требует установки, поэтому скачанный с сайта AMD-архив можно просто распаковать в любой каталог (лучшим выбором будет /opt) и прописать путь до него во всю ту же переменную LD_LIBRARY_PATH:
$ wget http://goo.gl/CNCNo
$ sudo tar -xzf ~/AMD-APP-SDK-v2.4-lnx64.tgz -C /opt
$ export LD_LIBRARY_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/lib/x86_64/
$ export C_INCLUDE_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/include/
Как и в случае с CUDA Toolkit, x86_64 необходимо заменить на x86 в 32-битных системах. Теперь переходим в корневой каталог и распаковываем архив icd-registration.tgz (это своего рода бесплатный лицензионный ключ):
$ sudo tar -xzf /opt/AMD-APP-SDK-v2.4-lnx64/icd-registration.tgz - С /
Проверяем правильность установки/работы пакета с помощью инструмента clinfo:
$ /opt/AMD-APP-SDK-v2.4-lnx64/bin/x86_64/clinfo
ImageMagick и OpenCL
Поддержка OpenCL появилась в ImageMagick уже достаточно давно, однако по умолчанию она не активирована ни в одном дистрибутиве. Поэтому нам придется собрать IM самостоятельно из исходников. Ничего сложного в этом нет, все необходимое уже есть в SDK, поэтому сборка не потребует установки каких-то дополнительных библиотек от nVidia или AMD. Итак, скачиваем/распаковываем архив с исходниками:
$ wget http://goo.gl/F6VYV
$ tar -xjf ImageMagick-6.7.0-0.tar.bz2
$ cd ImageMagick-6.7.0-0
$ sudo apt-get install build-essential
Запускаем конфигуратор и грепаем его вывод на предмет поддержки OpenCL:
$ LDFLAGS=-L$LD_LIBRARY_PATH ./confi gure | grep -e cl.h -e OpenCL
Правильный результат работы команды должен выглядеть примерно так:
checking CL/cl.h usability... yes
checking CL/cl.h presence... yes
checking for CL/cl.h... yes
checking OpenCL/cl.h usability... no
checking OpenCL/cl.h presence... no
checking for OpenCL/cl.h... no
checking for OpenCL library... -lOpenCL
Словом "yes" должны быть отмечены либо первые три строки, либо вторые (или оба варианта сразу). Если это не так, значит, скорее всего, была неправильно инициализирована переменная C_INCLUDE_PATH. Если же словом "no" отмечена последняя строка, значит, дело в переменной LD_LIBRARY_PATH. Если все окей, запускаем процесс сборки/установки:
$ sudo make install clean
Проверяем, что ImageMagick действительно был скомпилирован с поддержкой OpenCL:
$ /usr/local/bin/convert -version | grep Features
Features: OpenMP OpenCL
Теперь измерим полученный выигрыш в скорости. Разработчики ImageMagick рекомендуют использовать для этого фильтр convolve:
$ time /usr/bin/convert image.jpg -convolve "-1, -1, -1, -1, 9, -1, -1, -1, -1" image2.jpg
$ time /usr/local/bin/convert image.jpg -convolve "-1, -1, -1, -1, 9, -1, -1, -1, -1" image2.jpg
Некоторые другие операции, такие как ресайз, теперь тоже должны работать значительно быстрее, однако надеяться на то, что ImageMagick начнет обрабатывать графику с бешеной скоростью, не стоит. Пока еще очень малая часть пакета оптимизирована с помощью OpenCL.
FlacCL (Flacuda)
FlacCL — это кодировщик звуковых файлов в формат FLAC, задействующий в своей работе возможности OpenCL. Он входит в состав пакета CUETools для Windows, но благодаря mono может быть использован и в Linux. Для получения архива с кодировщиком выполняем следующую команду:
$ mkdir flaccl && cd flaccl
$ wget www.cuetools.net/install/flaccl03.rar
$ sudo apt-get install unrar mono
$ unrar x fl accl03.rar
Чтобы программа смогла найти библиотеку OpenCL, делаем символическую ссылку:
$ ln -s $LD_LIBRARY_PATH/libOpenCL.so libopencl.so
Теперь запускаем кодировщик:
$ mono CUETools.FLACCL.cmd.exe music.wav
Если на экран будет выведено сообщение об ошибке "Error: Requested compile size is bigger than the required workgroup size of 32", значит, у нас в системе слишком слабенькая видеокарта, и количество задействованных ядер следует сократить до указанного числа с помощью флага ‘--group-size XX’, где XX — нужное количество ядер.
Сразу скажу, из-за долгого времени инициализации OpenCL заметный выигрыш можно получить только на достаточно длинных дорожках. Короткие звуковые файлы FlacCL обрабатывает почти с той же скоростью, что и его традиционная версия.
oclHashcat или брутфорс по-быстрому
Как я уже говорил, одними из первых поддержку GPGPU в свои продукты добавили разработчики различных крэкеров и систем брутфорса паролей. Для них новая технология стала настоящим святым граалем, который позволил с легкостью перенести от природы легко распараллеливаемый код на плечи быстрых GPU-процессоров. Поэтому неудивительно, что сейчас существуют десятки самых разных реализаций подобных программ. Но в этой статье я расскажу только об одной из них — oclHashcat.
oclHashcat — это ломалка, которая умеет подбирать пароли по их хэшу с экстремально высокой скоростью, задействуя при этом мощности GPU с помощью OpenCL. Если верить замерам, опубликованным на сайте проекта, скорость подбора MD5-паролей на nVidia GTX580 составляет до 15800 млн комбинаций в секунду, благодаря чему oclHashcat способен найти средний по сложности восьмисимвольный пароль за какие-то 9 минут.
Программа поддерживает OpenCL и CUDA, алгоритмы MD5, md5($pass.$salt), md5(md5($pass)), vBulletin < v3.8.5, SHA1, sha1($pass.$salt), хэши MySQL, MD4, NTLM, Domain Cached Credentials, SHA256, поддерживает распределенный подбор паролей с задействованием мощности нескольких машин.
$ 7z x oclHashcat-0.25.7z
$ cd oclHashcat-0.25
И запустить программу (воспользуемся пробным списком хэшей и пробным словарем):
$ ./oclHashcat64.bin example.hash ?l?l?l?l example.dict
oclHashcat откроет текст пользовательского соглашения, с которым следует согласиться, набрав "YES". После этого начнется процесс перебора, прогресс которого можно узнать по нажатию . Чтобы приостановить процесс, кнопаем
Для возобновления —
$ ./oclHashcat64.bin hash.txt ?l?l?l?l ?l?l?l?l
И различные модификации словаря и метода прямого перебора, а также их комбинации (об этом можно прочитать в файле docs/examples.txt). В моем случае скорость перебора всего словаря составила 11 минут, тогда как прямой перебор (от aaaaaaaa до zzzzzzzz) длился около 40 минут. В среднем скорость работы GPU (чип RV710) составила 88,3 млн/с.
Выводы
Несмотря на множество самых разных ограничений и сложность разработки софта, GPGPU — будущее высокопроизводительных настольных компов. Но самое главное — использовать возможности этой технологии можно прямо сейчас, и это касается не только Windows-машин, но и Linux.
Какая программа нужна для майнинга криптовалюты? Что учитывать при выборе оборудования для майнинга? Как майнить биткоины и эфириум с помощью видеокарты на компьютере?
Оказывается, мощные видеокарты нужны не только фанатам зрелищных компьютерных игр. Тысячи пользователей по всему миру используют графические адаптеры для заработка криптовалюты! Из нескольких карт с мощными процессорами майнеры создают фермы – вычислительные центры, которые добывают цифровые деньги практически из воздуха!
С вами Денис Кудерин – эксперт журнала «ХитёрБобёр» по вопросам финансов и их грамотного умножения. Я расскажу, что собой представляет майнинг на видеокарте в 17-18 годах, как правильно выбрать устройство для заработка криптовалюты, и почему добывать биткоины на видеокартах уже не выгодно.
Вы узнаете также, где купить самую производительную и мощную видеокарту для профессионального майнинга, и получите экспертные советы по повышению эффективности своей майнинг-фермы.
1. Майнинг на видеокарте – легкие деньги или неоправданные расходы
Хорошая видеокарта – не просто адаптер цифровых сигналов, но и мощный процессор, способный решать сложнейшие вычислительные задачи. И в том числе – вычислять хеш-код для цепочки блоков (блокчейна) . Это делает графические платы идеальным инструментом для майнинга – добычи криптовалюты.
Вопрос: Почему именно процессор видеокарты? Ведь в любом компьютере есть центральный процессор? Разве не логично проводить вычисления с его помощью?
Ответ: П роцессор CPU тоже умеет вычислять блокчейны, но делает это в сотни раз медленнее, чем процессор видеокарты (GPU). И не потому, что один лучше, другой хуже. Просто принцип работы у них разный. А если совместить несколько видеокарт, мощность такого вычислительного центра повысится ещё в несколько раз.
Для тех, кто понятия не имеет о том, как добываются цифровые деньги, небольшой ликбез. Майнинг – основной, а иногда и единственный способ производства криптовалюты .
Поскольку эти деньги никто не чеканит и не печатает, и они представляют собой не материальную субстанцию, а цифровой код, кто-то должен этот код вычислять. Этим и занимаются майнеры, а точнее, их компьютеры.
Помимо вычислений кода, майнинг выполняет ещё несколько важнейших задач:
- поддержка децентрализации системы: отсутствие привязанности к серверам – основа блокчейна;
- подтверждение транзакций – без майнинга операции не смогут войти в новый блок;
- формирование новых блоков системы – и занесение их в единый для всех компьютеров реестр.
Сразу хочу охладить пыл начинающих добытчиков: процесс майнинга с каждым годом становится всё труднее. К примеру, с помощью видеокарты уже давно нерентабелен.
Битки с помощью GPU добывают сейчас только упёртые любители, поскольку на смену видеокартам пришли специализированные процессоры ASIC . Эти чипы потребляют меньше электроэнергии и более эффективны в плане вычислений. Всем хороши, но стоят порядка 130-150 тысяч рублей .

К счастью для майнеров, биткоин – не единственная на планете криптовалюта, а одна из сотен. Другие цифровые деньги – эфириумы, Zcash, Expanse , догкоины и т.д. по-прежнему выгодно добывать с помощью видеокарт. Вознаграждение стабильное, а оборудование окупается примерно через 6-12 месяцев.
Но есть ещё одна проблема – дефицит мощных видеокарт . Ажиотаж вокруг криптовалюты привел к удорожанию этих устройств. Купить новую, пригодную для майнинга, видеокарту в России не так-то просто.
Начинающим майнерам приходится заказывать видеоадаптеры в интернет-магазинах (в том числе зарубежных) или приобретать подержанный товар. Последнее, кстати, делать не советую: оборудование для майнинга устаревает и изнашивается с фантастической скоростью .
На Авито даже продают целые фермы для добычи криптовалюты.
Причин много: одни майнеры уже «наигрались» в добычу цифровых денег и решили заняться более прибыльными операциями с криптовалютой (в частности, биржевой торговлей), другие поняли, что конкурировать с мощными китайскими кластерами, работающими на базе электростанций, им не под силу. Третьи переключились с видеокарт на «асики».
Однако ниша пока ещё приносит определенную прибыль, и если заняться с помощью видеокарты прямо сейчас, вы ещё успеете вскочить на подножку уходящего в будущее поезда.
Другое дело, что игроков на этом поле становится всё больше. Причем суммарное количество цифровых монет от этого не увеличивается. Наоборот, награда становится меньше.
Так, шесть лет назад награда за один блокчейн сети биткоин равнялась 50 монетам , сейчас это лишь 12,5 БТК . Сложность вычислений при этом увеличилась в 10 тысяч раз. Правда, и стоимость самого биткоина выросла за это время многократно.
2. Как майнить криптовалюту с помощью видеокарты – пошаговая инструкция
Есть два варианта майнинга – сольный и в составе пула. Одиночной добычей заниматься сложно – нужно иметь огромное количество хешрейта (единиц мощности), чтобы начатые вычисления имели вероятность успешного закрытия.
99% всех майнеров работает в пулах (англ. pool – бассейн) – сообществах, занятых распределением вычислительных задач. Совместный майнинг нивелирует фактор случайности и гарантирует стабильную прибыль.
Один мой знакомый майнер высказался так по этому поводу: я занимаюсь майнингом уже 3 года, за это время не общался ни с кем, кто бы добывал в одиночку.
Такие старатели похожи на золотоискателей 19 века. Можно искать годами свой самородок (в нашем случае – биткоин) и так и не найти. То есть блокчейн так и не будет закрыт, а значит никакой награды вы не получите.
Чуть больше шансов у «одиноких охотников» за эфирами и некоторыми другими крипто-монетами.
Из-за своеобразного алгоритма шифрования ETH не добывают с помощью специальных процессоров (их ещё не придумали). Используют для этого исключительно видеокарты. За счёт эфириумов и других альткоинов ещё держатся многочисленные фермеры современности.
Одной видеокарты для создания полноценной фермы будет недостаточно: 4 штуки – «прожиточный минимум» для майнера , рассчитывающего на стабильную прибыль. Не менее важна мощная система охлаждения видеоадаптеров. И не упускайте из виду и такую статью расходов, как плата за электроэнергию.
Пошаговая инструкция обезопасит от ошибок и ускорит настройку процесса.
Шаг 1. Выбираем пул
Крупнейшие в мире криптовалютные пулы дислоцируются на территории КНР, а также в Исландии и в США. Формально эти сообщества не имеют государственной принадлежности, но русскоязычные сайты пулов – редкость в интернете.
Поскольку добывать на видеокарте вам придётся скорее всего эфириум, то и выбирать нужно будет сообщество, занятое вычислением этой валюты. Хотя Etherium – относительно молодой альткоин, пулов для его майнинга существует множество . От выбора сообщества во многом зависит размер вашего дохода и его стабильность.
Выбираем пул по следующим критериям:
- производительность;
- время работы;
- известность в среде добытчиков криптовалюты;
- наличие положительных отзывов на независимых форумах;
- удобство вывода денег;
- размер комиссии;
- принцип начисления прибыли.
На рынке криптовалют изменения происходят ежедневно. Это касается и скачков курса, и появления новых цифровых денег – форков биткоина. Случаются и глобальные перемены.
Так, недавно стало известно, что эфир в ближайшем будущем переходит на принципиально иную систему распределения прибыли. В двух словах – доход в сети Etherium будут иметь майнеры, у которых есть «много кэцэ», то есть монет, а начинающим добытчикам останется либо прикрыть лавочку, либо переключиться на другие деньги.
Но такие «мелочи» энтузиастов никогда не останавливали. Тем более, есть программка под названием Profitable Pool. Она автоматически отслеживает самые выгодные для добычи альткоины на текущий момент. Есть и сервис поиска самих пулов, а также их рейтинги в реальном времени.
Шаг 2. Устанавливаем и настраиваем программу
Зарегистрировавшись на сайте пула, нужно скачать специальную программу-майнер – не вычислять же код вручную с помощью калькулятора. Таких программ тоже достаточно. Для биткоина это – 50 miner или CGMiner , для эфира – Ethminer .
Настройка требует внимательности и определённых навыков. К примеру, нужно знать, что такое скрипты, и уметь вписывать их в командную строку вашего компьютера. Технические моменты я советую уточнять у практикующих майнеров, поскольку у каждой программы свои нюансы установки и настройки.
Шаг 3. Регистрируем кошелек
Если у вас ещё нет биткоин-кошелька или эфириум-хранилища, нужно их обязательно зарегистрировать. Кошельки скачиваем с официальных сайтов.
Иногда помощь в этом деле оказывают сами пулы, но не безвозмездно.
Шаг 4. Запускаем майнинг и следим за статистикой
Осталось только запустить процесс и ждать первых поступлений. Обязательно скачайте вспомогательную программу, которая будет отслеживать состояние основных узлов вашего компьютера – загруженность, перегрев и т.д.
Шаг 5. Выводим криптовалюту
Компьютеры работают круглосуточно и автоматически, вычисляя код . Вам остаётся только следить, чтобы карты или другие системы не вышли из строя. Криптовалюта потечёт в ваш кошелёк со скоростью, прямо пропорциональной количеству хешрейта.
Как переводить цифровую валюту в фиатную? Вопрос, достойный отдельной статьи. Если коротко, то самый быстрый способ – обменные пункты. Они берут себе проценты за услуги, и ваша задача – найти наиболее выгодный курс с минимальной комиссией. Сделать это поможет профессиональный сервис сравнения обменников.
 – лучший в Рунете ресурс такого плана. Этот мониторинг сравнивает показатели более 300 обменных пунктов и находит лучшие котировки по интересующим вас валютным парам. Более того, сервис указывает резервы криптовалюты в кассе. В списках мониторинга – только проверенные и надёжные обменные сервисы.
– лучший в Рунете ресурс такого плана. Этот мониторинг сравнивает показатели более 300 обменных пунктов и находит лучшие котировки по интересующим вас валютным парам. Более того, сервис указывает резервы криптовалюты в кассе. В списках мониторинга – только проверенные и надёжные обменные сервисы.
3. На что обращать внимание при выборе видеокарты для майнинга
Выбирать видеокарту нужно с умом. Первая попавшаяся или та, которая уже стоит на вашем компьютере, тоже будет майнить, но этой мощности даже для эфиров будет ничтожно мало .
Основные показатели следующие: производительность (мощность), энергопотребление, охлаждение, перспективы разгона.
1) Мощность
Тут всё просто – чем выше производительность процессора, тем лучше для вычисления хеш-кода. Отличные показатели обеспечивают карты с объёмом памяти более 2 ГБ. И выбирайте устройства с 256-разрядной шиной. 128-разрядные для этого дела не годятся.
2) Энергопотребление
Мощность, это, конечно, здорово – высокий хешрейт и всё такое. Но не забывайте о показателях энергопотребления. Некоторые производительные фермы «съедают» столько электричества, что затраты едва окупаются либо не окупаются вообще.
3) Охлаждение
Стандартная состоит из 4-16 карт. Она производит избыточное количество тепла, губительное для железа и нежелательное для самого фермера. В однокомнатной квартире без кондиционера жить и работать будет, мягко говоря, некомфортно.
 Качественное охлаждение процессора - непременное условие успешного майнинга
Качественное охлаждение процессора - непременное условие успешного майнинга
Поэтому при выборе двух карт с одинаковой производительностью отдавайте предпочтение той, у которой меньше показатель тепловой мощности (TDP ) . Наилучшие параметры охлаждения демонстрируют карты Radeon. Эти же устройства дольше всех остальных карт работают в активном режиме без износа.
Дополнительные кулеры не только отведут лишнее тепло от процессоров, но и продлят срок их жизни.
4) Возможность разгона
Разгон – принудительное повышение рабочих показателей видеокарты. Возможность «разогнать карту» зависит от двух параметров – частоты графического процессора и частоты видеопамяти . Именно их вы и будете разгонять, если захотите повысить вычислительные мощности.
Какие видеокарты брать? Вам понадобятся устройства последнего поколения или по меньшей мере графические ускорители, выпущенные не раньше, чем 2-3 года назад. Майнеры используют карты AMD Radeon , Nvidia , Geforce GTX .
Взгляните на таблицу окупаемости видеокарт (данные актуальны на конец 2017 года):
4. Где купить видеокарту для майнинга – обзор ТОП-3 магазинов
Как я уже говорил, видеокарты с ростом популярности майнинга превратились в дефицитный товар. Чтобы купить нужное устройство, придётся потратить немало сил и времени.
Вам поможет наш обзор лучших точек онлайн-продаж.
1) TopComputer
 Московский гипермаркет, специализирующийся на компьютерной и бытовой технике. Работает на рынке больше 14 лет, поставляет товары со всего мира почти по ценам производителей. Работает служба оперативной доставки, бесплатная для москвичей.
Московский гипермаркет, специализирующийся на компьютерной и бытовой технике. Работает на рынке больше 14 лет, поставляет товары со всего мира почти по ценам производителей. Работает служба оперативной доставки, бесплатная для москвичей.
На момент написания статьи в продаже есть карты AMD , Nvidia (8 Gb) и другие разновидности, подходящие для майнинга.
2) Мybitcoinshop
 Специализированный магазин, торгующий исключительно товарами для майнинга
. Здесь вы найдёте всё для постройки домашней фермы – видеокарты нужной конфигурации, блоки питания, переходники и даже ASIC-майнеры (для майнеров нового поколения). Есть платная доставка и самовывоз со склада в Москве.
Специализированный магазин, торгующий исключительно товарами для майнинга
. Здесь вы найдёте всё для постройки домашней фермы – видеокарты нужной конфигурации, блоки питания, переходники и даже ASIC-майнеры (для майнеров нового поколения). Есть платная доставка и самовывоз со склада в Москве.
Компания неоднократно получала неофициальное звание лучшего в РФ магазина для майнеров. Оперативный сервис, доброжелательное отношение к клиентам, передовое оборудование – главные составляющие успеха.
3) Ship Shop America
 Покупка и доставка товаров из США. Посредническая компания для тех, кому нужны действительно эксклюзивные и самые передовые товары для майнинга.
Покупка и доставка товаров из США. Посредническая компания для тех, кому нужны действительно эксклюзивные и самые передовые товары для майнинга.
Прямой партнёр ведущего производителя видеокарт для игр и майнинга – Nvidia . Максимальный срок ожидания товара – 14 дней.
5. Как увеличить доход от майнинга на видеокарте – 3 полезных совета
Нетерпеливые читатели, желающие начать майнинг прямо сейчас и получать доходы уже с завтрашнего утра, непременно спросят – сколько зарабатывают майнеры ?
Заработки зависят от оборудования, курса криптовалюты, эффективности пула, мощности фермы, количества хешрейта и кучи других факторов. Одним удаётся получать ежемесячно до 70 000 в рублях , другие довольствуются 10 долларами в неделю. Это нестабильный и непредсказуемый бизнес.
Полезные советы помогут повысить доходы и оптимизировать расходы.
Будете майнить стремительно растущую в цене валюту, заработаете больше. Для примера – эфир сейчас стоит около 300 долларов , биткоин – больше 6000 . Но учитывать нужно не только текущую стоимость, но и темпы роста за неделю.
Совет 2. Используйте калькулятор майнинга для выбора оптимального оборудования
Калькулятор майнинга на сайте пула или на другом специализированном сервисе поможет выбрать оптимальную программу и даже видеокарту для майнинга.
Как-то раз довелось мне побеседовать на компьютерном рынке с техническим директором одной из многочисленных компаний, занимающихся продажами ноутбуков. Этот «специалист» пытался с пеной у рта объяснить, какая именно конфигурация ноутбука мне нужна. Главный посыл его монолога заключался в том, что время центральных процессоров (CPU) закончилось, и сейчас все приложения активно используют вычисления на графическом процессоре (GPU), а потому производительность ноутбука целиком и полностью зависит от графического процессора, а на CPU можно не обращать никакого внимания. Поняв, что спорить и пытаться вразумить этого технического директора абсолютно бессмысленно, я не стал терять времени зря и купил нужный мне ноутбук в другом павильоне. Однако сам факт такой вопиющей некомпетентности продавца меня поразил. Было бы понятно, если бы он пытался обмануть меня, как покупателя. Отнюдь. Он искренне верил в то, что говорил. Да, видимо, маркетологи в NVIDIA и AMD не зря едят свой хлеб, и им-таки удалось внушить некоторым пользователям идею о доминирующей роли графического процессора в современном компьютере.
Тот факт, что сегодня вычисления на графическом процессоре (GPU) становятся всё более популярными, не вызывает сомнения. Однако это отнюдь не принижает роли центрального процессора. Более того, если говорить о подавляющем большинстве пользовательских приложений, то на сегодняшний день их производительность целиком и полностью зависит от производительности CPU. То есть подавляющее количество пользовательских приложений не используют вычисления на GPU.
Вообще, вычисления на GPU главным образом выполняются на специализированных HPC-системах для научных расчетов. А вот пользовательские приложения, в которых применяются вычисления на GPU, можно пересчитать по пальцам. При этом следует сразу же оговориться, что термин «вычисления на GPU» в данном случае не вполне корректен и может ввести в заблуждение. Дело в том, что если приложение использует вычисление на GPU, то это вовсе не означает, что центральный процессор бездействует. Вычисление на GPU не предполагает переноса нагрузки с центрального процессора на графический. Как правило, центральный процессор при этом остается загруженным, а использование графического процессора, наряду с центральным, позволяет повысить производительность, то есть сократить время выполнения задачи. Причем сам GPU здесь выступает в роли своеобразного сопроцессора для CPU, но ни в коем случае не заменяет его полностью.
Чтобы разобраться, почему вычисления на GPU не являются эдакой панацеей и почему некорректно утверждать, что их вычислительные возможности превосходят возможности CPU, необходимо уяснить разницу между центральным и графическим процессором.
Различия в архитектурах GPU и CPU
Ядра CPU проектируются для выполнения одного потока последовательных инструкций с максимальной производительностью, а GPU - для быстрого исполнения очень большого числа параллельно выполняемых потоков инструкций. В этом и заключается принципиальное отличие графических процессоров от центральных. CPU представляет собой универсальный процессор или процессор общего назначения, оптимизированный для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа, и числа с плавающей точкой. При этом доступ к памяти с данными и инструкциями происходит преимущественно случайным образом.
Для повышения производительности CPU они проектируются так, чтобы выполнять как можно больше инструкций параллельно. Например для этого в ядрах процессора используется блок внеочередного выполнения команд, позволяющий переупорядочивать инструкции не в порядке их поступления, что позволяет поднять уровень параллелизма реализации инструкций на уровне одного потока. Тем не менее это все равно не позволяет осуществить параллельное выполнение большого числа инструкций, да и накладные расходы на распараллеливание инструкций внутри ядра процессора оказываются очень существенными. Именно поэтому процессоры общего назначения имеют не очень большое количество исполнительных блоков.
Графический процессор устроен принципиально иначе. Он изначально проектировался для выполнения огромного количества параллельных потоков команд. Причем эти потоки команд распараллелены изначально, и никаких накладных расходов на распараллеливание инструкций в графическом процессоре просто нет. Графический процессор предназначен для визуализации изображения. Если говорить упрощенно, то на входе он принимает группу полигонов, проводит все необходимые операции и на выходе выдает пикселы. Обработка полигонов и пикселов независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU.
Графические и центральные процессоры различаются и по принципам доступа к памяти. В GPU доступ к памяти легко предсказуем: если из памяти читается тексель текстуры, то через некоторое время придет срок и для соседних текселей. При записи происходит то же самое: если какойто пиксел записывается во фреймбуфер, то через несколько тактов будет записываться пиксел, расположенный рядом с ним. Поэтому GPU, в отличие от CPU, просто не нужна кэшпамять большого размера, а для текстур требуются лишь несколько килобайт. Различен и принцип работы с памятью у GPU и CPU. Так, все современные GPU имеют несколько контроллеров памяти, да и сама графическая память более быстрая, поэтому графические процессоры имеют гораздо бо льшую пропускную способность памяти, по сравнению с универсальными процессорами, что также весьма важно для параллельных расчетов, оперирующих огромными потоками данных.
В универсальных процессорах бо льшую часть площади кристалла занимают различные буферы команд и данных, блоки декодирования, блоки аппаратного предсказания ветвления, блоки переупорядочения команд и кэшпамять первого, второго и третьего уровней. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд за счет их распараллеливания на уровне ядра процессора.
Сами же исполнительные блоки занимают в универсальном процессоре относительно немного места.
В графическом процессоре, наоборот, основную площадь занимают именно многочисленные исполнительные блоки, что позволяет ему одновременно обрабатывать несколько тысяч потоков команд.
Можно сказать, что, в отличие от современных CPU, графические процессоры предназначены для параллельных вычислений с большим количеством арифметических операций.
Использовать вычислительную мощь графических процессоров для неграфических задач возможно, но только в том случае, если решаемая задача допускает возможность распараллеливания алгоритмов на сотни исполнительных блоков, имеющихся в GPU. В частности, выполнение расчетов на GPU показывает отличные результаты в случае, когда одна и та же последовательность математических операций применяется к большому объему данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Эта операция предъявляет меньшие требования к управлению исполнением и не нуждается в использовании емкой кэшпамяти.
Можно привести множество примеров научных расчетов, где преимущество GPU над CPU в плане эффективности вычислений неоспоримо. Так, множество научных приложений по молекулярному моделированию, газовой динамике, динамике жидкостей и прочему отлично приспособлено для расчетов на GPU.
Итак, если алгоритм решения задачи может быть распараллелен на тысячи отдельных потоков, то эффективность решения такой задачи с применением GPU может быть выше, чем ее решение средствами только процессора общего назначения. Однако нельзя так просто взять и перенести решение какойто задачи с CPU на GPU, хотя бы просто потому, что CPU и GPU используют разные команды. То есть когда программа пишется под решение на CPU, то применяется набор команд х86 (или набор команд, совместимый с конкретной архитектурой процессора), а вот для графического процессора используются уже совсем другие наборы команд, которые опять-таки учитывают его архитектуру и возможности. При разработке современных 3D-игр применяются API DirectX и OрenGL, позволяющие программистам работать с шейдерами и текстурами. Однако использование API DirectX и OрenGL для неграфических вычислений на графическом процессоре - это не лучший вариант.
NVIDIA CUDA и AMD APP
Именно поэтому, когда стали предприниматься первые попытки реализовать неграфические вычисления на GPU (General Purpose GPU, GPGPU), возник компилятор BrookGPU. До его создания разработчикам приходилось получать доступ к ресурсам видеокарты через графические API OpenGL или Direct3D, что значительно усложняло процесс программирования, так как требовало специфических знаний - приходилось изучать принципы работы с 3D-объектами (шейдерами, текстурами и т.п.). Это явилось причиной весьма ограниченного применения GPGPU в программных продуктах. BrookGPU стал своеобразным «переводчиком». Эти потоковые расширения к языку Си скрывали от программистов трехмерный API и при его использовании надобность в знаниях 3D-программирования практически отпала. Вычислительные мощности видеокарт стали доступны программистам в виде дополнительного сопроцессора для параллельных расчетов. Компилятор BrookGPU обрабатывал файл с кодом Cи и расширениями, выстраивая код, привязанный к библиотеке с поддержкой DirectX или OpenGL.
Во многом благодаря BrookGPU, компании NVIDIA и ATI (ныне AMD) обратили внимание на зарождающуюся технологию вычислений общего назначения на графических процессорах и начали разработку собственных реализаций, обеспечивающих прямой и более прозрачный доступ к вычислительным блокам 3D-ускорителей.
В результате компания NVIDIA разработала программно-аппаратную архитектуру параллельных вычислений CUDA (Compute Unified Device Architecture). Архитектура CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA.
Релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. В основе API CUDA лежит упрощенный диалект языка Си. Архитектура CUDA SDK обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и включение специальных функций в текст программы на Cи. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA.
CUDA - это кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
Компания AMD (ATI) также разработала свою версию технологии GPGPU, которая ранее называлась AТI Stream, а теперь - AMD Accelerated Parallel Processing (APP). Основу AMD APP составляет открытый индустриальный стандарт OpenCL (Open Computing Language). Стандарт OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. Это полностью открытый стандарт, его использование не облагается лицензионными отчислениями. Отметим, что AMD APP и NVIDIA CUDA несовместимы друг с другом, тем не менее, последняя версия NVIDIA CUDA поддерживает и OpenCL.
Тестирование GPGPU в видеоконвертерах
Итак, мы выяснили, что для реализации GPGPU на графических процессорах NVIDIA предназначена технология CUDA, а на графических процессорах AMD - API APP. Как уже отмечалось, использование неграфических вычислений на GPU целесообразно только в том случае, если решаемая задача может быть распараллелена на множество потоков. Однако большинство пользовательских приложений не удовлетворяют этому критерию. Впрочем, есть и некоторые исключения. К примеру, большинство современных видеоконвертеров поддерживают возможность использования вычислений на графических процессорах NVIDIA и AMD.
Для того чтобы выяснить, насколько эффективно используются вычисления на GPU в пользовательских видеоконвертерах, мы отобрали три популярных решения: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 и Movavi Video Converter 10.2.1. Эти конвертеры поддерживают возможность использования графических процессоров NVIDIA и AMD, причем в настройках видеоконвертеров можно отключить эту возможность, что позволяет оценить эффективность применения GPU.
Для видеоконвертирования мы применяли три различных видеоролика.
Первый видеоролик имел длительность 3 мин 35 с и размер 1,05 Гбайт. Он был записан в формате хранения данных (контейнер) mkv и имел следующие характеристики:
- видео:
- формат - MPEG4 Video (H264),
- разрешение - 1920*um*1080,
- режим битрейта - Variable,
- средний видеобитрейт - 42,1 Мбит/с,
- максимальный видеобитрейт - 59,1 Мбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - MPEG-1 Audio,
- аудиобитрейт - 128 Кбит/с,
- количество каналов - 2,
Второй видеоролик имел длительность 4 мин 25 с и размер 1,98 Гбайт. Он был записан в формате хранения данных (контейнер) MPG и имел следующие характеристики:
- видео:
- формат - MPEG-PS (MPEG2 Video),
- разрешение - 1920*um*1080,
- режим битрейта - Variable.
- средний видеобитрейт - 62,5 Мбит/с,
- максимальный видеобитрейт - 100 Мбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - MPEG-1 Audio,
- аудиобитрейт - 384 Кбит/с,
- количество каналов - 2,
Третий видеоролик имел длительность 3 мин 47 с и размер 197 Мбайт. Он был записан в формате хранения данных (контейнер) MOV и имел следующие характеристики:
- видео:
- формат - MPEG4 Video (H264),
- разрешение - 1920*um*1080,
- режим битрейта - Variable,
- видеобитрейт - 7024 Кбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - AAC,
- аудиобитрейт - 256 Кбит/с,
- количество каналов - 2,
- частота семплирования - 48 кГц.
Все три тестовых видеоролика конвертировались с использованием видеоконвертеров в формат хранения данных MP4 (кодек H.264) для просмотра на планшете iPad 2. Разрешение выходного видеофайла составляло 1280*um*720.
Отметим, что мы не стали использовать абсолютно одинаковые настройки конвертирования во всех трех конвертерах. Именно поэтому по времени конвертирования некорректно сравнивать эффективность самих видеоконвертеров. Так, в видеоконвертере Xilisoft Video Converter Ultimate 7.7.2 для конвертирования применялся пресет iPad 2 - H.264 HD Video. В этом пресете используются следующие настройки кодирования:
- кодек - MPEG4 (H.264);
- разрешение - 1280*um*720;
- частота кадров - 29,97 fps;
- видеобитрейт - 5210 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 48 кГц.
В видеоконвертере Wondershare Video Converter Ultimate 6.0.3.2 использовался пресет iPad 2 cо следующими дополнительными настройками:
- кодек - MPEG4 (H.264);
- разрешение - 1280*um*720;
- частота кадров - 30 fps;
- видеобитрейт - 5000 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 48 кГц.
В конвертере Movavi Video Converter 10.2.1 применялся пресет iPad (1280*um*720, H.264) (*.mp4) со следующими дополнительными настройками:
- видеоформат - H.264;
- разрешение - 1280*um*720;
- частота кадров - 30 fps;
- видеобитрейт - 2500 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 44,1 кГц.
Конвертирование каждого исходного видеоролика проводилось по пять раз на каждом из видеоконвертеров, причем с использованием как графического процессора, так и только CPU. После каждого конвертирования компьютер перезагружался.
В итоге, каждый видеоролик конвертировался десять раз в каждом видеоконвертере. Для автоматизации этой рутинной работы была написана специальная утилита с графическим интерфейсом, позволяющая полностью автоматизировать процесс тестирования.
Конфигурация стенда для тестирования
Стенд для тестирования имел следующую конфигурацию:
- процессор - Intel Core i7-3770K;
- материнская плата - Gigabyte GA-Z77X-UD5H;
- чипсет системной платы - Intel Z77 Express;
- память - DDR3-1600;
- объем памяти - 8 Гбайт (два модуля GEIL по 4 Гбайт);
- режим работы памяти - двухканальный;
- видеокарта - NVIDIA GeForce GTX 660Ti (видеодрайвер 314.07);
- накопитель - Intel SSD 520 (240 Гбайт).
На стенде устанавливалась операционная система Windows 7 Ultimate (64-bit).
Первоначально мы провели тестирование в штатном режиме работы процессора и всех остальных компонентов системы. При этом процессор Intel Core i7-3770K работал на штатной частоте 3,5 ГГц c активированным режимом Turbo Boost (максимальная частота процессора в режиме Turbo Boost составляет 3,9 ГГц).
Затем мы повторили процесс тестирования, но при разгоне процессора до фиксированной частоты 4,5 ГГц (без использования режима Turbo Boost). Это позволило выявить зависимость скорости конвертирования от частоты процессора (CPU).
На следующем этапе тестирования мы вернулись к штатным настройкам процессора и повторили тестирование уже с другими видеокартами:
- NVIDIA GeForce GTX 280 (драйвер 314.07);
- NVIDIA GeForce GTX 460 (драйвер 314.07);
- AMD Radeon HD6850 (драйвер 13.1).
Таким образом, видеоконвертирование проводилось на четырех видеокартах различной архитектуры.
Старшая видеокарта NVIDIA GeForce 660Ti основана на одноименном графическом процессоре с кодовым обозначением GK104 (архитектура Kepler), производимом по 28-нм техпроцессу. Этот графический процессор содержит 3,54 млрд транзисторов, а площадь кристалла составляет 294 мм2.
Напомним, что графический процессор GK104 включает четыре кластера графической обработки (Graphics Processing Clusters, GPC). Кластеры GPC являются независимыми устройствами в составе процессора и способны работать как отдельные устройства, поскольку обладают всеми необходимыми ресурсами: растеризаторами, геометрическими движками и текстурными модулями.
Каждый такой кластер имеет два потоковых мультипроцессора SMX (Streaming Multiprocessor), но в процессоре GK104 в одном из кластеров один мультипроцессор заблокирован, поэтому всего имеется семь мультипроцессоров SMX.
Каждый потоковый мультипроцессор SMX содержит 192 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 1344 вычислительных ядра CUDA. Кроме того, каждый SMX-мультипроцессор содержит 16 текстурных модулей (TMU), 32 блока специальных функций (Special Function Units, SFU), 32 блока загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Видеокарта GeForce GTX 460 основана на графическом процессоре с кодовым обозначением GF104 на базе архитектуры Fermi. Этот процессор производится по 40-нм техпроцессу и содержит порядка 1,95 млрд транзисторов.
Графический процессор GF104 включает два кластера графической обработки GPC. Каждый из них имеет четыре потоковых мультипроцессора SM, но в процессоре GF104 в одном из кластеров один мультипроцессор заблокирован, поэтому существует всего семь мультипроцессоров SM.
Каждый потоковый мультипроцессор SM содержит 48 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 336 вычислительных ядра CUDA. Кроме того, каждый SM-мультипроцессор содержит восемь текстурных модулей (TMU), восемь блоков специальных функций (Special Function Units, SFU), 16 блоков загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Графический процессор GeForce GTX 280 относится ко второму поколению унифицированной архитектуры графических процессоров NVIDIA и по своей архитектуре сильно отличается от архитектуры Fermi и Kepler.
Графический процессор GeForce GTX 280 состоит из кластеров обработки текстур (Texture Processing Clusters, TPC), которые, хоть и похожи, но в то же время сильно отличаются от кластеров графической обработки GPC в архитектурах Fermi и Kepler. Всего таких кластеров в процессоре GeForce GTX 280 насчитывается десять. Каждый TPC-кластер включает три потоковых мультипроцессора SM и восемь блоков текстурной выборки и фильтрации (TMU). Каждый мультипроцессор состоит из восьми потоковых процессоров (SP). Мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических, так и в некоторых расчетных задачах.
Таким образом, в одном TPC-кластере - 24 потоковых процессора, а в графическом процессоре GeForce GTX 280 их уже 240.
Сводные характеристики используемых в тестировании видеокарт на графических процессорах NVIDIA представлены в таблице .
В приведенной таблице нет видеокарты AMD Radeon HD6850, что вполне естественно, поскольку по техническим характеристикам ее трудно сравнивать с видеокартами NVIDIA. А потому рассмотрим ее отдельно.
Графический процессор AMD Radeon HD6850, имеющий кодовое наименование Barts, изготовляется по 40-нм техпроцессу и содержит 1,7 млрд транзисторов.
Архитектура процессора AMD Radeon HD6850 представляет собой унифицированную архитектуру с массивом общих процессоров для потоковой обработки многочисленных видов данных.
Процессор AMD Radeon HD6850 состоит из 12 SIMD-ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров и четыре текстурных блока. Каждый суперскалярный потоковый процессор содержит пять универсальных потоковых процессоров. Таким образом, всего в графическом процессоре AMD Radeon HD6850 насчитывается 12*um*16*um*5=960 универсальных потоковых процессоров.
Частота графического процессора видеокарты AMD Radeon HD6850 составляет 775 МГц, а эффективная частота памяти GDDR5 - 4000 МГц. При этом объем памяти составляет 1024 Мбайт.
Результаты тестирования
Итак, давайте обратимся к результатам тестирования. Начнем с первого теста, когда используется видеокарта NVIDIA GeForce GTX 660Ti и штатный режим работы процессора Intel Core i7-3770K.
На рис. 1-3 показаны результаты конвертирования трех тестовых видеороликов тремя конвертерами в режимах с применением графического процессора и без.
Как видно по результатам тестирования, эффект от использования графического процессора налицо. Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 14, 9 и 19% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 13 и 23% для первого, второго и третьего видеоролика соответственно.
Но более всех от применения графического процессора выигрывает конвертер Movavi Video Converter 10.2.1. Для первого, второго и третьего видеоролика сокращение времени конвертирования составляет 64, 81 и 41% соответственно.
Понятно, что выигрыш от использования графического процессора зависит и от исходного видеоролика, и от настроек видеоконвертирования, что, собственно, и демонстрируют полученные нами результаты.
Теперь посмотрим, каков будет выигрыш по времени конвертирования при разгоне процессора Intel Core i7-3770K до частоты 4,5 ГГц. Если считать, что в штатном режиме все ядра процессора при конвертировании загружены и в режиме Turbo Boost работают на частоте 3,7 ГГц, то увеличение частоты до 4,5 ГГц соответствует разгону по частоте на 22%.
На рис. 4-6 показаны результаты конвертирования трех тестовых видеороликов при разгоне процессора в режимах с использованием графического процессора и без. В данном случае применение графического процессора позволяет получить выигрыш по времени конвертирования.
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 15, 9 и 20% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 10 и 20% для первого, второго и третьего видеоролика соответственно.
Для конвертера Movavi Video Converter 10.2.1 применение графического процессора позволяет сократить время конвертирования на 59, 81 и 40% соответственно.
Естественно, интересно посмотреть, как разгон процессора позволяет уменьшить время конвертирования при использовании графического процессора и без него.
На рис. 7-9 представлены результаты сравнения времени конвертирования видеороликов без использования графического процессора в штатном режиме работы процессора и в режиме разгона. Поскольку в данном случае конвертирование проводится только средствами CPU без вычислений на GPU, очевидно, что увеличение тактовой частоты работы процессора приводит к сокращению времени конвертирования (увеличению скорости конвертирования). Столь же очевидно, что сокращение скорости конвертирования должно быть примерно одинаково для всех тестовых видеороликов. Так, для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 9, 11 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 9 и 10% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 13, 12 и 12% соответственно.
Таким образом, при разгоне процессора по частоте на 20% время конвертирования сокращается примерно на 10%.
Сравним время конвертирования видеороликов с использованием графического процессора в штатном режиме работы процессора и в режиме разгона (рис. 10-12).
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 10, 10 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 6 и 5% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 0,2, 10 и 10% соответственно.
Как видим, для конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 сокращение времени конвертирования при разгоне процессора примерно одинаково как при использовании графического процессора, так и без его применения, что логично, поскольку эти конвертеры не очень эффективно используют вычисления на GPU. А вот для конвертера Movavi Video Converter 10.2.1, который эффективно использует вычисления на GPU, разгон процессора в режиме использования вычислений на GPU мало сказывается на сокращении времени конвертирования, что также понятно, поскольку в данном случае основная нагрузка ложится на графический процессор.
Теперь посмотрим результаты тестирования с различными видеокартами.
Казалось бы, чем мощнее видеокарта и чем больше в графическом процессоре ядер CUDA (или универсальных потоковых процессоров для видеокарт AMD), тем эффективнее должно быть видеоконвертирование в случае применения графического процессора. Но на практике получается не совсем так.
Что касается видеокарт на графических процессорах NVIDIA, то ситуация следующая. При использовании конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 время конвертирования практически никак не зависит от типа используемой видеокарты. То есть для видеокарт NVIDIA GeForce GTX 660Ti, NVIDIA GeForce GTX 460 и NVIDIA GeForce GTX 280 в режиме использования вычислений на GPU время конвертирования получается одно и то же (рис. 13-15).
|
|
Рис. 1. Результаты конвертирования первого |
процессора видеокартах в режиме использования графического процессора |
|
|
Рис. 14. Результаты сравнения времени конвертирования второго видеоролика |
|
|
|
Рис. 15. Результаты сравнения времени конвертирования третьего видеоролика |
|



Объяснить это можно лишь тем, что алгоритм вычислений на графическом процессоре, реализованный в конвертерах Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32, просто неэффективен и не позволяет активно задействовать все графические ядра. Кстати, именно этим объясняется и тот факт, что для этих конвертеров разница по времени конвертирования в режимах использования GPU и без использования невелика.
В конвертере Movavi Video Converter 10.2.1 ситуация несколько иная. Как мы помним, этот конвертер способен очень эффективно использовать вычисления на GPU, а поэтому в режиме использования GPU время конвертирования зависит от типа используемой видеокарты.
А вот с видеокартой AMD Radeon HD 6850 всё как обычно. То ли драйвер видеокарты «кривой», то ли алгоритмы, реализованные в конвертерах, нуждаются в серьезной доработке, но в случае применения вычислений на GPU результаты либо не улучшаются, либо ухудшаются.
Если говорить более конкретно, то ситуация следующая. Для конвертера Xilisoft Video Converter Ultimate 7.7.2 при использовании графического процессора для конвертирования первого тестового видеоролика время конвертирования увеличивается на 43%, при конвертировании второго ролика - на 66%.
Причем, конвертер Xilisoft Video Converter Ultimate 7.7.2 характеризуется еще и нестабильностью результатов. Разброс по времени конвертирования может достигать 40%! Именно поэтому мы повторяли все тесты по десять раз и рассчитывали средний результат.
А вот для конвертеров Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 при использовании графического процессора для конвертирования всех трех видеороликов время конвертирования не изменяется вообще! Вероятно, что конвертеры Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 либо не используют технологию AMD APP при конвертировании, либо видеодрайвер AMD попросту «кривой», в результате чего технология AMD APP не работает.
Выводы
На основании проведенного тестирования можно сделать следующие важные выводы. В современных видеоконвертерах действительно может применяться технология вычислений на GPU, что позволяет повысить скорость конвертирования. Однако это вовсе не означает, что все вычисления целиком переносятся на GPU и CPU остается незадействованным. Как показывает тестирование, при использовании технологии GPGPU центральный процессор остается загруженным, а значит, применение мощных, многоядерных центральных процессоров в системах, используемых для конвертирования видео, остается актуальным. Исключением из этого правила является технология AMD APP на графических процессорах AMD. Например, при использовании конвертера Xilisoft Video Converter Ultimate 7.7.2 с активированной технологией AMD APP нагрузка на CPU действительно снижается, но это приводит к тому, что время конвертирования не сокращается, а, наоборот, увеличивается.
Вообще, если говорить о конвертировании видео с дополнительным использованием графического процессора, то для решения этой задачи целесообразно применять видеокарты с графическими процессорами NVIDIA. Как показывает практика, только в этом случае можно добиться увеличения скорости конвертирования. Причем нужно помнить, что реальный прирост в скорости конвертирования зависит от очень многих факторов. Это входной и выходной форматы видео, и, конечно же, сам видеоконвертер. Конвертеры Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 для этой задачи подходят плохо, а вот конвертер и Movavi Video Converter 10.2.1 способен очень эффективно использовать возможности NVIDIA GPU.
Что же касается видеокарт на графических процессорах AMD, то для задач видеоконвертирования их не стоит применять вообще. В лучшем случае никакого прироста в скорости конвертирования это не даст, а в худшем - можно получить ее снижение.
Часто стал появляться вопрос: почему нет GPU ускорения в программе Adobe Media Encoder CC? А то что Adobe Media Encoder использует GPU ускорение, мы выяснили , а также отметили нюансы его использования . Также встречается утверждение: что в программе Adobe Media Encoder CC убрали поддержку GPU ускорения. Это ошибочное мнение и вытекает из того, что основная программа Adobe Premiere Pro CC теперь может работать без прописанной и рекомендованной видеокарты, а для включения GPU движка в Adobe Media Encoder CC, видеокарта должна быть обязательно прописана в документах: cuda_supported_cards или opencl_supported_cards. Если с чипсетами nVidia все понятно, просто берем имя чипсета и вписываем его в документ cuda_supported_cards. То при использовании видеокарт AMD прописывать надо не имя чипсета, а кодовое название ядра. Итак, давайте на практике проверим, как на ноутбуке ASUS N71JQ с дискретной графикой ATI Mobility Radeon HD 5730 включить GPU движок в Adobe Media Encoder CC. Технические данные графического адаптера ATI Mobility Radeon HD 5730 показываемые утилитой GPU-Z:
Запускаем программу Adobe Premiere Pro CC и включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL).
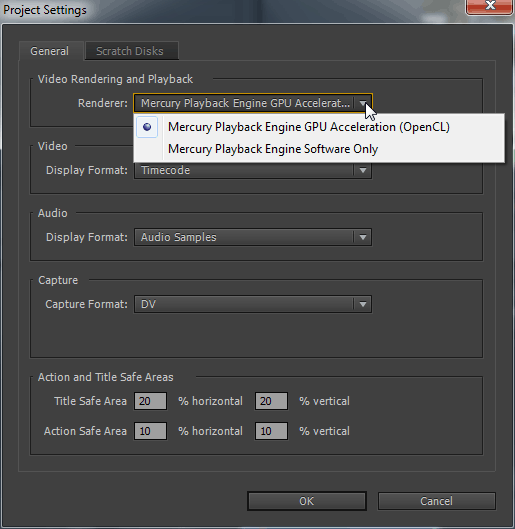
Три DSLR видео на таймлайне, друг над другом, два из них, создают эффект картинка в картинке.

Ctrl+M, выбираем пресет Mpeg2-DVD, убираем черные полосы по бокам с помощью опции Scale To Fill. Включаем также повышеное качество для тестов без GPU: MRQ (Use Maximum Render Quality). Нажимаем на кнопку: Export. Загрузка процессора до 20% и оперативной памяти 2.56 Гбайт.

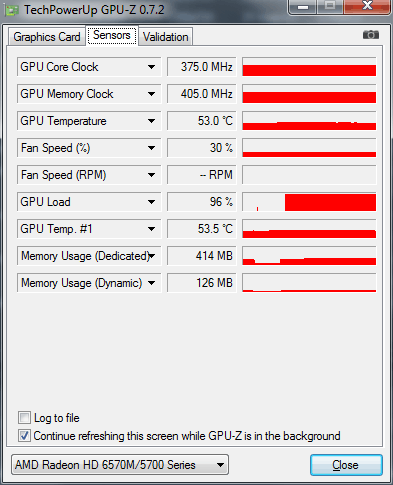
Загрузка GPU чипсета ATI Mobility Radeon HD 5730 составляет 97% и 352Мб бортовой видеопамяти. Ноутбук тестировался при работе от аккумулятора, поэтому графическое ядро / память работают на пониженных частотах: 375 / 810 МГц.
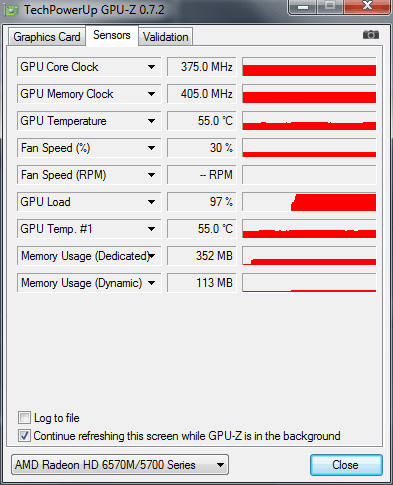
Итоговое время просчета: 1 минута и 55 секунд
(вкл/откл. MRQ при использовании GPU движка, не влияет на итогове время просчета).
При установленной галке Use Maximum Render Quality теперь нажимаем на кнопку: Queue.

Тактовые частоты процессора при работе от аккумулятора: 930МГц.

Запускаем AMEEncodingLog и смотрим итоговое время просчета: 5 минут и 14 секунд .

Повторяем тест, но уже при снятой галке Use Maximum Render Quality, нажимаем на кнопку: Queue.
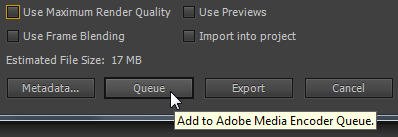
Итоговое время просчета: 1 минута и 17 секунд .

Теперь включим GPU движок в Adobe Media Encoder CC, запускаем программу Adobe Premiere Pro CC, нажимаем комбинацию клавиш: Ctrl + F12, выполняем Console > Console View и в поле Command вбиваем GPUSniffer, нажимаем Enter.
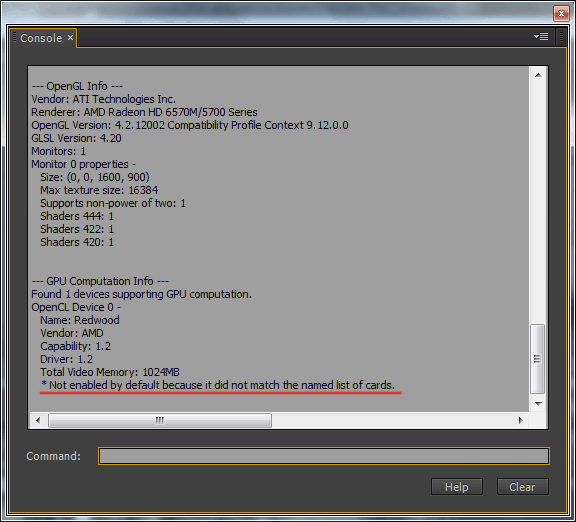
Выделяем и копируем имя в GPU Computation Info.
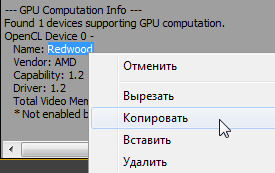
В директории программы Adobe Premiere Pro CC открываем документ opencl_supported_cards, и в алфавитном порядке вбиваем кодовое имя чипсета, Ctrl+S.
Нажимаем на кнопку: Queue, и получаем GPU ускорение просчета проекта Adobe Premiere Pro CC в Adobe Media Encoder CC.
Итоговое время: 1 минута и 55 секунд .

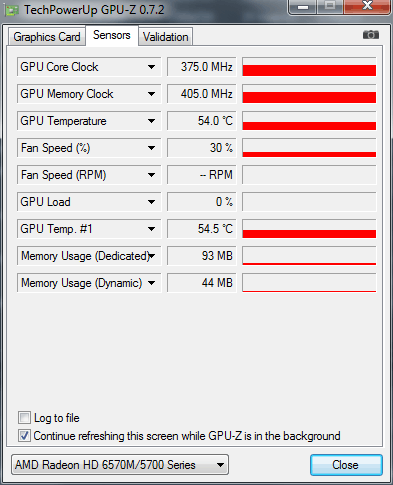
Подключаем ноутбук к розетке, и повторяем результаты просчетов. Queue, галка MRQ снята, без включения движка, загрузка оперативной памяти немного подросла:

Тактовые частоты процессора: 1.6ГГц при работе от розетки и включении режима: Высокая производительность.

Итоговое время: 46 секунд .

Включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL), как видно от сети ноутбучная видеокарта работает на своих базовых частотах, загрузка GPU в Adobe Media Encoder CC достигает 95%.
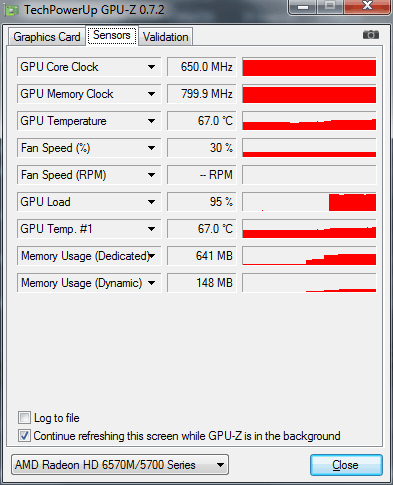
Итоговое время просчета, снизилось с 1 минуты 55 секунд , до 1 минуты и 5 секунд .

*Для визуализации в Adobe Media Encoder CC теперь используется графический процессор (GPU). Поддерживаются стандарты CUDA и
OpenCL. В Adobe Media Encoder CC, движок GPU используется для следующих процессов визуализации:
- Изменение четкости (от высокой к стандартной и наоборот).
- Фильтр временного кода.
- Преобразования формата пикселей.
- Расперемежение.
Если визуализируется проект Premiere Pro, в AME используются установки визуализации с GPU, заданные для этого проекта. При этом будут использованы все возможности визуализации с GPU, реализованные в Premiere Pro. Для визуализации проектов AME используется ограниченный набор возможностей визуализации с GPU.
Если последовательность визуализируется с использованием оригинальной поддержки, применяется настройка GPU из AME, настройка проекта игнорируется. В этом случае все возможности визуализации с GPU Premiere Pro используются напрямую в AME.
Если проект содержит VST сторонних производителей, используется настройка GPU проекта. Последовательность кодируется с помощью PProHeadless, как и в более ранних версиях AME. Если флажок Enable Native Premiere Pro Sequence Import (Разрешить импорт исходной последовательности Premiere Pro) снят, всегда используется PProHeadless и настройка GPU.
Читаем про скрытый раздел на системном диске ноутбука ASUS N71JQ.
Особенности архитектуры AMD/ATI Radeon
Это похоже на рождение новых биологических видов, когда при освоении сфер обитания живые существа эволюционируют для улучшения приспособленности к среде. Так и GPU, начав с ускорения растеризации и текстурирования треугольников, развили дополнительные способности по выполнению шейдерных программ для раскраски этих самых треугольников. И эти способности оказались востребованы и в неграфических вычислениях, где в ряде случаев дают значительный выигрыш в производительности по сравнению с традиционными решениями.
Проводим аналогии дальше - после долгой эволюции на суше млекопитающие проникли в море, где потеснили обычных морских обитателей. В конкурентной борьбе млекопитающие использовали как новые продвинутые способности, которые появились на земной поверхности, так и специально приобретенные для адаптации к жизни в воде. Точно так же GPU, основываясь на преимуществах архитектуры для 3D-графики, все больше и больше обзаводятся специальными функциональными возможностями, полезными для исполнения далеких от графики задач.
Итак, что же позволяет GPU претендовать на собственный сектор в сфере программ общего назначения? Микроархитектура GPU построена совсем иначе, чем у обычных CPU, и в ней изначально заложены определенные преимущества. Задачи графики предполагают независимую параллельную обработку данных, и GPU изначально мультипоточен. Но эта параллельность ему только в радость. Микроархитектура спроектирована так, чтобы эксплуатировать имеющееся в наличии большое количество нитей, требующих исполнения.
GPU состоит из нескольких десятков (30 для Nvidia GT200, 20 - для Evergreen, 16 - для Fermi) процессорных ядер, которые в терминологии Nvidia называются Streaming Multiprocessor, а в терминологии ATI - SIMD Engine. В рамках данной статьи мы будем называть их минипроцессорами, потому что они исполняют несколько сотен программных нитей и умеют почти все то же, что и обычный CPU, но все-таки не все.
Маркетинговые названия запутывают - в них, для пущей важности, указывают количество функциональных модулей, которые умеют вычитать и умножать: например, 320 векторных «cores» (ядер). Эти ядра больше похожи на зерна. Лучше представлять GPU как некий многоядерный процессор с большим количеством ядер, исполняющих одновременно множество нитей.
Каждый минипроцессор имеет локальную память, размером 16 KБ для GT200, 32 KБ - для Evergreen и 64 KБ - для Fermi (по сути, это программируемый L1 кэш). Она имеет сходное с кэшем первого уровня обычного CPU время доступа и выполняет аналогичные функции наибыстрейшей доставки данных к функциональным модулям. В архитектуре Fermi часть локальной памяти может быть сконфигурирована как обычный кэш. В GPU локальная память служит для быстрого обмена данными между исполняющимися нитями. Одна из обычных схем GPU-программы такова: в начале в локальную память загружаются данные из глобальной памяти GPU. Это просто обычная видеопамять, расположенная (как и системная память) отдельно от «своего» процессора - в случае видео она распаяна несколькими микросхемами на текстолите видеокарты. Далее несколько сотен нитей работают с этими данными в локальной памяти и записывают результат в глобальную память, после чего тот передается в CPU. В обязанность программиста входит написание инструкций загрузки и выгрузки данных из локальной памяти. По сути, это разбиение данных [конкретной задачи] для параллельной обработки. GPU поддерживает также инструкции атомарной записи/чтения в память, но они неэффективны и востребованы обычно на завершающем этапе для «склейки» результатов вычислений всех минипроцессоров.
Локальная память общая для всех исполняющихся в минипроцессоре нитей, поэтому, например, в терминологии Nvidia она даже называется shared, а термином local memory обозначается прямо противоположное, а именно: некая персональная область отдельной нити в глобальной памяти, видимая и доступная только ей. Но кроме локальной памяти в минипроцессоре есть ещё одна область памяти, во всех архитектурах примерно в четыре раза бо́льшая по объему. Она разделена поровну между всеми исполняющимися нитями, это регистры для хранения переменных и промежуточных результатов вычислений. На каждую нить приходится несколько десятков регистров. Точное количество зависит от того, сколько нитей исполняет минипроцессор. Это количество очень важно, так как латентность глобальной памяти очень велика, сотни тактов, и в отсутствие кэшей негде хранить промежуточные результаты вычислений.
И ещё одна важная черта GPU: «мягкая» векторность. Каждый минипроцессор обладает большим количеством вычислительных модулей (8 для GT200, 16 для Radeon и 32 для Fermi), но все они могут выполнять только одну и ту же инструкцию, с одним программным адресом. Операнды же при этом могут быть разные, у разных нитей свои. Например, инструкция сложить содержимое двух регистров : она одновременно выполняется всеми вычислительными устройствами, но регистры берутся разные. Предполагается, что все нити GPU-программы, осуществляя параллельную обработку данных, в целом движутся параллельным курсом по коду программы. Таким образом, все вычислительные модули загружаются равномерно. А если нити из-за ветвлений в программе разошлись в своем пути исполнения кода, то происходит так называемая сериализация. Тогда используются не все вычислительные модули, так как нити подают на исполнение различные инструкции, а блок вычислительных модулей может исполнять, как мы уже сказали, только инструкцию с одним адресом. И, разумеется, производительность при этом падает по отношению к максимальной.
Плюсом является то, что векторизация происходит полностью автоматически, это не программирование с использованием SSE, MMX и так далее. И GPU сам обрабатывает расхождения. Теоретически, можно вообще писать программы для GPU, не думая о векторной природе исполняющих модулей, но скорость такой программы будет не очень высокой. Минус заключается в большой ширине вектора. Она больше, чем номинальное количество функциональных модулей, и составляет 32 для GPU Nvidia и 64 для Radeon. Нити обрабатываются блоками соответствующего размера. Nvidia называет этот блок нитей термином warp, AMD - wave front, что одно и то же. Таким образом, на 16 вычислительных устройствах «волновой фронт» длиной 64 нити обрабатывается за четыре такта (при условии обычной длины инструкции). Автор предпочитает в данном случае термин warp, из-за ассоциации с морским термином warp, обозначающим связанный из скрученных веревок канат. Так и нити «скручиваются» и образуют цельную связку. Впрочем, «wave front» тоже может ассоциироваться с морем: инструкции так же прибывают к исполнительным устройствам, как волны одна за другой накатываются на берег.
Если все нити одинаково продвинулись в выполнении программы (находятся в одном месте) и, таким образом, исполняют одну инструкцию, то все прекрасно, но если нет - происходит замедление. В этом случае нити из одного warp или wave front находятся в различных местах программы, они разбиваются на группы нитей, имеющих одинаковое значение номера инструкции (иначе говоря, указателя инструкций (instruction pointer)). И по-прежнему выполняются в один момент времени только нити одной группы - все выполняют одинаковую инструкцию, но с различными операндами. В итоге warp исполняется во столько раз медленней, на сколько групп он разбит, а количество нитей в группе значения не имеет. Даже если группа состоит всего из одной нити, все равно она будет выполняться столько же времени, сколько полный warp. В железе это реализовано с помощью маскирования определенных нитей, то есть инструкции формально выполняются, но результаты их выполнения никуда не записываются и в дальнейшем не используются.
Хотя в каждый момент времени каждый минипроцессор (Streaming MultiProcessor или SIMD Engine) выполняет инструкции, принадлежащие только одному warp (связке нитей), он имеет несколько десятков активных варпов в исполняемом пуле. Выполнив инструкции одного варпа, минипроцессор исполняет не следующую по очереди инструкцию нитей данного варпа, а инструкции кого-нибудь другого варпа. Тот варп может быть в совершенно другом месте программы, это не будет влиять на скорость, так как только внутри варпа инструкции всех нитей обязаны быть одинаковыми для исполнения с полной скоростью.
В данном случае каждый из 20 SIMD Engine имеет четыре активных wave front, в каждом из которых 64 нити. Каждая нить обозначена короткой линией. Всего: 64×4×20=5120 нитей
Таким образом, учитывая, что каждый warp или wave front состоит из 32-64 нитей, минипроцессор имеет несколько сотен активных нитей, которые исполняются практически одновременно. Ниже мы увидим, какие архитектурные выгоды сулит такое большое количество параллельных нитей, но сначала рассмотрим, какие ограничения есть у составляющих GPU минипроцессоров.
Главное, что в GPU нет стека, где могли бы хранится параметры функций и локальные переменные. Из-за большого количества нитей для стека просто нет места на кристалле. Действительно, так как GPU одновременно выполняет порядка 10000 нитей, при размере стека одной нити в 100 КБ совокупный объем составит 1 ГБ, что равно стандартному объему всей видеопамяти. Тем более нет никакой возможности поместить стек сколько-нибудь существенного размера в самом ядре GPU. Например, если положить 1000 байт стека на нить, то только на один минипроцессор потребуется 1 МБ памяти, что почти в пять раз больше совокупного объема локальной памяти минипроцессора и памяти, отведенной на хранение регистров.
Поэтому в GPU-программе нет рекурсии, и с вызовами функций особенно не развернешься. Все функции непосредственно подставляются в код при компиляции программы. Это ограничивает область применения GPU задачами вычислительного типа. Иногда можно использовать ограниченную эмуляцию стека с использованием глобальной памяти для рекурсионных алгоритмов с известной небольшой глубиной итераций, но это нетипичное применение GPU. Для этого необходимо специально разрабатывать алгоритм, исследовать возможность его реализации без гарантии успешного ускорения по сравнению с CPU.
В Fermi впервые появилась возможность использовать виртуальные функции, но опять-таки их применение лимитировано отсутствием большого быстрого кэша для каждой нити. На 1536 нитей приходится 48 КБ или 16 КБ L1, то есть виртуальные функции в программе можно использовать относительно редко, иначе для стека также будет использоваться медленная глобальная память, что замедлит исполнение и, скорее всего, не принесет выгод по сравнению с CPU-вариантом.
Таким образом, GPU представляется в роли вычислительного сопроцессора, в который загружаются данные, они обрабатываются некоторым алгоритмом, и выдается результат.
Преимущества архитектуры
Но считает GPU очень быстро. И в этом ему помогает его высокая мультипоточность. Большое количество активных нитей позволяет отчасти скрыть большую латентность расположенной отдельно глобальной видеопамяти, составляющую порядка 500 тактов. Особенно хорошо она нивелируется для кода с высокой плотностью арифметических операций. Таким образом, не требуется дорогостоящая с точки зрения транзисторов иерархия кэшей L1-L2-L3. Вместо неё на кристалле можно разместить множество вычислительных модулей, обеспечив выдающуюся арифметическую производительность. А пока исполняются инструкции одной нити или варпа, остальные сотни нитей спокойно ждут своих данных.
В Fermi был введен кэш второго уровня размером около 1 МБ, но его нельзя сравнивать с кэшами современных процессоров, он больше предназначен для коммуникации между ядрами и различных программных трюков. Если его размер разделить между всеми десятками тысяч нитей, на каждую придется совсем ничтожный объем.
Но кроме латентности глобальной памяти, в вычислительном устройстве существует ещё множество латентностей, которые надо скрыть. Это латентность передачи данных внутри кристалла от вычислительных устройств к кэшу первого уровня, то есть локальной памяти GPU, и к регистрам, а также кэшу инструкций. Регистровый файл, как и локальная память, расположены отдельно от функциональных модулей, и скорость доступа к ним составляет примерно полтора десятка тактов. И опять-таки большое количество нитей, активных варпов, позволяет эффективно скрыть эту латентность. Причем общая полоса пропускания (bandwidth) доступа к локальной памяти всего GPU, с учетом количества составляющих его минипроцессоров, значительно больше, чем bandwidth доступа к кэшу первого уровня у современных CPU. GPU может переработать значительно больше данных в единицу времени.
Можно сразу сказать, что если GPU не будет обеспечен большим количеством параллельных нитей, то у него будет почти нулевая производительность, потому что он будет работать с тем же темпом, как будто полностью загружен, а выполнять гораздо меньший объем работы. Например, пусть вместо 10000 нитей останется всего одна: производительность упадет примерно в тысячу раз, ибо не только не все блоки будут загружены, но и скажутся все латентности.
Проблема сокрытия латентностей остра и для современных высокочастотных CPU, для её устранения используются изощренные способы - глубокая конвейеризация, внеочередное исполнение инструкций (out-of-order). Для этого требуются сложные планировщики исполнения инструкций, различные буферы и т. п., что занимает место на кристалле. Это все требуется для наилучшей производительности в однопоточном режиме.
Но для GPU все это не нужно, он архитектурно быстрее для вычислительных задач с большим количеством потоков. Зато он преобразует многопоточность в производительность, как философский камень превращает свинец в золото.
GPU изначально был приспособлен для оптимального исполнения шейдерных программ для пикселей треугольников, которые, очевидно, независимы и могут исполняться параллельно. И из этого состояния он эволюционировал путем добавления различных возможностей (локальной памяти и адресуемого доступа к видеопамяти, а также усложнения набора инструкций) в весьма мощное вычислительное устройство, которое все же может быть эффективно применено только для алгоритмов, допускающих высокопараллельную реализацию с использованием ограниченного объема локальной памяти.
Пример
Одна из самых классических задач для GPU - это задача вычисления взаимодействия N тел, создающих гравитационное поле. Но если нам, например, понадобится рассчитать эволюцию системы Земля-Луна-Солнце, то GPU нам плохой помощник: мало объектов. Для каждого объекта надо вычислить взаимодействия со всеми остальными объектами, а их всего два. В случае движения Солнечной системы со всеми планетами и их лунами (примерно пара сотен объектов) GPU все еще не слишком эффективен. Впрочем, и многоядерный процессор из-за высоких накладных расходов на управление потоками тоже не сможет проявить всю свою мощь, будет работать в однопоточном режиме. Но вот если требуется также рассчитать траектории комет и объектов пояса астероидов, то это уже задача для GPU, так как объектов достаточно, чтобы создать необходимое количество параллельных потоков расчета.
GPU также хорошо себя проявит, если необходимо рассчитать столкновение шаровых скоплений из сотен тысяч звезд.
Ещё одна возможность использовать мощность GPU в задаче N тел появляется, когда необходимо рассчитать множество отдельных задач, пусть и с небольшим количеством тел. Например, если требуется рассчитать варианты эволюции одной системы при различных вариантах начальных скоростей. Тогда эффективно использовать GPU удастся без проблем.
Детали микроархитектуры AMD Radeon
Мы рассмотрели базовые принципы организации GPU, они общие для видеоускорителей всех производителей, так как у них изначально была одна целевая задача - шейдерные программы. Тем не менее, производители нашли возможность разойтись в деталях микроархитектурной реализации. Хотя и CPU различных вендоров порой сильно отличаются, даже будучи совместимыми, как, например, Pentium 4 и Athlon или Core. Архитектура Nvidia уже достаточно широко известна, сейчас мы рассмотрим Radeon и выделим основные отличия в подходах этих вендоров.
Видеокарты AMD получили полноценную поддержку вычислений общего назначения начиная с семейства Evergreen, в котором также были впервые реализованы спецификации DirectX 11. Карточки семейства 47xx имеют ряд существенных ограничений, которые будут рассмотрены ниже.
Различия в размере локальной памяти (32 КБ у Radeon против 16 КБ у GT200 и 64 КБ у Fermi) в общем не принципиальны. Как и размер wave front в 64 нити у AMD против 32 нитей в warp у Nvidia. Практически любую GPU-программу можно легко переконфигурировать и настроить на эти параметры. Производительность может измениться на десятки процентов, но в случае с GPU это не так принципиально, ибо GPU-программа обычно работает в десять раз медленней, чем аналог для CPU, или в десять раз быстрее, или вообще не работает.
Более важным является использование AMD технологии VLIW (Very Long Instruction Word). Nvidia использует скалярные простые инструкции, оперирующие со скалярными регистрами. Её ускорители реализуют простой классический RISC. Видеокарточки AMD имеют такое же количество регистров, как GT200, но регистры векторные 128-битные. Каждая VLIW-инструкция оперирует несколькими четырехкомпонентными 32-битными регистрами, что напоминает SSE, но возможности VLIW гораздо шире. Это не SIMD (Single Instruction Multiple Data), как SSE - здесь инструкции для каждой пары операндов могут быть различными и даже зависимыми! Например, пусть компоненты регистра А называются a1, a2, a3, a4; у регистра B - аналогично. Можно вычислить с помощью одной инструкции, которая выполняется за один такт, например, число a1×b1+a2×b2+a3×b3+a4×b4 или двумерный вектор (a1×b1+a2×b2, a3×b3+a4×b4).
Это стало возможным благодаря более низкой частоте GPU, чем у CPU, и сильному уменьшению техпроцессов в последние годы. При этом не требуется никакого планировщика, почти все исполняется за такт.
Благодаря векторным инструкциям, пиковая производительность Radeon в числах одинарной точности очень высока и составляет уже терафлопы.
Один векторный регистр может вместо четырех чисел одинарной точности хранить одно число двойной точности. И одна VLIW-инструкция может либо сложить две пары чисел double, либо умножить два числа, либо умножить два числа и сложить с третьим. Таким образом, пиковая производительность в double примерно в пять раз ниже, чем во float. Для старших моделей Radeon она соответствует производительности Nvidia Tesla на новой архитектуре Fermi и гораздо выше, чем производительность в double карточек на архитектуре GT200. В потребительских видеокарточках Geforce на основе Fermi максимальная скорость double-вычислений была уменьшена в четыре раза.

Принципиальная схема работы Radeon. Представлен только один минипроцессор из 20 параллельно работающих
Производители GPU, в отличие от производителей CPU (прежде всего, x86-совместимых), не связаны вопросами совместимости. GPU-программа сначала компилируется в некий промежуточный код, а при запуске программы драйвер компилирует этот код в машинные инструкции, специфичные для конкретной модели. Как было описано выше, производители GPU воспользовались этим, придумав удобные ISA (Instruction Set Architecture) для своих GPU и изменяя их от поколения к поколению. Это в любом случае добавило какие-то проценты производительности из-за отсутствия (за ненадобностью) декодера. Но компания AMD пошла ещё дальше, придумав собственный формат расположения инструкций в машинном коде. Они расположены не последовательно (согласно листингу программы), а по секциям.
Сначала идет секция инструкций условных переходов, которые имеют ссылки на секции непрерывных арифметических инструкций, соответствующие различным ветвям переходов. Они называются VLIW bundles (связки VLIW-инструкций). В этих секциях содержатся только арифметические инструкции с данными из регистров или локальной памяти. Такая организация упрощает управление потоком инструкций и доставку их к исполнительным устройствам. Это тем более полезно, учитывая что VLIW-инструкции имеют сравнительно большой размер. Есть также секции для инструкций обращений к памяти.
| Секции инструкций условных переходов | ||||
|---|---|---|---|---|
| Секция 0 | Ветвление 0 | Ссылка на секцию №3 непрерывных арифметических инструкций | ||
| Секция 1 | Ветвление 1 | Ссылка на секцию №4 | ||
| Секция 2 | Ветвление 2 | Ссылка на секцию №5 | ||
| Секции непрерывных арифметических инструкций | ||||
| Секция 3 | VLIW-инструкция 0 | VLIW-инструкция 1 | VLIW-инструкция 2 | VLIW-инструкция 3 |
| Секция 4 | VLIW-инструкция 4 | VLIW-инструкция 5 | ||
| Секция 5 | VLIW-инструкция 6 | VLIW-инструкция 7 | VLIW-инструкция 8 | VLIW-инструкция 9 |
GPU обоих производителей (и Nvidia, и AMD) также обладают встроенными инструкциями быстрого вычисления за несколько тактов основных математических функций, квадратного корня, экспоненты, логарифмов, синусов и косинусов для чисел одинарной точности. Для этого есть специальные вычислительные блоки. Они «произошли» от необходимости реализации быстрой аппроксимации этих функций в геометрических шейдерах.
Если бы даже кто-то не знал, что GPU используются для графики, и ознакомился только с техническими характеристиками, то по этому признаку он мог бы догадаться, что эти вычислительные сопроцессоры произошли от видеоускорителей. Аналогично, по некоторым чертам морских млекопитающих ученые поняли, что их предки были сухопутными существами.
Но более явная черта, выдающая графическое происхождение устройства, это блоки чтения двумерных и трехмерных текстур с поддержкой билинейной интерполяции. Они широко используются в GPU-программах, так как обеспечивают ускоренное и упрощенное чтение массивов данных read-only. Одним из стандартных вариантов поведения GPU-приложения является чтение массивов исходных данных, обработка их в вычислительных ядрах и запись результата в другой массив, который передается далее обратно в CPU. Такая схема стандартна и распространена, потому что удобна для архитектуры GPU. Задачи, требующие интенсивно читать и писать в одну большую область глобальной памяти, содержащие, таким образом, зависимости по данным, трудно распараллелить и эффективно реализовать на GPU. Также их производительность будет сильно зависеть от латентности глобальной памяти, которая очень велика. А вот если задача описывается шаблоном «чтение данных - обработка - запись результата», то почти наверняка можно получить большой прирост от ее исполнения на GPU.
Для текстурных данных в GPU существует отдельная иерархия небольших кэшей первого и второго уровней. Она-то и обеспечивает ускорение от использования текстур. Эта иерархия изначально появилась в графических процессорах для того, чтобы воспользоваться локальностью доступа к текстурам: очевидно, после обработки одного пикселя для соседнего пикселя (с высокой вероятностью) потребуются близко расположенные данные текстуры. Но и многие алгоритмы обычных вычислений имеют сходный характер доступа к данным. Так что текстурные кэши из графики будут очень полезны.
Хотя размер кэшей L1-L2 в карточках Nvidia и AMD примерно сходен, что, очевидно, вызвано требованиями оптимальности с точки зрения графики игр, латентность доступа к этим кэшам существенно разнится. Латентность доступа у Nvidia больше, и текстурные кэши в Geforce в первую очередь помогают сократить нагрузку на шину памяти, а не непосредственно ускорить доступ к данным. Это не заметно в графических программах, но важно для программ общего назначения. В Radeon же латентность текстурного кэша ниже, зато выше латентность локальной памяти минипроцессоров. Можно привести такой пример: для оптимального перемножения матриц на карточках Nvidia лучше воспользоваться локальной памятью, загружая туда матрицу поблочно, а для AMD лучше положиться на низколатентный текстурный кэш, читая элементы матрицы по мере надобности. Но это уже достаточно тонкая оптимизация, и для уже принципиально переведенного на GPU алгоритма.
Это различие также проявляется в случае использования 3D-текстур. Один из первых бенчмарков вычислений на GPU, который показывал серьезное преимущество AMD, как раз и использовал 3D-текстуры, так как работал с трехмерным массивом данных. А латентность доступа к текстурам в Radeon существенно быстрее, и 3D-случай дополнительно более оптимизирован в железе.
Для получения максимальной производительности от железа различных фирм нужен некий тюнинг приложения под конкретную карточку, но он на порядок менее существенен, чем в принципе разработка алгоритма для архитектуры GPU.
Ограничения серии Radeon 47xx
В этом семействе поддержка вычислений на GPU неполна. Можно отметить три важных момента. Во-первых, нет локальной памяти, то есть она физически есть, но не обладает возможностью универсального доступа, требуемого современным стандартом GPU-программ. Она эмулируется программно в глобальной памяти, то есть её использование в отличие от полнофункционального GPU не принесет выгод. Второй момент - ограниченная поддержка различных инструкций атомарных операций с памятью и инструкций синхронизации. И третий момент - это довольно маленький размер кэша инструкций: начиная с некоторого размера программы происходит замедление скорости в разы. Есть и другие мелкие ограничения. Можно сказать, только идеально подходящие для GPU программы будут хорошо работать на этой видеокарточке. Пусть в простых тестовых программах, которые оперируют только с регистрами, видеокарточка может показывать хороший результат в Gigaflops, что-то сложное эффективно запрограммировать под нее проблематично.
Преимущества и недостатки Evergreen
Если сравнить продукты AMD и Nvidia, то, с точки зрения вычислений на GPU, серия 5xxx выглядит, как очень мощный GT200. Такой мощный, что по пиковой производительности превосходит Fermi примерно в два c половиной раза. Особенно после того, как параметры новых видеокарточек Nvidia были урезаны, сокращено количество ядер. Но появление в Fermi кэша L2 упрощает реализацию на GPU некоторых алгоритмов, таким образом расширяя область применения GPU. Что интересно, для хорошо оптимизированных под прошлое поколение GT200 CUDA-программ архитектурные нововведения Fermi зачастую ничего не дали. Они ускорились пропорционально увеличению количества вычислительных модулей, то есть менее чем в два раза (для чисел одинарной точности), а то и ещё меньше, ибо ПСП памяти не увеличилась (или по другим причинам).
И в хорошо ложащихся на архитектуру GPU задачах, имеющих выраженную векторную природу (например, перемножении матриц), Radeon показывает относительно близкую к теоретическому пику производительность и обгоняет Fermi. Не говоря уже о многоядерных CPU. Особенно в задачах с числами с одинарной точностью.
Но Radeon имеет меньшую площадь кристалла, меньшее тепловыделение, энергопотребление, больший выход годных и, соответственно, меньшую стоимость. И непосредственно в задачах 3D-графики выигрыш Fermi, если он вообще есть, гораздо меньше разницы в площади кристалла. Во многом это объясняется тем, что вычислительная архитектура Radeon с 16 вычислительными устройствами на минипроцессор, размером wave front в 64 нити и векторными VLIW-инструкциями прекрасна для его главной задачи - вычисления графических шейдеров. Для абсолютного большинства обычных пользователей производительность в играх и цена приоритетны.
С точки зрения профессиональных, научных программ, архитектура Radeon обеспечивает лучшее соотношение цена-производительность, производительность на ватт и абсолютную производительность в задачах, которые в принципе хорошо соответствуют архитектуре GPU, допускают параллелизацию и векторизацию.
Например, в полностью параллельной легко векторизуемой задаче подбора ключей Radeon в несколько раз быстрее Geforce и в несколько десятков раз быстрее CPU.
Это соответствует общей концепции AMD Fusion, согласно которой GPU должны дополнять CPU, и в будущем интегрироваться в само ядро CPU, как ранее математический сопроцессор был перенесен с отдельного кристалла в ядро процессора (это случилось лет двадцать назад, перед появлением первых процессоров Pentium). GPU будет интегрированным графическим ядром и векторным сопроцессором для потоковых задач.
В Radeon используется хитрая техника смешения инструкций из различных wave front при исполнении функциональными модулями. Это легко сделать, так как инструкции полностью независимы. Принцип аналогичен конвейерному исполнению независимых инструкций современными CPU. По всей видимости, это дает возможность эффективно исполнять сложные, занимающие много байт, векторные VLIW-инструкции. В CPU для этого требуется сложный планировщик для выявления независимых инструкций или использование технологии Hyper-Threading, которая также снабжает CPU заведомо независимыми инструкциями из различных потоков.
| такт 0 | такт 1 | такт 2 | такт 3 | такт 4 | такт 5 | такт 6 | такт 7 | VLIW-модуль | |
| wave front 0 | wave front 1 | wave front 0 | wave front 1 | wave front 0 | wave front 1 | wave front 0 | wave front 1 | ||
|---|---|---|---|---|---|---|---|---|---|
| → | инстр. 0 | инстр. 0 | инстр. 16 | инстр. 16 | инстр. 32 | инстр. 32 | инстр. 48 | инстр. 48 | VLIW0 |
| → | инстр. 1 | … | … | … | … | … | … | … | VLIW1 |
| → | инстр. 2 | … | … | … | … | … | … | … | VLIW2 |
| → | инстр. 3 | … | … | … | … | … | … | … | VLIW3 |
| → | инстр. 4 | … | … | … | … | … | … | … | VLIW4 |
| → | инстр. 5 | … | … | … | … | … | … | … | VLIW5 |
| → | инстр. 6 | … | … | … | … | … | … | … | VLIW6 |
| → | инстр. 7 | … | … | … | … | … | … | … | VLIW7 |
| → | инстр. 8 | … | … | … | … | … | … | … | VLIW8 |
| → | инстр. 9 | … | … | … | … | … | … | … | VLIW9 |
| → | инстр. 10 | … | … | … | … | … | … | … | VLIW10 |
| → | инстр. 11 | … | … | … | … | … | … | … | VLIW11 |
| → | инстр. 12 | … | … | … | … | … | … | … | VLIW12 |
| → | инстр. 13 | … | … | … | … | … | … | … | VLIW13 |
| → | инстр. 14 | … | … | … | … | … | … | … | VLIW14 |
| → | инстр. 15 | … | … | … | … | … | … | … | VLIW15 |
128 инструкций двух wave front, каждый из которых состоит из 64 операций, исполняются 16 VLIW-модулями за восемь тактов. Происходит чередование, и каждый модуль в реальности имеет два такта на исполнение целой инструкции при условии, что он на втором такте начнет выполнять новую параллельно. Вероятно, это помогает быстро исполнить VLIW-инструкцию типа a1×a2+b1×b2+c1×c2+d1×d2, то есть исполнить восемь таких инструкций за восемь тактов. (Формально получается, одну за такт.)
В Nvidia, по-видимому, такой технологии нет. И в отсутствие VLIW, для высокой производительности с использованием скалярных инструкций требуется высокая частота работы, что автоматически повышает тепловыделение и предъявляет высокие требования к технологическому процессу (чтобы заставить работать схему на более высокой частоте).
Недостатком Radeon с точки зрения GPU-вычислений является большая нелюбовь к ветвлениям. GPU вообще не жалуют ветвления из-за вышеописанной технологии выполнения инструкций: сразу группой нитей с одним программным адресом. (Кстати, такая техника называется SIMT: Single Instruction - Multiple Threads (одна инструкция - много нитей), по аналогии с SIMD, где одна инструкция выполняет одну операцию с различными данными.) Однако Radeon ветвления не любят особенно: это вызвано бо́льшим размером связки нитей. Понятно, что если программа не полностью векторная, то чем больше размер warp или wave front, тем хуже, так как при расхождении в пути по программе соседних нитей образуется больше групп, которые необходимо исполнять последовательно (сериализованно). Допустим, все нити разбрелись, тогда в случае размера warp в 32 нити программа будет работать в 32 раза медленней. А в случае размера 64, как в Radeon, - в 64 раза медленней.
Это заметное, но не единственное проявление «неприязни». В видеокарточках Nvidia каждый функциональный модуль, иначе называемый CUDA core, имеет специальный блок обработки ветвлений. А в видеокартах Radeon на 16 вычислительных модулей - всего два блока управления ветвлениями (они выведены из домена арифметических блоков). Так что даже простая обработка инструкции условного перехода, пусть её результат и одинаков для всех нитей в wave front, занимает дополнительное время. И скорость проседает.
Компания AMD производит к тому же и CPU. Они полагают, что для программ с большим количеством ветвлений все равно лучше подходит CPU, а GPU предназначен для чисто векторных программ.
Так что Radeon предоставляет в целом меньше возможностей для эффективного программирования, но обеспечивает лучшее соотношение цена-производительность во многих случаях. Другими словами, программ, которые можно эффективно (с пользой) перевести с CPU на Radeon, меньше, чем программ, эффективно работающих на Fermi. Но зато те, которые эффективно перенести можно, будут работать на Radeon эффективнее во многих смыслах.
API для GPU-вычислений
Сами технические спецификации Radeon смотрятся привлекательно, пусть и не стоит идеализировать и абсолютизировать вычисления на GPU. Но не менее важно для производительности программное обеспечение, необходимое для разработки и выполнения GPU-программы - компиляторы с языка высокого уровня и run-time, то есть драйвер, который осуществляет взаимодействие между частью программы, работающей на CPU, и непосредственно GPU. Оно даже более важно, чем в случае CPU: для CPU не нужен драйвер, который будет осуществлять менеджмент передачи данных, и с точки зрения компилятора GPU более привередлив. Например, компилятор должен обойтись минимальным количеством регистров для хранения промежуточных результатов вычислений, а также аккуратно встраивать вызовы функций, опять-таки используя минимум регистров. Ведь чем меньше регистров использует нить, тем больше нитей можно запустить и тем полнее нагрузить GPU, лучше скрывая время доступа к памяти.
И вот программная поддержка продуктов Radeon пока отстает от развития железа. (В отличие от ситуации с Nvidia, где откладывался выпуск железа, и продукт вышел в урезанном виде.) Ещё совсем недавно OpenCL-компилятор производства AMD имел статус бета, со множеством недоработок. Он слишком часто генерил ошибочный код либо отказывался компилировать код из правильного исходного текста, либо сам выдавал ошибку работы и зависал. Только в конце весны вышел релиз с высокой работоспособностью. Он тоже не лишен ошибок, но их стало значительно меньше, и они, как правило, возникают на боковых направлениях, когда пытаются запрограммировать что-то на грани корректности. Например, работают с типом uchar4, который задает 4-байтовую четырехкомпонентную переменную. Этот тип есть в спецификациях OpenCL, но работать с ним на Radeon не стоит, ибо регистры-то 128-битные: те же четыре компоненты, но 32-битные. А такая переменная uchar4 все равно займет целый регистр, только еще потребуются дополнительные операции упаковки и доступа к отдельным байтовым компонентам. Компилятор не должен иметь никаких ошибок, но компиляторов без недочетов не бывает. Даже Intel Compiler после 11 версий имеет ошибки компиляции. Выявленные ошибки исправлены в следующем релизе, который выйдет ближе к осени.
Но есть ещё множество вещей, требующих доработки. Например, до сих пор стандартный GPU-драйвер для Radeon не имеет поддержки GPU-вычислений с использованием OpenCL. Пользователь должен загружать и устанавливать дополнительный специальный пакет.
Но самое главное - это отсутствие каких бы то ни было библиотек функций. Для вещественных чисел двойной точности нет даже синуса, косинуса и экспоненты. Что ж, для сложения-умножения матриц этого не требуется, но если вы хотите запрограммировать что-то более сложное, надо писать все функции с нуля. Или ждать нового релиза SDK. В скором времени должна выйти ACML (AMD Core Math Library) для GPU-семейства Evergreen с поддержкой основных матричных функций.
На данный момент, по мнению автора статьи, реальным для программирования видеокарт Radeon видится использование API Direct Compute 5.0, естественно учитывая ограничения: ориентацию на платформу Windows 7 и Windows Vista. У Microsoft большой опыт в создании компиляторов, и можно ожидать полностью работоспособный релиз очень скоро, Microsoft напрямую в этом заинтересована. Но Direct Compute ориентирован на нужды интерактивных приложений: что-то посчитать и сразу же визуализировать результат - например, течение жидкости по поверхности. Это не значит, что его нельзя использовать просто для расчетов, но это не его естественное предназначение. Скажем, Microsoft не планирует добавлять в Direct Compute библиотечные функции - как раз те, которых нет на данный момент у AMD. То есть то, что сейчас можно эффективно посчитать на Radeon - некоторые не слишком изощренные программы, - можно реализовать и на Direct Compute, который гораздо проще OpenCL и должен быть стабильнее. Плюс, он полностью портабельный, будет работать и на Nvidia, и на AMD, так что компилировать программу придется только один раз, в то время как реализации OpenCL SDK компаний Nvidia и AMD не совсем совместимы. (В том смысле, что если разработать OpenCL-программу на системе AMD с использованием AMD OpenCL SDK, она может не пойти так просто на Nvidia. Возможно, потребуется компилировать тот же текст с использованием Nvidia SDK. И, разумеется, наоборот.)
Потом, в OpenCL много избыточной функциональности, так как OpenCL задуман как универсальный язык программирования и API для широкого круга систем. И GPU, и CPU, и Cell. Так что на случай, если надо просто написать программу для типичной пользовательской системы (процессор плюс видеокарта), OpenCL не представляется, так сказать, «высокопродуктивным». У каждой функции десять параметров, и девять из них должны быть установлены в 0. А для того, чтобы установить каждый параметр, надо вызывать специальную функцию, у которой тоже есть параметры.
И самый главный текущий плюс Direct Compute - пользователю не надо устанавливать специальный пакет: все, что необходимо, уже есть в DirectX 11.
Проблемы развития GPU-вычислений
Если взять сферу персональных компьютеров, то ситуация такова: существует не так много задач, для которых требуется большая вычислительная мощность и сильно не хватает обычного двухъядерного процессора. Как будто бы из моря на сушу вылезли большие прожорливые, но неповоротливые чудовища, а на суше-то и есть почти нечего. И исконные обители земной поверхности уменьшаются в размерах, учатся меньше потреблять, как всегда бывает при дефиците природных ресурсов. Если бы сейчас была такая же потребность в производительности, как 10-15 лет назад, GPU-вычисления приняли бы на ура. А так проблемы совместимости и относительной сложности GPU-программирования выходят на первый план. Лучше написать программу, которая работала бы на всех системах, чем программу, которая работает быстро, но запускается только на GPU.
Несколько лучше перспективы GPU с точки зрения использования в профессиональных приложениях и секторе рабочих станций, так как там больше потребности в производительности. Появляются плагины для 3D-редакторов с поддержкой GPU: например, для рендеринга с помощью трассировки лучей - не путать с обычным GPU-рендеренгом! Что-то появляется и для 2D-редакторов и редакторов презентаций, с ускорением создания сложных эффектов. Программы обработки видео также постепенно обзаводятся поддержкой GPU. Вышеприведенные задачи в виду своей параллельной сущности хорошо ложатся на архитектуру GPU, но сейчас создана очень большая база кода, отлаженного, оптимизированного под все возможности CPU, так что потребуется время, чтобы появились хорошие GPU-реализации.
В этом сегменте проявляются и такие слабые стороны GPU, как ограниченный объем видеопамяти - примерно в 1 ГБ для обычных GPU. Одним из главных факторов, снижающих производительность GPU-программ, является необходимость обмена данными между CPU и GPU по медленной шине, а из-за ограниченного объема памяти приходится передавать больше данных. И тут перспективной смотрится концепция AMD по совмещению GPU и CPU в одном модуле: можно пожертвовать высокой пропускной способностью графической памяти ради легкого и простого доступа к общей памяти, к тому же с меньшей латентностью. Эта высокая ПСП нынешней видеопамяти DDR5 гораздо больше востребована непосредственно графическими программами, чем большинством программ GPU-вычислений. Вообще, общая память GPU и CPU просто существенно расширит область применения GPU, сделает возможным использование его вычислительных возможностей в небольших подзадачах программ.
И больше всего GPU востребованы в сфере научных вычислений. Уже построено несколько суперкомпьютеров на базе GPU, которые показывают очень высокий результат в тесте матричных операций. Научные задачи так многообразны и многочисленны, что всегда находится множество, которое прекрасно ложится на архитектуру GPU, для которого использование GPU позволяет легко получить высокую производительность.
Если среди всех задач современных компьютеров выбрать одну, то это будет компьютерная графика - изображение мира, в котором мы живем. И оптимальная для этой цели архитектура не может быть плохой. Это настолько важная и фундаментальная задача, что специально разработанное для неё железо должно нести в себе универсальность и быть оптимальным для различных задач. Тем более что видеокарточки успешно эволюционируют.






